Visão geral da arquitetura do Milvus
Construído com base em bibliotecas populares de pesquisa vetorial, incluindo Faiss, HNSW, DiskANN, SCANN e outras, o Milvus foi concebido para pesquisa por semelhança em conjuntos de dados vectoriais densos contendo milhões, milhares de milhões ou mesmo triliões de vectores. Antes de prosseguir, familiarize-se com os princípios básicos da recuperação por incorporação.
O Milvus também suporta a fragmentação de dados, a ingestão de dados em fluxo contínuo, o esquema dinâmico, a pesquisa que combina dados vectoriais e escalares, a pesquisa multi-vetorial e híbrida, o vetor esparso e muitas outras funções avançadas. A plataforma oferece desempenho a pedido e pode ser optimizada para se adaptar a qualquer cenário de recuperação de incorporação. Recomendamos a implantação do Milvus usando o Kubernetes para obter disponibilidade e elasticidade ideais.
O Milvus adopta uma arquitetura de armazenamento partilhado com desagregação do armazenamento e da computação e escalabilidade horizontal para os seus nós de computação. Seguindo o princípio da desagregação do plano de dados e do plano de controlo, o Milvus é composto por quatro camadas: camada de acesso, serviço coordenador, nó de trabalho e armazenamento. Estas camadas são mutuamente independentes quando se trata de escalonamento ou de recuperação de desastres.
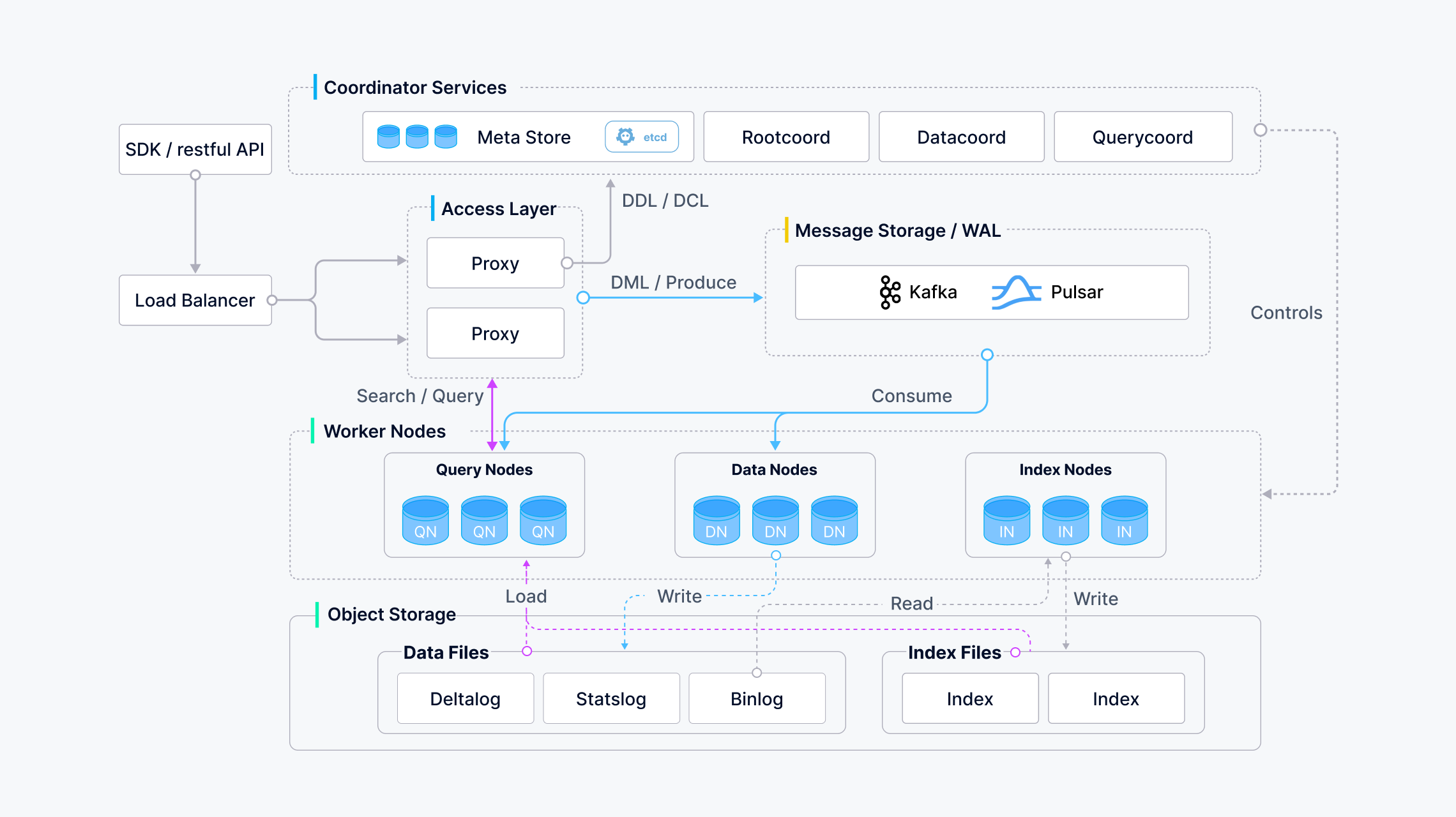 Diagrama de arquitetura
Diagrama de arquitetura
De acordo com a figura, as interfaces podem ser classificadas nas seguintes categorias:
- DDL / DCL: createCollection / createPartition / dropCollection / dropPartition / hasCollection / hasPartition
- DML / Produce: insert / delete / upsert
- DQL: pesquisa / consulta
O que se segue
- Saiba mais sobre a desagregação de computação/armazenamento em Milvus
- Saiba mais sobre os principais componentes do Milvus.