Come migliorare le prestazioni della pipeline RAG
Con la crescente popolarità delle applicazioni di Retrieval Augmented Generation(RAG), cresce la preoccupazione di migliorarne le prestazioni. Questo articolo presenta tutti i modi possibili per ottimizzare le pipeline RAG e fornisce le relative illustrazioni per aiutarvi a comprendere rapidamente le principali strategie di ottimizzazione RAG.
È importante notare che forniremo solo un'esplorazione di alto livello di queste strategie e tecniche, concentrandoci su come si integrano in un sistema RAG. Tuttavia, non ci addentreremo in dettagli intricati né vi guideremo nell'implementazione passo dopo passo.
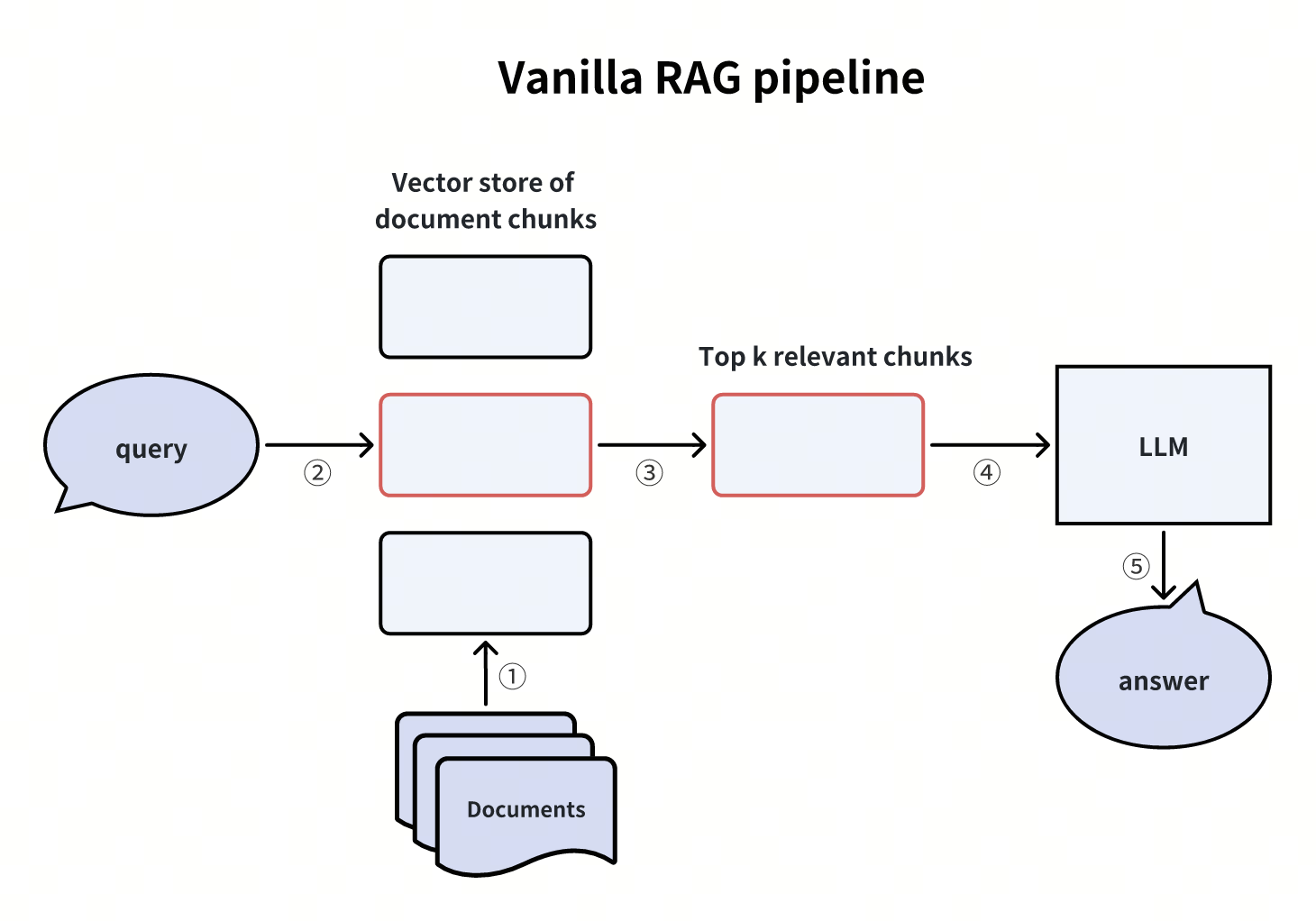
Una pipeline RAG standard
Il diagramma seguente mostra la pipeline RAG vanilla più semplice. Innanzitutto, i pezzi di documento vengono caricati in un archivio vettoriale (come Milvus o Zilliz cloud). Quindi, l'archivio vettoriale recupera i Top-K chunk più rilevanti relativi alla query. Questi pezzi rilevanti vengono poi iniettati nel prompt contestuale dell'LLM, che infine restituisce la risposta finale.
Vari tipi di tecniche di miglioramento delle RAG
Possiamo classificare diversi approcci di miglioramento delle RAG in base al loro ruolo nelle fasi della pipeline delle RAG.
- Miglioramento della query: Modifica e manipolazione del processo di interrogazione dell'input della RAG per esprimere o elaborare meglio l'intento dell'interrogazione.
- Miglioramento dell'indicizzazione: Ottimizzazione della creazione di indici di chunking utilizzando tecniche come il multi-chunking, l'indicizzazione step-wise o l'indicizzazione multi-way.
- Miglioramento del reperimento: Applicazione di tecniche e strategie di ottimizzazione durante il processo di recupero.
- Miglioramento del generatore: Regolazione e ottimizzazione dei prompt durante l'assemblaggio dei prompt per il LLM per fornire risposte migliori.
- Miglioramento della pipeline RAG: Commutazione dinamica dei processi all'interno dell'intera pipeline RAG, compreso l'utilizzo di agenti o strumenti per ottimizzare i passaggi chiave della pipeline RAG.
In seguito, verranno presentati metodi specifici per ciascuna di queste categorie.
Miglioramento delle query
Esploriamo quattro metodi efficaci per migliorare l'esperienza di interrogazione: Domande ipotetiche, Incorporamenti di documenti ipotetici, Sub-Query e Prompt di ritorno.
Creare domande ipotetiche
La creazione di domande ipotetiche prevede l'utilizzo di un LLM per generare domande multiple che gli utenti potrebbero porre sul contenuto di ogni frammento di documento. Prima che la domanda reale dell'utente raggiunga l'LLM, l'archivio vettoriale recupera le domande ipotetiche più rilevanti relative alla domanda reale, insieme ai corrispondenti chunk di documenti, e le inoltra all'LLM.
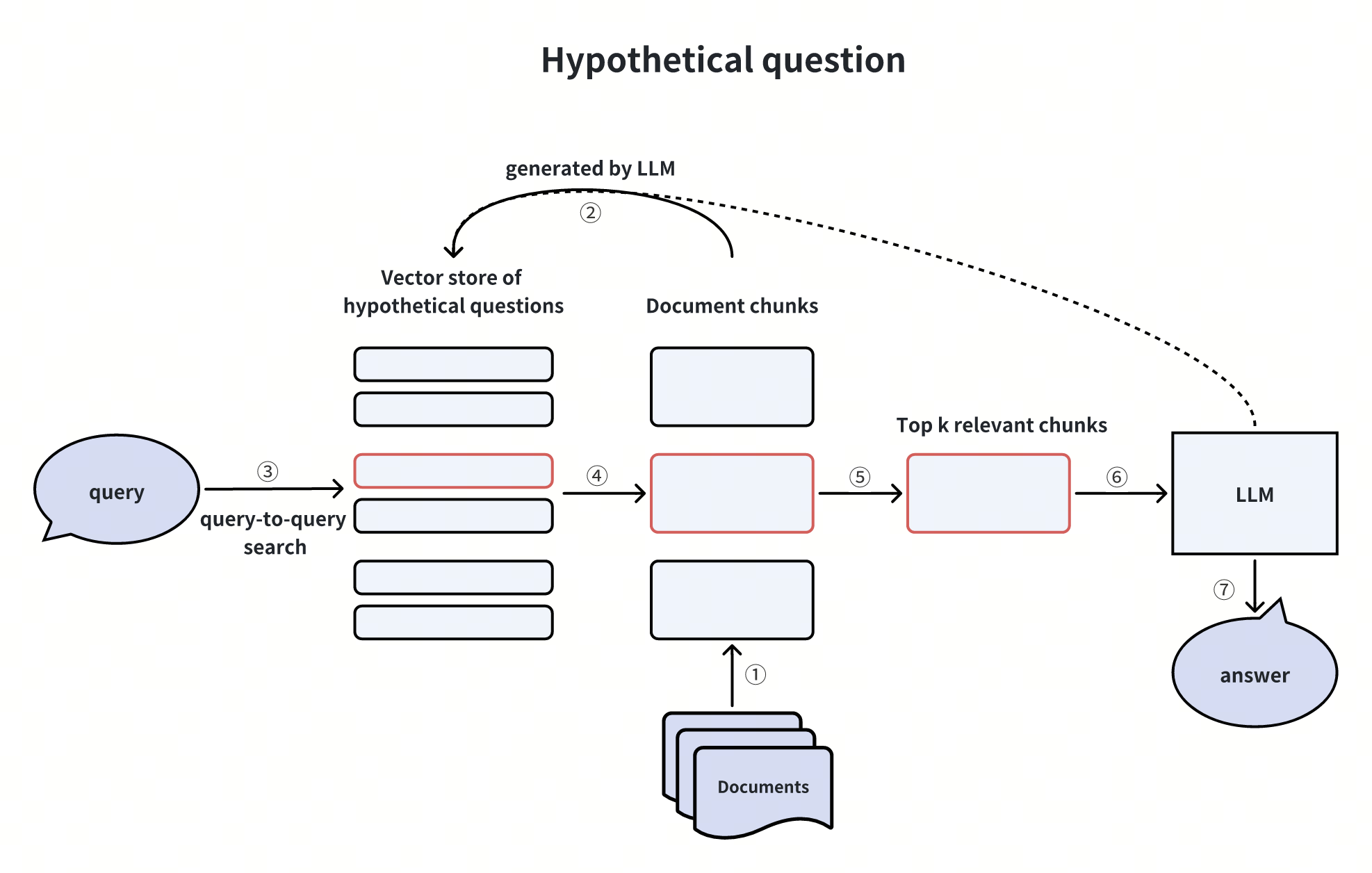
Questa metodologia aggira il problema dell'asimmetria interdistrettuale nel processo di ricerca vettoriale, impegnandosi direttamente nella ricerca da domanda a domanda e alleggerendo l'onere della ricerca vettoriale. Tuttavia, introduce ulteriori spese e incertezze nella generazione di domande ipotetiche.
HyDE (Hypothetical Document Embeddings)
HyDE è l'acronimo di Hypothetical Document Embeddings. Sfrutta un LLM per creare un"documento ipotetico" o una risposta falsa in risposta a una domanda dell'utente priva di informazioni contestuali. Questa risposta fittizia viene poi convertita in embeddings vettoriali e utilizzata per interrogare i pezzi di documento più rilevanti all'interno di un database vettoriale. Successivamente, il database vettoriale recupera i Top-K chunks di documenti più rilevanti e li trasmette al LLM e alla query originale dell'utente per generare la risposta finale.
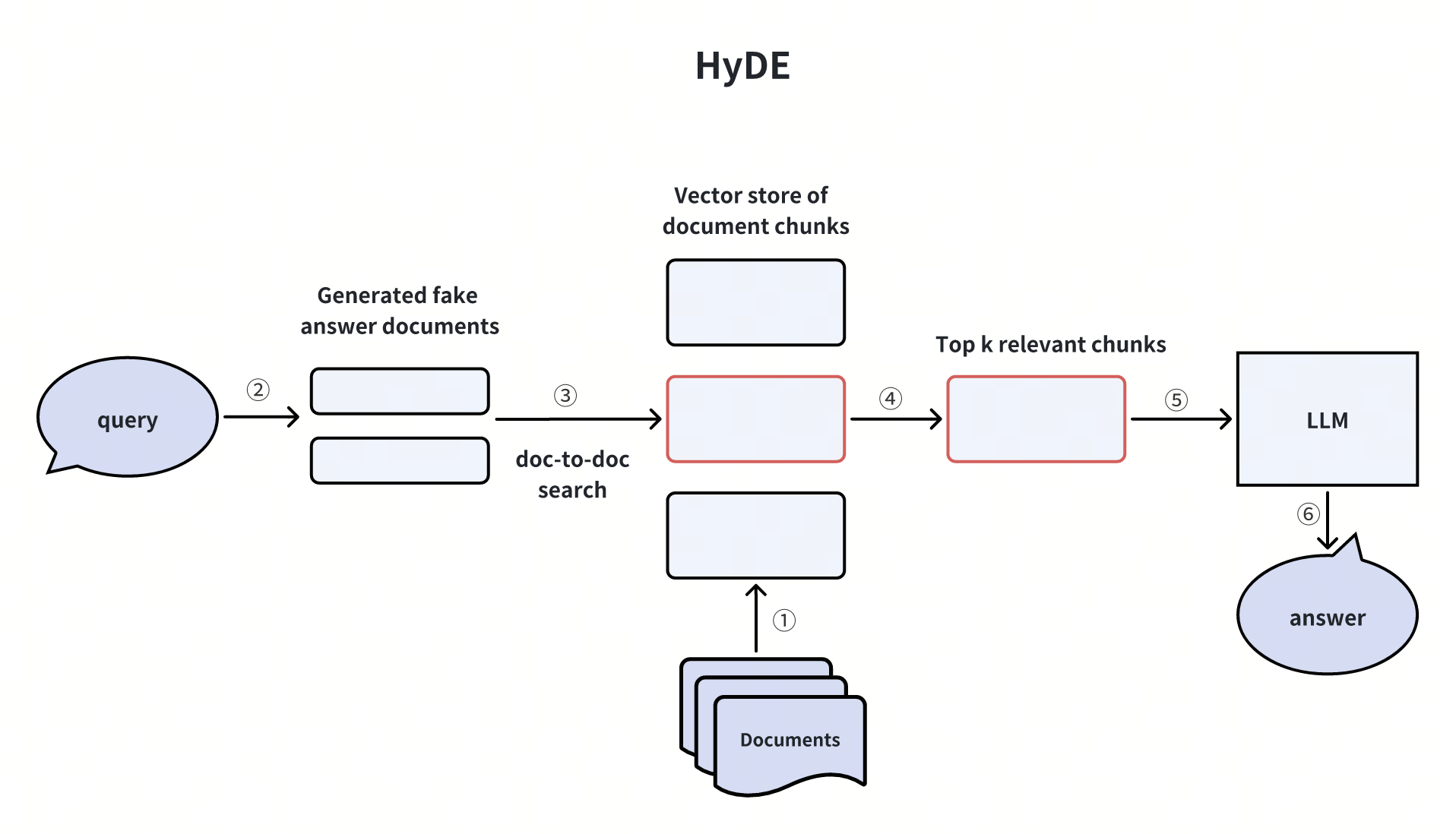
Questo metodo è simile alla tecnica della domanda ipotetica per affrontare l'asimmetria interdimensionale nelle ricerche vettoriali. Tuttavia, presenta anche degli svantaggi, come i costi computazionali aggiuntivi e le incertezze legate alla generazione di risposte false.
Per ulteriori informazioni, consultare il documento HyDE.
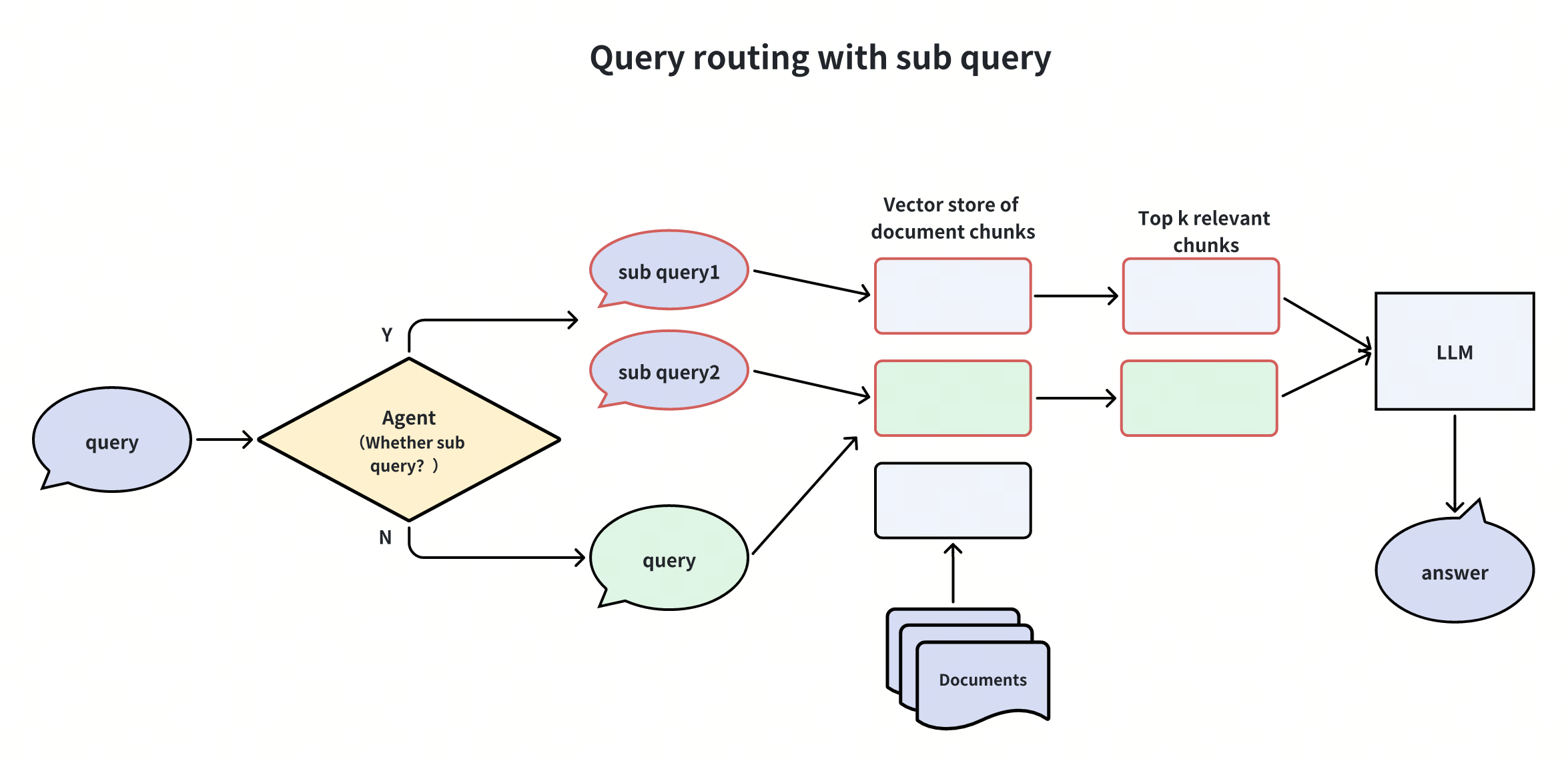
Creazione di sotto-query
Quando una query dell'utente è troppo complicata, possiamo usare un LLM per scomporla in sotto-query più semplici prima di passarle al database vettoriale e all'LLM. Vediamo un esempio.
Immaginiamo che un utente chieda:"Quali sono le differenze di caratteristiche tra Milvus e Zilliz Cloud?". Questa domanda è piuttosto complessa e potrebbe non avere una risposta diretta nella nostra base di conoscenze. Per affrontare la questione, possiamo dividerla in due sotto-query più semplici:
- Sotto-query 1: "Quali sono le caratteristiche di Milvus?".
- Sub-query 2: "Quali sono le caratteristiche di Zilliz Cloud?".
Una volta ottenute queste sotto-query, le inviamo tutte al database vettoriale dopo averle convertite in embeddings vettoriali. Il database vettoriale trova quindi i Top-K document chunks più rilevanti per ogni sotto-query. Infine, il LLM utilizza queste informazioni per generare una risposta migliore.
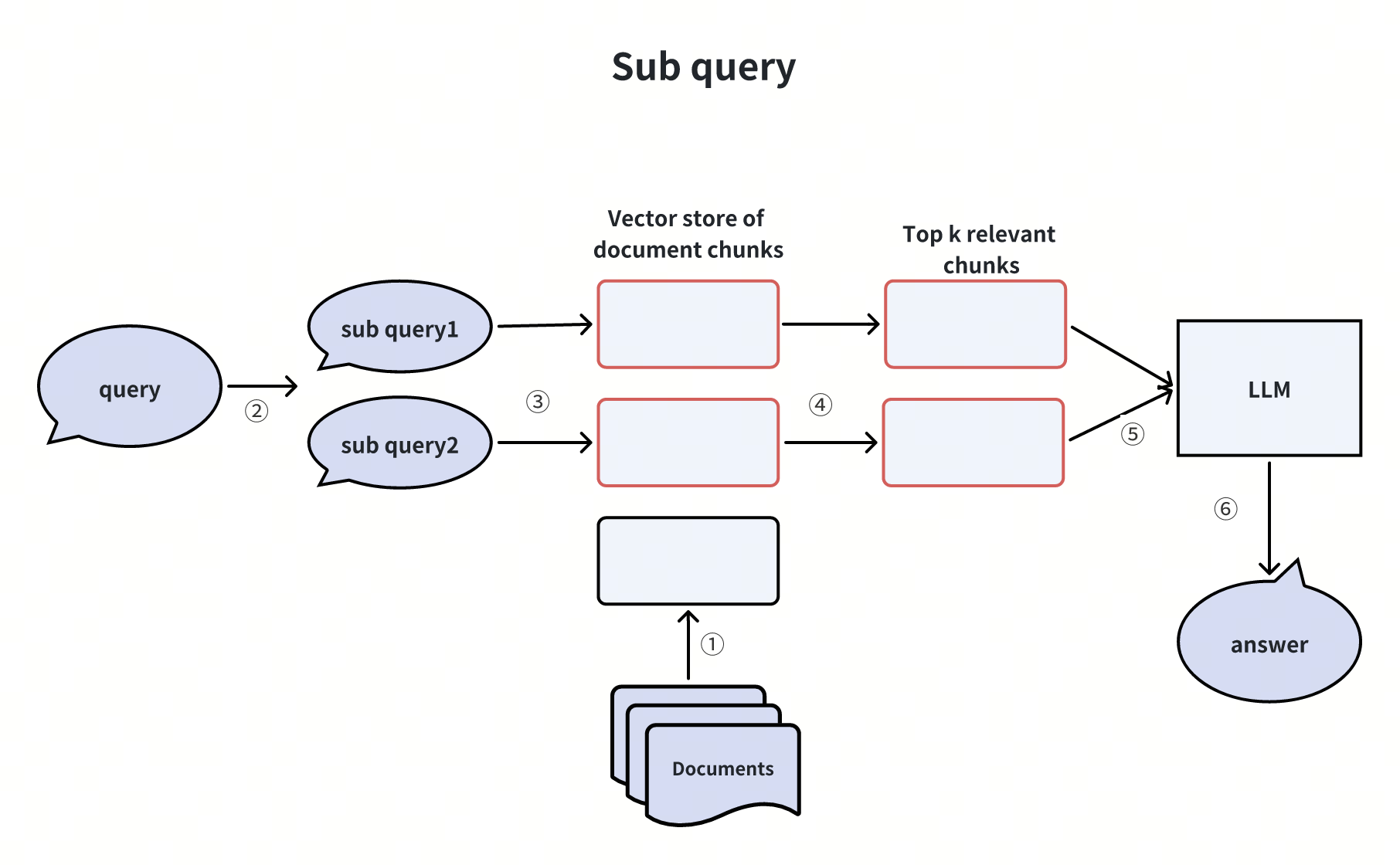
Scomponendo la domanda dell'utente in sotto-query, rendiamo più facile per il nostro sistema trovare informazioni pertinenti e fornire risposte accurate, anche a domande complesse.
Creazione di prompt stepback
Un altro modo per semplificare le domande complesse degli utenti è quello di creare dei prompt a ritroso. Questa tecnica consiste nell'astrarre le domande complesse dell'utente in "domande a ritroso"** utilizzando un LLM. Poi, un database vettoriale utilizza queste domande per recuperare i pezzi di documento più rilevanti. Infine, l'LLM genera una risposta più accurata sulla base dei pezzi di documento recuperati.
Illustriamo questa tecnica con un esempio. Consideriamo la seguente domanda, piuttosto complessa e di non facile risposta diretta:
Query originale dell'utente: "Ho un set di dati con 10 miliardi di record e voglio memorizzarlo in Milvus per poterlo interrogare. È possibile?"
Per semplificare questa domanda dell'utente, possiamo utilizzare un LLM per generare una domanda di ritorno più semplice:
Domanda di ritorno: "Qual è il limite di dimensione del dataset che Milvus può gestire?".
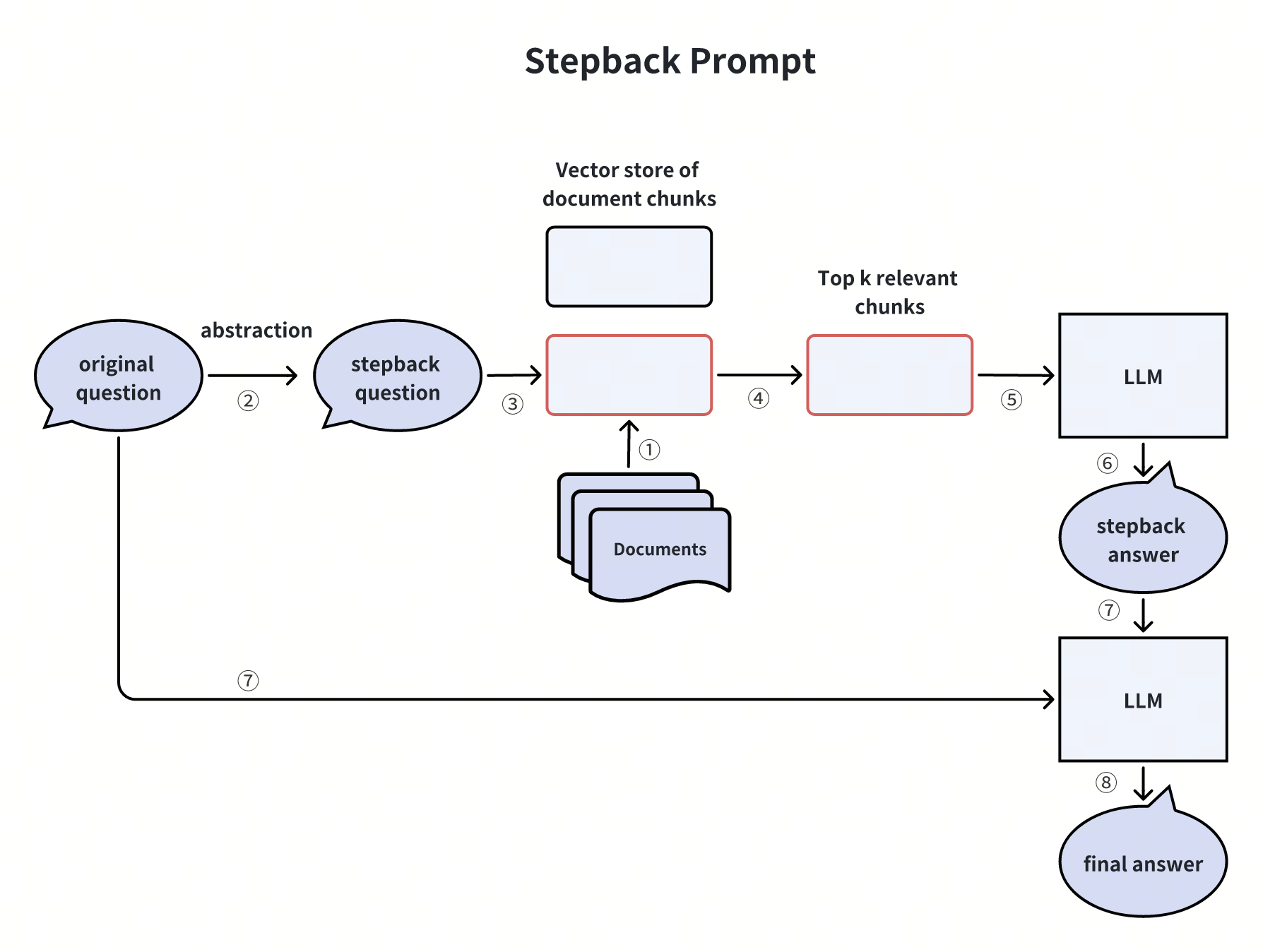
Questo metodo può aiutarci a ottenere risposte migliori e più precise a domande complesse. Scompone la domanda originale in una forma più semplice, rendendo più facile per il nostro sistema trovare informazioni pertinenti e fornire risposte accurate.
Miglioramento dell'indicizzazione
Il miglioramento dell'indicizzazione è un'altra strategia per migliorare le prestazioni delle applicazioni RAG. Esploriamo tre tecniche di miglioramento dell'indicizzazione.
Unire automaticamente i pezzi di documento
Quando si costruisce un indice, si possono utilizzare due livelli di granularità: i pezzi figli e i corrispondenti pezzi genitori. Inizialmente, cerchiamo i pezzi figli a un livello di dettaglio più fine. Poi, applichiamo una strategia di fusione: se un numero specifico, n, di chunk figlio dei primi k chunk figlio appartiene allo stesso chunk genitore, forniamo questo chunk genitore all'LLM come informazione contestuale.
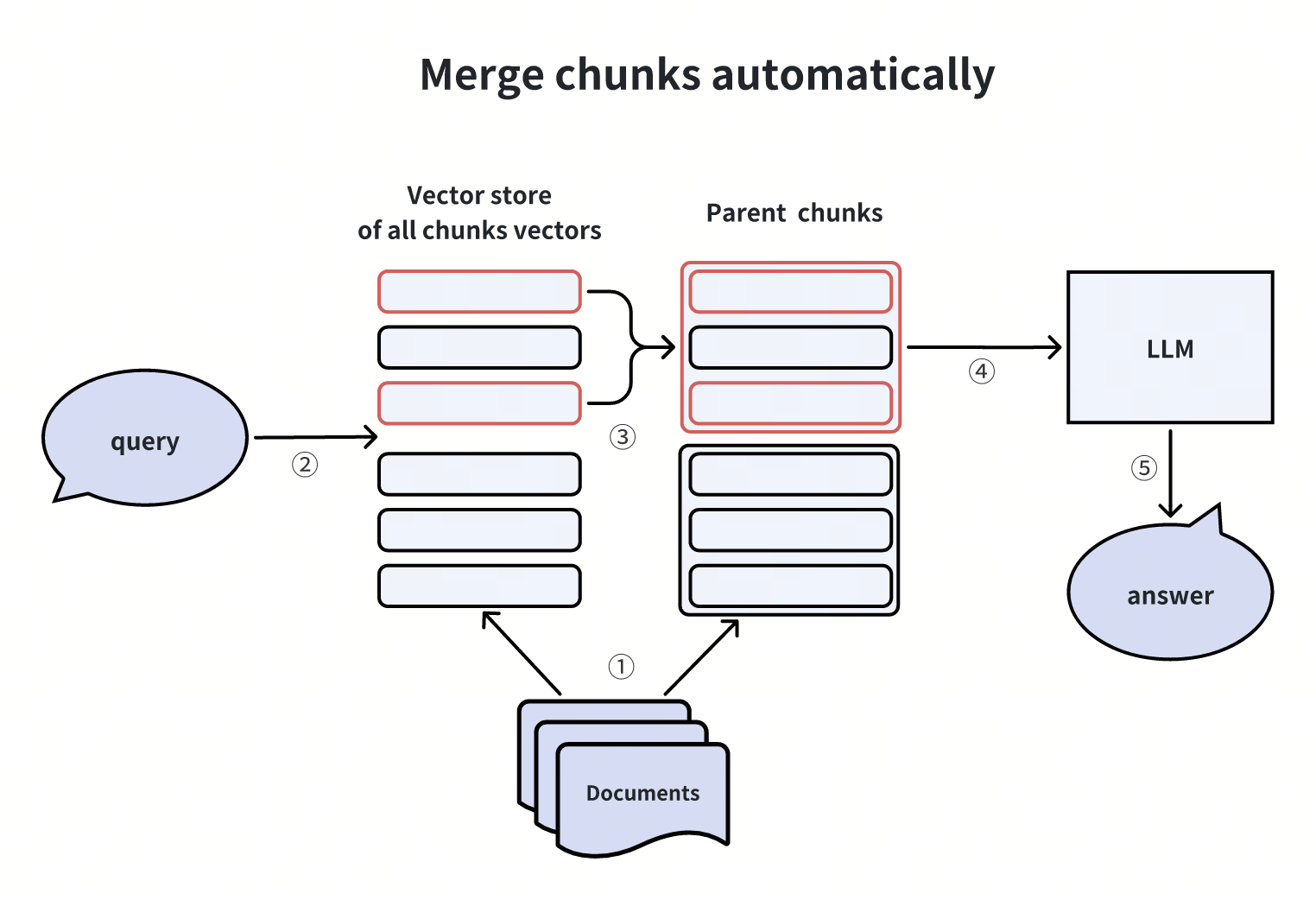
Questa metodologia è stata implementata in LlamaIndex.
Costruzione di indici gerarchici
Quando si creano indici per i documenti, si può stabilire un indice a due livelli: uno per i sommari dei documenti e un altro per i chunk dei documenti. Il processo di ricerca vettoriale comprende due fasi: inizialmente si filtrano i documenti rilevanti in base al sommario e successivamente si recuperano i pezzi di documento corrispondenti esclusivamente all'interno di questi documenti rilevanti.
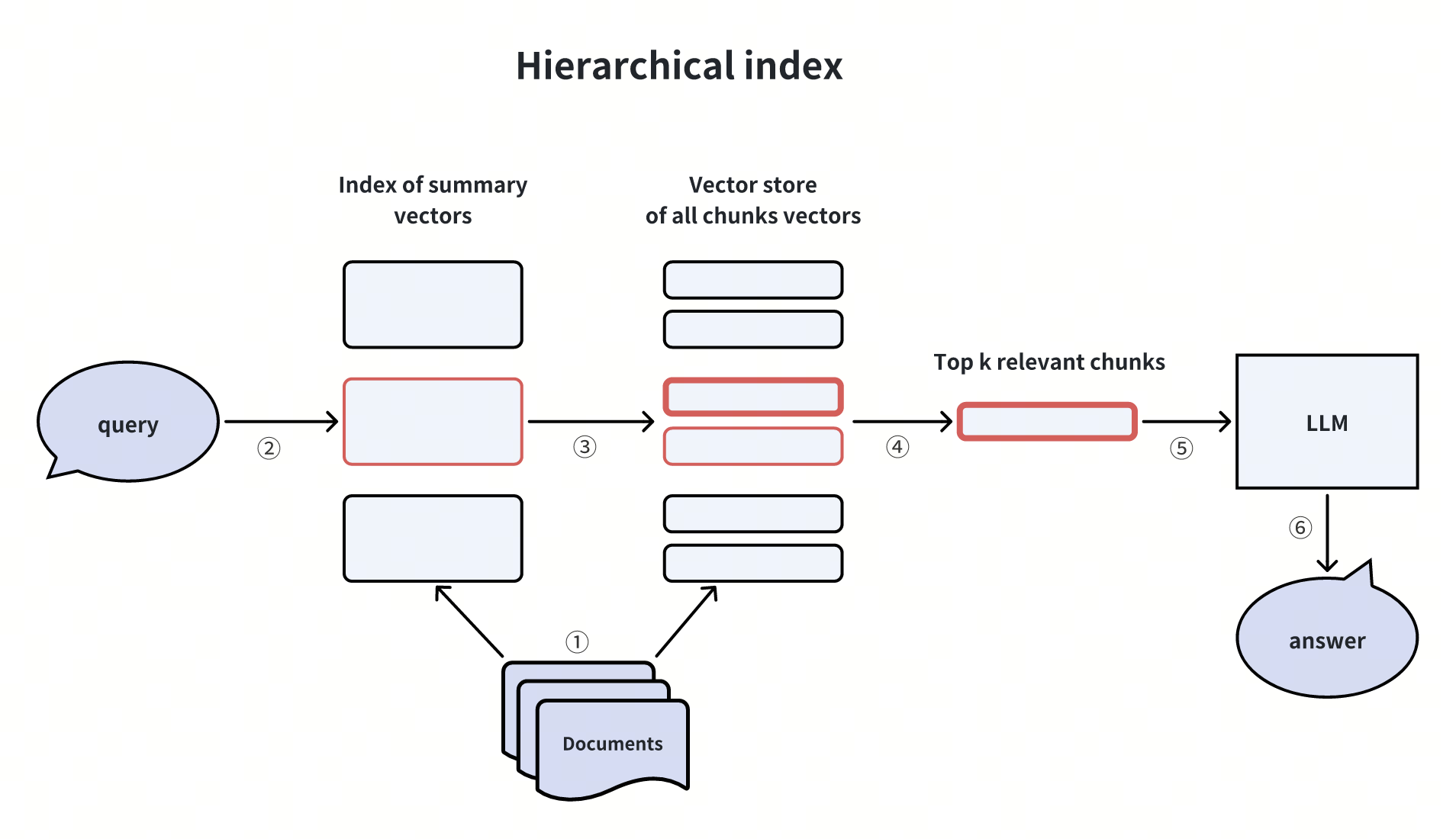
Questo approccio si rivela vantaggioso in situazioni che coinvolgono grandi volumi di dati o in casi in cui i dati sono gerarchici, come nel caso del recupero di contenuti all'interno di una collezione di biblioteche.
Recupero ibrido e riclassificazione
La tecnica Hybrid Retrieval and Reranking integra uno o più metodi di recupero supplementari con il recupero della similarità vettoriale. Quindi, un reranker classifica i risultati recuperati in base alla loro pertinenza rispetto alla richiesta dell'utente.
Gli algoritmi di recupero supplementari più comuni includono metodi basati sulla frequenza lessicale, come BM25, o grandi modelli che utilizzano embeddings sparsi, come Splade. Gli algoritmi di reranking includono RRF o modelli più sofisticati come Cross-Encoder, che assomiglia ad architetture simili a BERT.
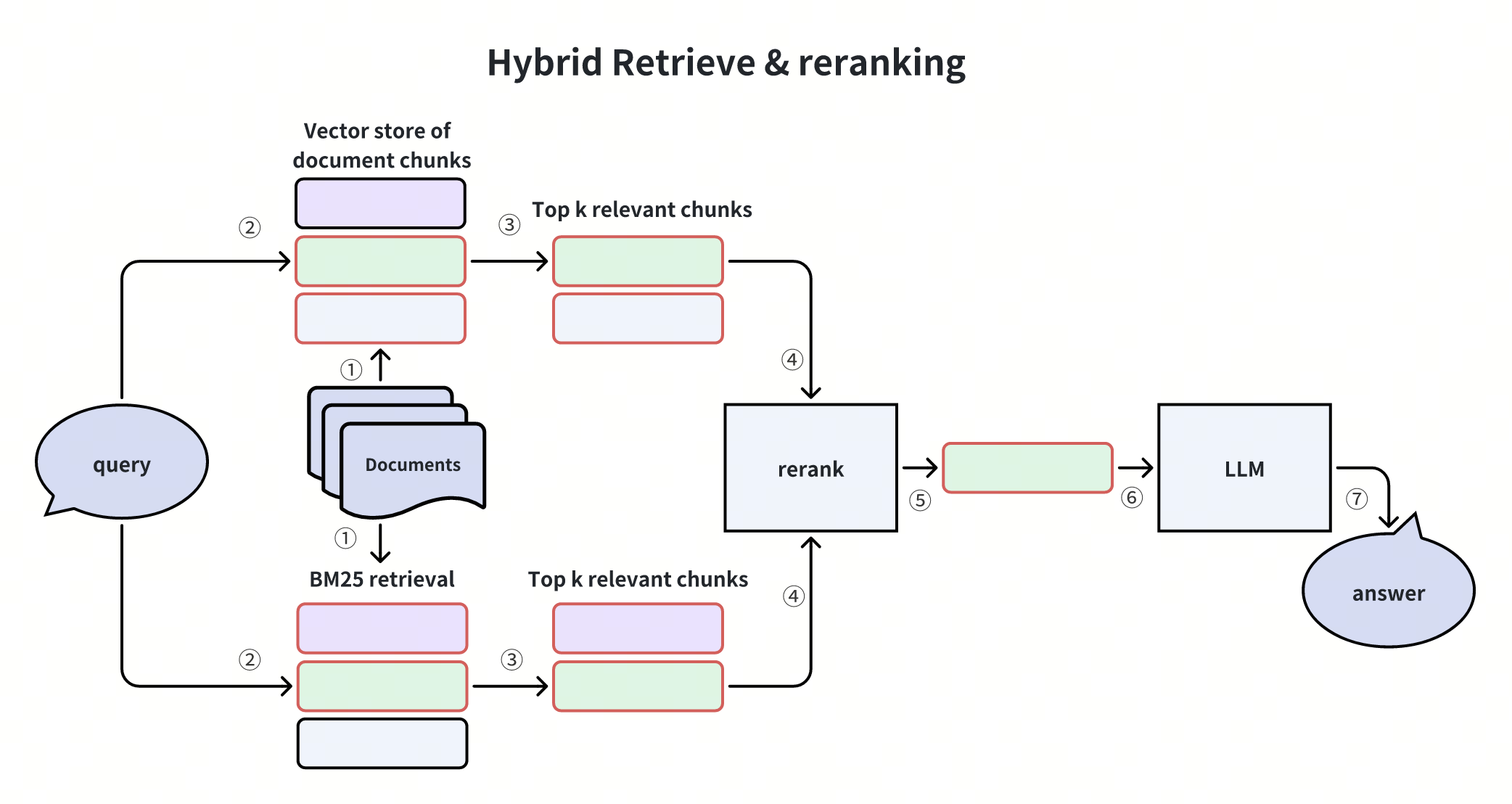
Questo approccio sfrutta diversi metodi di recupero per migliorare la qualità del recupero e affrontare le potenziali lacune nel richiamo dei vettori.
Miglioramento del retriever
Anche il perfezionamento del componente retriever all'interno del sistema RAG può migliorare le applicazioni RAG. Esploriamo alcuni metodi efficaci per migliorare il retriever.
Recupero della finestra di frase
In un sistema RAG di base, il chunk di documento fornito al LLM è una finestra più ampia che comprende il chunk di incorporamento recuperato. Ciò garantisce che le informazioni fornite al LLM includano una gamma più ampia di dettagli contestuali, riducendo al minimo la perdita di informazioni. La tecnica di Sentence Window Retrieval disaccoppia il chunk del documento utilizzato per il recupero dell'embedding dal chunk fornito all'LLM.
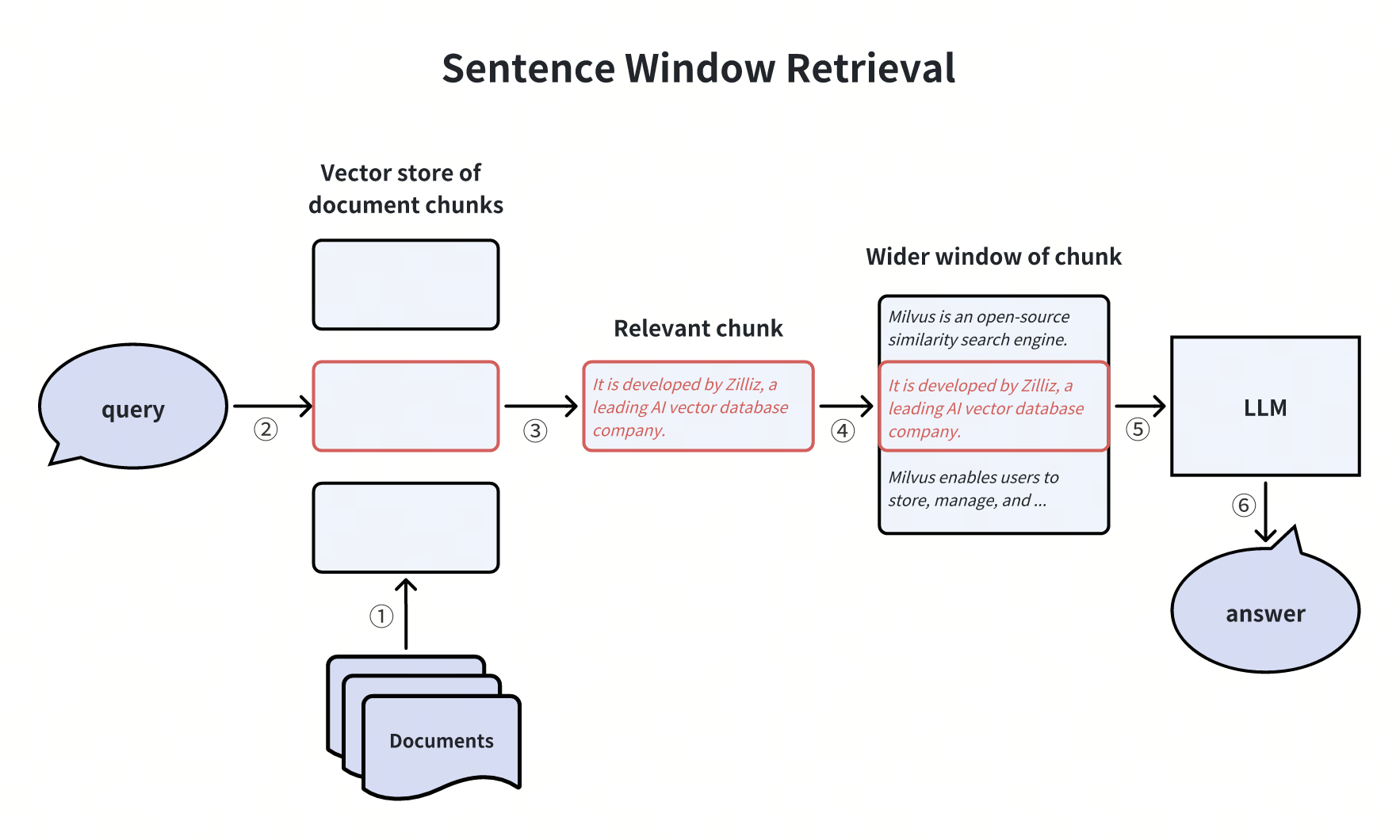
Tuttavia, l'espansione delle dimensioni della finestra può introdurre ulteriori informazioni di disturbo. Possiamo regolare la dimensione dell'espansione della finestra in base alle specifiche esigenze aziendali.
Filtraggio dei metadati
Per garantire risposte più precise, possiamo affinare i documenti recuperati filtrando i metadati come l'ora e la categoria prima di passarli al LLM. Ad esempio, se si recuperano rapporti finanziari che coprono più anni, il filtro basato sull'anno desiderato perfezionerà le informazioni per soddisfare i requisiti specifici. Questo metodo si rivela efficace in situazioni con dati estesi e metadati dettagliati, come il recupero di contenuti nelle collezioni delle biblioteche.
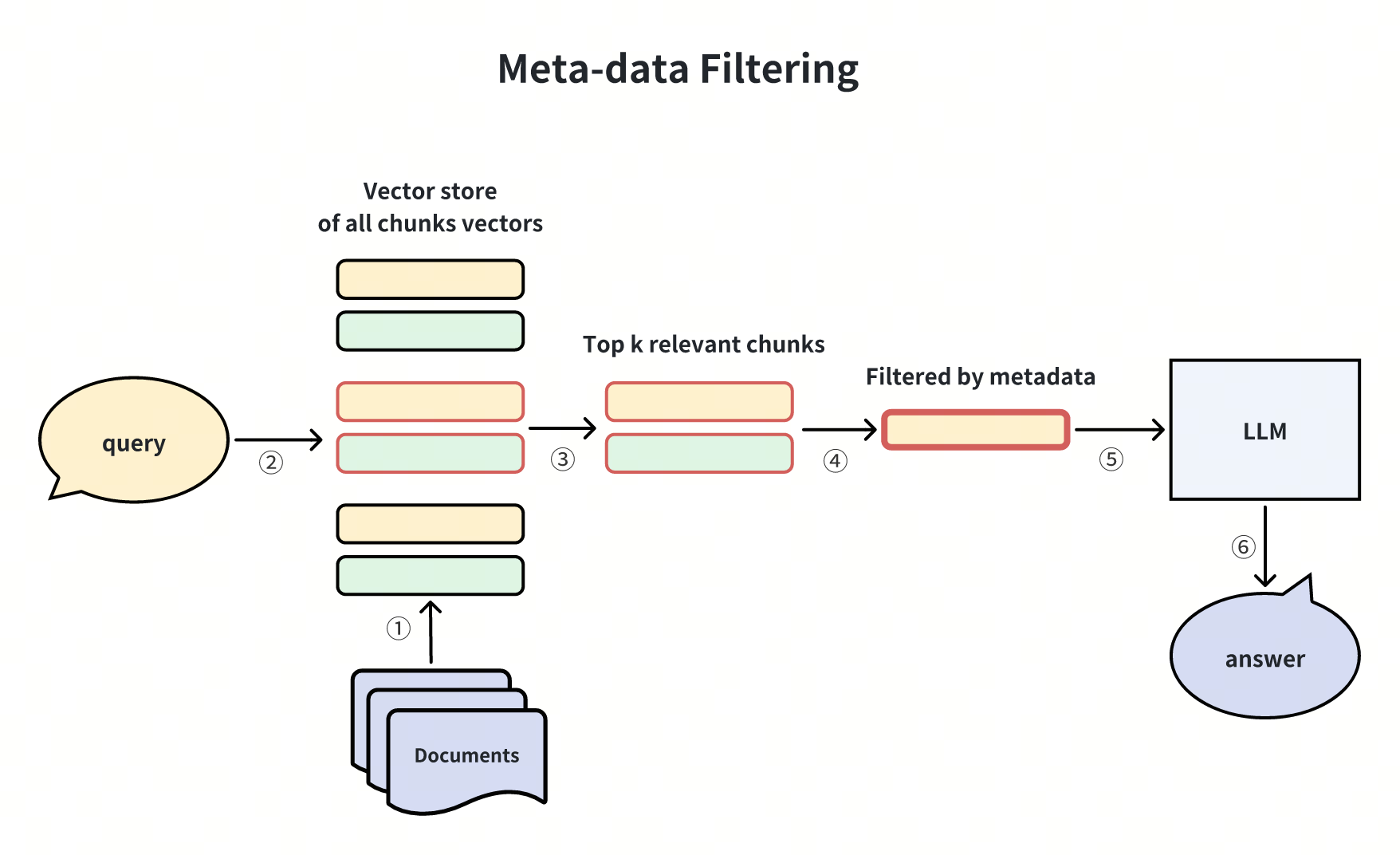
Miglioramento del generatore
Esploriamo altre tecniche di ottimizzazione delle RAG migliorando il generatore all'interno di un sistema RAG.
Comprimere il prompt LLM
Le informazioni di disturbo all'interno dei pezzi di documento recuperati possono influire in modo significativo sull'accuratezza della risposta finale di RAG. Anche la finestra di richiesta limitata degli LLM rappresenta un ostacolo per ottenere risposte più accurate. Per affrontare questa sfida, possiamo comprimere i dettagli irrilevanti, enfatizzare i paragrafi chiave e ridurre la lunghezza complessiva del contesto dei pezzi di documento recuperati.
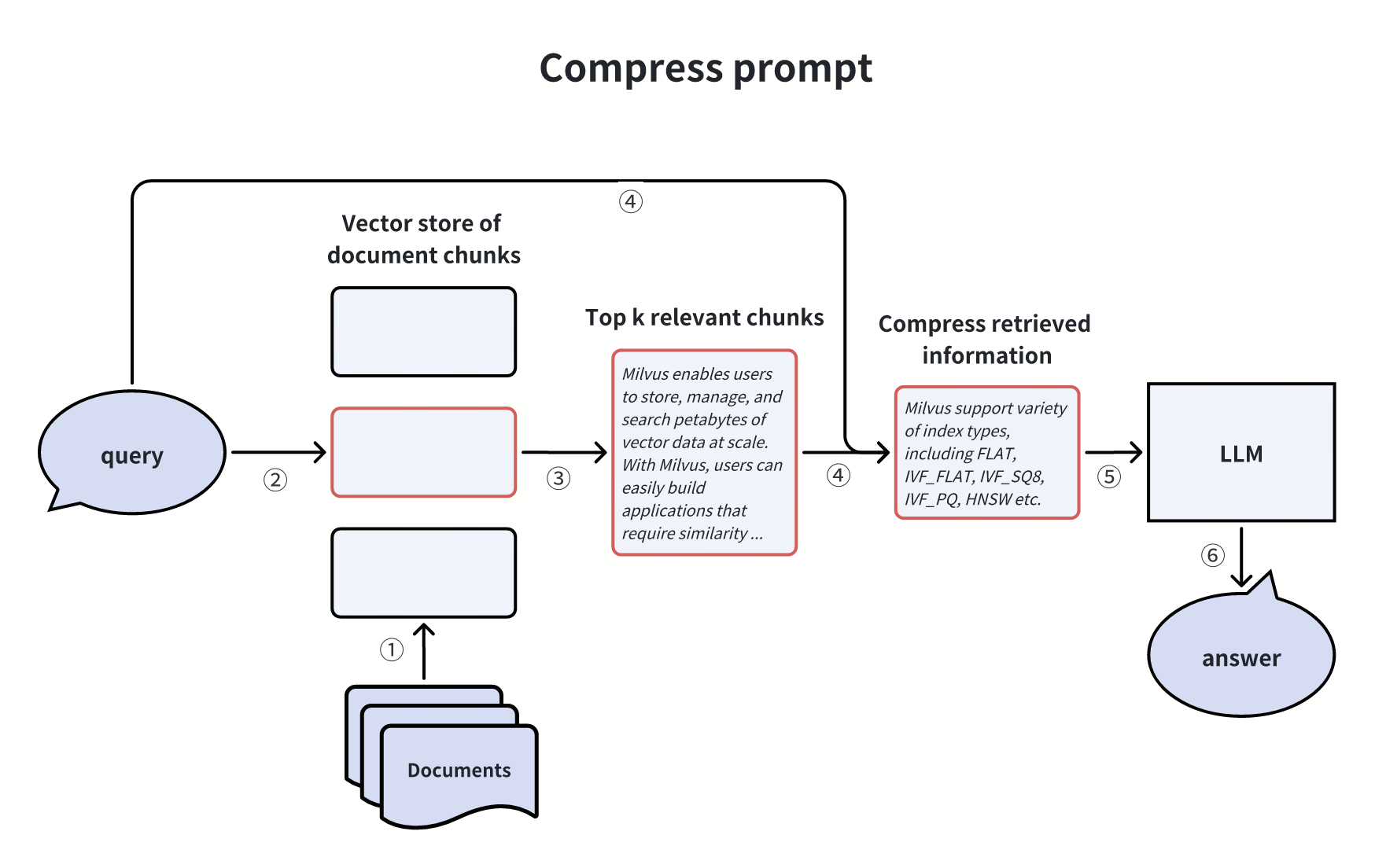
Questo approccio è simile al metodo di recupero ibrido e di reranking discusso in precedenza, in cui viene utilizzato un reranker per eliminare i pezzi di documento irrilevanti.
Regolazione dell'ordine dei chunk nel prompt
Nell'articolo"Lost in the middle", i ricercatori hanno osservato che i LLM spesso trascurano le informazioni al centro dei documenti dati durante il processo di ragionamento. Invece, tendono a basarsi maggiormente sulle informazioni presentate all'inizio e alla fine dei documenti.
Sulla base di questa osservazione, possiamo regolare l'ordine dei pezzi recuperati per migliorare la qualità della risposta: quando si recuperano più pezzi di conoscenza, i pezzi con una fiducia relativamente bassa vengono collocati al centro, mentre quelli con una fiducia relativamente alta vengono posizionati alle due estremità.
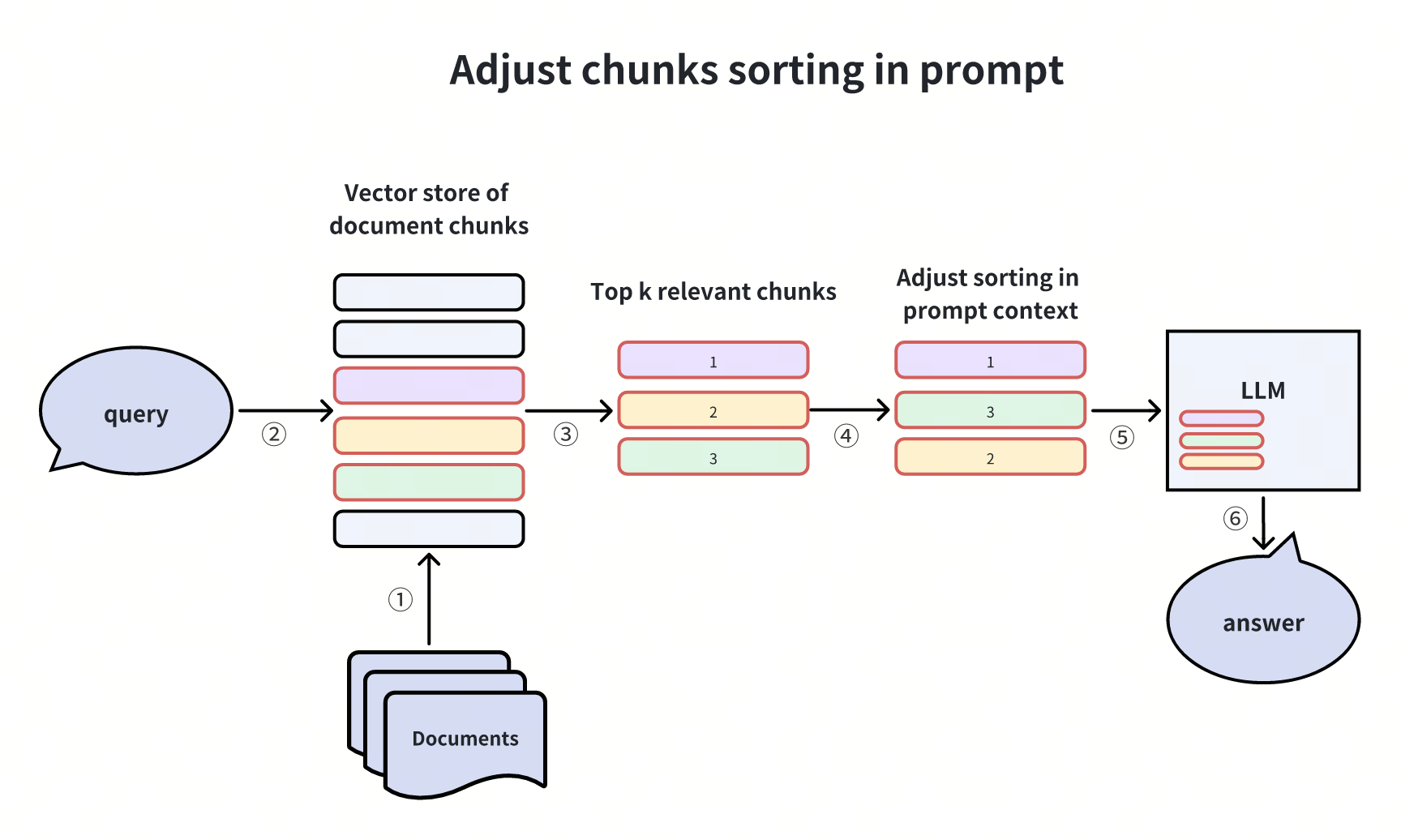
Miglioramento della pipeline RAG
Possiamo anche migliorare le prestazioni delle vostre applicazioni RAG potenziando l'intera pipeline RAG.
Auto-riflessione
Questo approccio incorpora il concetto di autoriflessione negli agenti AI. Come funziona questa tecnica?
Alcuni pezzi di documenti Top-K recuperati inizialmente sono ambigui e potrebbero non rispondere direttamente alla domanda dell'utente. In questi casi, possiamo condurre un secondo ciclo di riflessione per verificare se questi pezzi possono davvero rispondere alla domanda dell'utente.
La riflessione può essere condotta utilizzando metodi di riflessione efficienti, come i modelli di inferenza del linguaggio naturale (NLI) o strumenti aggiuntivi come le ricerche su Internet per la verifica.
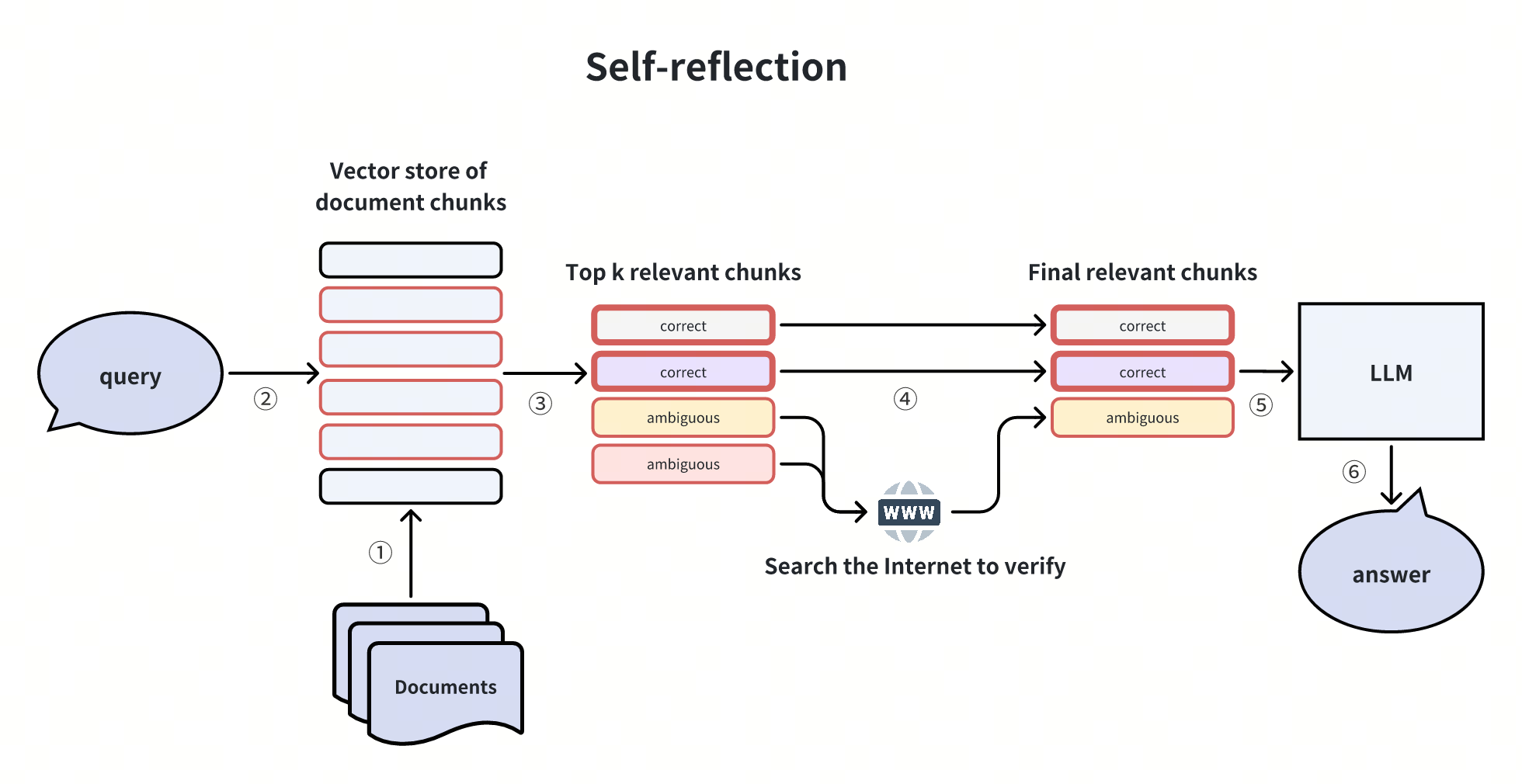
Questo concetto di auto-riflessione è stato esplorato in diversi lavori o progetti, tra cui Self-RAG, Corrective RAG, LangGraph, ecc.
Instradamento delle query con un agente
A volte non è necessario utilizzare un sistema di RAG per rispondere a domande semplici, perché ciò potrebbe causare maggiori fraintendimenti e inferenze da informazioni fuorvianti. In questi casi, possiamo utilizzare un agente come router nella fase di interrogazione. Questo agente valuta se la domanda deve passare attraverso la pipeline RAG. In caso affermativo, viene avviata la pipeline RAG successiva; in caso contrario, il LLM si occupa direttamente della query.
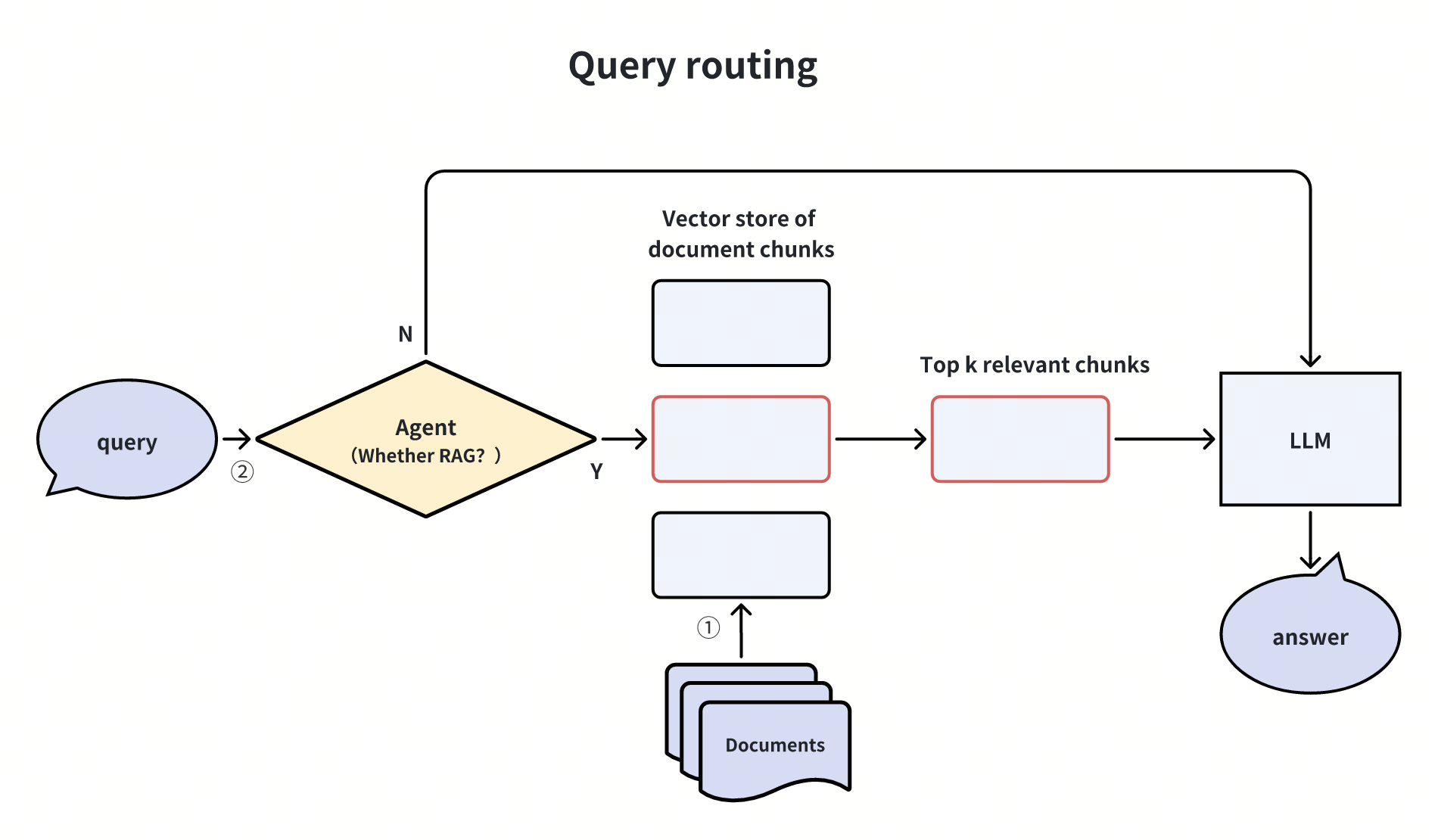
L'agente può assumere varie forme, tra cui un LLM, un piccolo modello di classificazione o anche un insieme di regole.
L'instradamento delle query in base all'intento dell'utente consente di reindirizzare una parte delle query, ottenendo un significativo aumento dei tempi di risposta e una notevole riduzione del rumore inutile.
Possiamo estendere la tecnica di instradamento delle query ad altri processi all'interno del sistema RAG, come ad esempio determinare quando utilizzare strumenti come le ricerche sul web, effettuare sotto-query o cercare immagini. Questo approccio garantisce che ogni fase del sistema RAG sia ottimizzata in base ai requisiti specifici della query, portando a un recupero delle informazioni più efficiente e accurato.
Sintesi
Sebbene una pipeline RAG di base possa sembrare semplice, il raggiungimento di prestazioni aziendali ottimali richiede spesso tecniche di ottimizzazione più sofisticate.
Questo articolo riassume vari approcci popolari per migliorare le prestazioni delle applicazioni RAG. Abbiamo anche fornito illustrazioni chiare per aiutarvi a comprendere rapidamente questi concetti e queste tecniche e a velocizzarne l'implementazione e l'ottimizzazione.
È possibile ottenere le semplici implementazioni dei principali approcci elencati in questo articolo a questo link GitHub.