![]()
Hybrid Search with Milvus
If you want to experience the final effect of this tutorial, you can go directly to https://demos.milvus.io/hybrid-search/
In this tutorial, we will demonstrate how to conduct hybrid search with Milvus and BGE-M3 model. BGE-M3 model can convert text into dense and sparse vectors. Milvus supports storing both types of vectors in one collection, allowing for hybrid search that enhances the result relevance.
Milvus supports Dense, Sparse, and Hybrid retrieval methods:
- Dense Retrieval: Utilizes semantic context to understand the meaning behind queries.
- Sparse Retrieval: Emphasizes keyword matching to find results based on specific terms, equivalent to full-text search.
- Hybrid Retrieval: Combines both Dense and Sparse approaches, capturing the full context and specific keywords for comprehensive search results.
By integrating these methods, the Milvus Hybrid Search balances semantic and lexical similarities, improving the overall relevance of search outcomes. This notebook will walk through the process of setting up and using these retrieval strategies, highlighting their effectiveness in various search scenarios.
Dependencies and Environment
$ pip install --upgrade pymilvus "pymilvus[model]"
Download Dataset
To demonstrate search, we need a corpus of documents. Let’s use the Quora Duplicate Questions dataset and place it in the local directory.
Source of the dataset: First Quora Dataset Release: Question Pairs
# Run this cell to download the dataset
$ wget http://qim.fs.quoracdn.net/quora_duplicate_questions.tsv
Load and Prepare Data
We will load the dataset and prepare a small corpus for search.
import pandas as pd
file_path = "quora_duplicate_questions.tsv"
df = pd.read_csv(file_path, sep="\t")
questions = set()
for _, row in df.iterrows():
obj = row.to_dict()
questions.add(obj["question1"][:512])
questions.add(obj["question2"][:512])
if len(questions) > 500: # Skip this if you want to use the full dataset
break
docs = list(questions)
# example question
print(docs[0])
What is the strongest Kevlar cord?
Use BGE-M3 Model for Embeddings
The BGE-M3 model can embed texts as dense and sparse vectors.
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
dense_dim = ef.dim["dense"]
# Generate embeddings using BGE-M3 model
docs_embeddings = ef(docs)
Fetching 30 files: 100%|██████████| 30/30 [00:00<00:00, 302473.85it/s]
Inference Embeddings: 100%|██████████| 32/32 [01:59<00:00, 3.74s/it]
Setup Milvus Collection and Index
We will set up the Milvus collection and create indices for the vector fields.
- Setting the uri as a local file, e.g. "./milvus.db", is the most convenient method, as it automatically utilizes Milvus Lite to store all data in this file.
- If you have large scale of data, say more than a million vectors, you can set up a more performant Milvus server on Docker or Kubernetes. In this setup, please use the server uri, e.g.http://localhost:19530, as your uri.
- If you want to use Zilliz Cloud, the fully managed cloud service for Milvus, adjust the uri and token, which correspond to the Public Endpoint and API key in Zilliz Cloud.
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
# Connect to Milvus given URI
connections.connect(uri="./milvus.db")
# Specify the data schema for the new Collection
fields = [
# Use auto generated id as primary key
FieldSchema(
name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100
),
# Store the original text to retrieve based on semantically distance
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512),
# Milvus now supports both sparse and dense vectors,
# we can store each in a separate field to conduct hybrid search on both vectors
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=dense_dim),
]
schema = CollectionSchema(fields)
# Create collection (drop the old one if exists)
col_name = "hybrid_demo"
if utility.has_collection(col_name):
Collection(col_name).drop()
col = Collection(col_name, schema, consistency_level="Bounded")
# To make vector search efficient, we need to create indices for the vector fields
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
col.create_index("sparse_vector", sparse_index)
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
col.create_index("dense_vector", dense_index)
col.load()
Insert Data into Milvus Collection
Insert documents and their embeddings into the collection.
# For efficiency, we insert 50 records in each small batch
for i in range(0, len(docs), 50):
batched_entities = [
docs[i : i + 50],
docs_embeddings["sparse"][i : i + 50],
docs_embeddings["dense"][i : i + 50],
]
col.insert(batched_entities)
print("Number of entities inserted:", col.num_entities)
Number of entities inserted: 502
Enter Your Search Query
# Enter your search query
query = input("Enter your search query: ")
print(query)
# Generate embeddings for the query
query_embeddings = ef([query])
# print(query_embeddings)
How to start learning programming?
Run the Search
We will first prepare some helpful functions to run the search:
dense_search: only search across dense vector fieldsparse_search: only search across sparse vector fieldhybrid_search: search across both dense and vector fields with a weighted reranker
from pymilvus import (
AnnSearchRequest,
WeightedRanker,
)
def dense_search(col, query_dense_embedding, limit=10):
search_params = {"metric_type": "IP", "params": {}}
res = col.search(
[query_dense_embedding],
anns_field="dense_vector",
limit=limit,
output_fields=["text"],
param=search_params,
)[0]
return [hit.get("text") for hit in res]
def sparse_search(col, query_sparse_embedding, limit=10):
search_params = {
"metric_type": "IP",
"params": {},
}
res = col.search(
[query_sparse_embedding],
anns_field="sparse_vector",
limit=limit,
output_fields=["text"],
param=search_params,
)[0]
return [hit.get("text") for hit in res]
def hybrid_search(
col,
query_dense_embedding,
query_sparse_embedding,
sparse_weight=1.0,
dense_weight=1.0,
limit=10,
):
dense_search_params = {"metric_type": "IP", "params": {}}
dense_req = AnnSearchRequest(
[query_dense_embedding], "dense_vector", dense_search_params, limit=limit
)
sparse_search_params = {"metric_type": "IP", "params": {}}
sparse_req = AnnSearchRequest(
[query_sparse_embedding], "sparse_vector", sparse_search_params, limit=limit
)
rerank = WeightedRanker(sparse_weight, dense_weight)
res = col.hybrid_search(
[sparse_req, dense_req], rerank=rerank, limit=limit, output_fields=["text"]
)[0]
return [hit.get("text") for hit in res]
Let’s run three different searches with defined functions:
dense_results = dense_search(col, query_embeddings["dense"][0])
sparse_results = sparse_search(col, query_embeddings["sparse"][[0]])
hybrid_results = hybrid_search(
col,
query_embeddings["dense"][0],
query_embeddings["sparse"][[0]],
sparse_weight=0.7,
dense_weight=1.0,
)
Display Search Results
To display the results for Dense, Sparse, and Hybrid searches, we need some utilities to format the results.
def doc_text_formatting(ef, query, docs):
tokenizer = ef.model.tokenizer
query_tokens_ids = tokenizer.encode(query, return_offsets_mapping=True)
query_tokens = tokenizer.convert_ids_to_tokens(query_tokens_ids)
formatted_texts = []
for doc in docs:
ldx = 0
landmarks = []
encoding = tokenizer.encode_plus(doc, return_offsets_mapping=True)
tokens = tokenizer.convert_ids_to_tokens(encoding["input_ids"])[1:-1]
offsets = encoding["offset_mapping"][1:-1]
for token, (start, end) in zip(tokens, offsets):
if token in query_tokens:
if len(landmarks) != 0 and start == landmarks[-1]:
landmarks[-1] = end
else:
landmarks.append(start)
landmarks.append(end)
close = False
formatted_text = ""
for i, c in enumerate(doc):
if ldx == len(landmarks):
pass
elif i == landmarks[ldx]:
if close:
formatted_text += "</span>"
else:
formatted_text += "<span style='color:red'>"
close = not close
ldx = ldx + 1
formatted_text += c
if close is True:
formatted_text += "</span>"
formatted_texts.append(formatted_text)
return formatted_texts
Then we can display search results in text with highlights:
from IPython.display import Markdown, display
# Dense search results
display(Markdown("**Dense Search Results:**"))
formatted_results = doc_text_formatting(ef, query, dense_results)
for result in dense_results:
display(Markdown(result))
# Sparse search results
display(Markdown("\n**Sparse Search Results:**"))
formatted_results = doc_text_formatting(ef, query, sparse_results)
for result in formatted_results:
display(Markdown(result))
# Hybrid search results
display(Markdown("\n**Hybrid Search Results:**"))
formatted_results = doc_text_formatting(ef, query, hybrid_results)
for result in formatted_results:
display(Markdown(result))
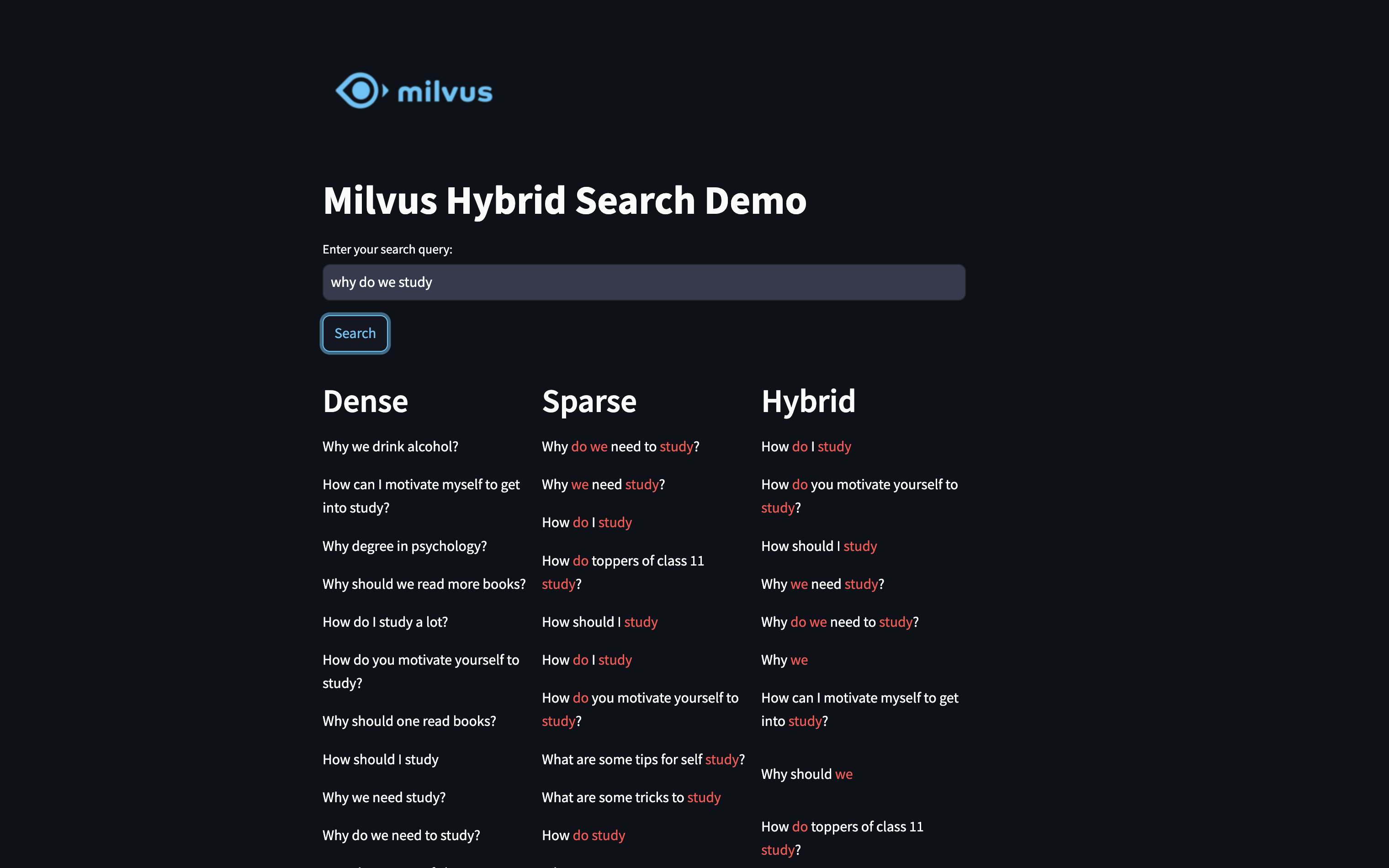
Dense Search Results:
What’s the best way to start learning robotics?
How do I learn a computer language like java?
How can I get started to learn information security?
What is Java programming? How To Learn Java Programming Language ?
How can I learn computer security?
What is the best way to start robotics? Which is the best development board that I can start working on it?
How can I learn to speak English fluently?
What are the best ways to learn French?
How can you make physics easy to learn?
How do we prepare for UPSC?
Sparse Search Results:
What is Java programming? How To Learn Java Programming Language ?
What’s the best way to start learning robotics?
What is the alternative to machine learning?
How do I create a new Terminal and new shell in Linux using C programming?
How do I create a new shell in a new terminal using C programming (Linux terminal)?
Which business is better to start in Hyderabad?
Which business is good start up in Hyderabad?
What is the best way to start robotics? Which is the best development board that I can start working on it?
What math does a complete newbie need to understand algorithms for computer programming? What books on algorithms are suitable for a complete beginner?
How do you make life suit you and stop life from abusing you mentally and emotionally?
Hybrid Search Results:
What is the best way to start robotics? Which is the best development board that I can start working on it?
What is Java programming? How To Learn Java Programming Language ?
What’s the best way to start learning robotics?
How do we prepare for UPSC?
How can you make physics easy to learn?
What are the best ways to learn French?
How can I learn to speak English fluently?
How can I learn computer security?
How can I get started to learn information security?
How do I learn a computer language like java?
What is the alternative to machine learning?
How do I create a new Terminal and new shell in Linux using C programming?
How do I create a new shell in a new terminal using C programming (Linux terminal)?
Which business is better to start in Hyderabad?
Which business is good start up in Hyderabad?
What math does a complete newbie need to understand algorithms for computer programming? What books on algorithms are suitable for a complete beginner?
How do you make life suit you and stop life from abusing you mentally and emotionally?
Quick Deploy
To learn about how to start an online demo with this tutorial, please refer to the example application.