IVF_PQ
Indeks IVF_PQ adalah algoritme pengindeksan berbasis kuantisasi untuk perkiraan pencarian tetangga terdekat dalam ruang berdimensi tinggi. Meskipun tidak secepat beberapa metode berbasis grafik, IVF_PQ sering kali membutuhkan lebih sedikit memori, sehingga menjadikannya pilihan praktis untuk kumpulan data yang besar.
Gambaran Umum
IVF_PQ adalah singkatan dari Inverted File with Product Quantization, sebuah pendekatan hibrida yang menggabungkan pengindeksan dan kompresi untuk pencarian dan pengambilan vektor yang efisien. Pendekatan ini memanfaatkan dua komponen inti: Inverted File (IVF ) dan Kuantisasi Produk (PQ).
IVF
IVF seperti membuat indeks dalam sebuah buku. Alih-alih memindai setiap halaman (atau, dalam kasus kami, setiap vektor), Anda mencari kata kunci tertentu (kelompok) dalam indeks untuk menemukan halaman yang relevan (vektor) dengan cepat. Dalam skenario kami, vektor dikelompokkan ke dalam kluster, dan algoritme akan mencari dalam beberapa kluster yang dekat dengan vektor kueri.
Berikut cara kerjanya:
Pengelompokan: Kumpulan data vektor Anda dibagi ke dalam sejumlah klaster tertentu, menggunakan algoritme pengelompokan seperti k-means. Setiap klaster memiliki centroid (vektor representatif untuk klaster).
Penugasan: Setiap vektor ditugaskan ke klaster yang memiliki centroid yang paling dekat dengannya.
Indeks Terbalik: Sebuah indeks dibuat, memetakan setiap centroid klaster ke daftar vektor yang ditugaskan ke klaster tersebut.
Pencarian: Saat Anda mencari tetangga terdekat, algoritme pencarian membandingkan vektor kueri Anda dengan centroid klaster dan memilih klaster yang paling menjanjikan. Pencarian kemudian dipersempit menjadi vektor dalam klaster yang dipilih.
Untuk mempelajari lebih lanjut tentang detail teknisnya, lihat IVF_FLAT.
PQ
Product Quantization (PQ ) adalah metode kompresi untuk vektor berdimensi tinggi yang secara signifikan mengurangi kebutuhan penyimpanan sekaligus memungkinkan operasi pencarian kemiripan yang cepat.
Proses PQ melibatkan tahapan-tahapan utama berikut ini:
 Ivf Pq 1
Ivf Pq 1
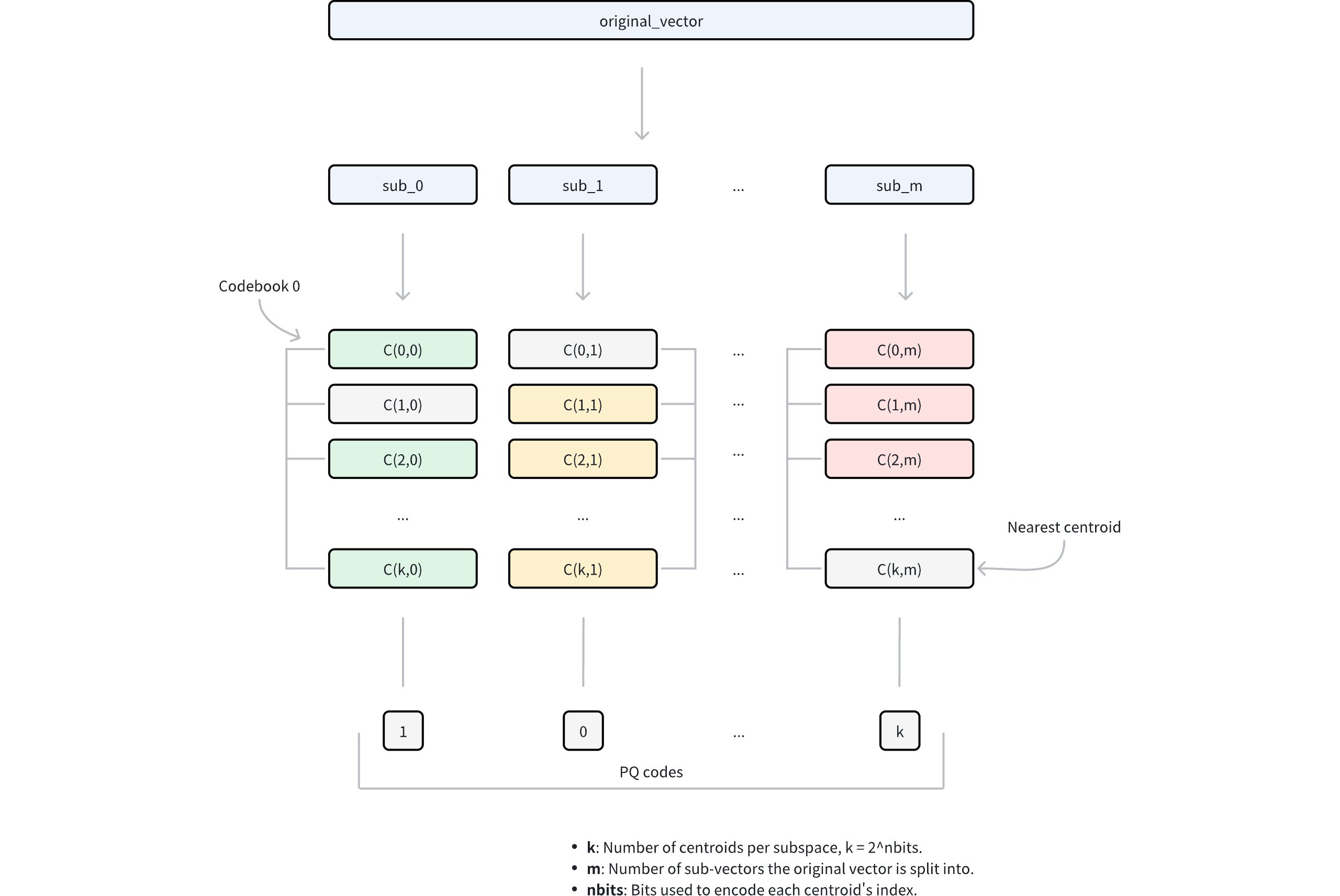
Dekomposisi dimensi: Algoritme dimulai dengan menguraikan setiap vektor dimensi tinggi menjadi
msub-vektor berukuran sama. Dekomposisi ini mengubah ruang dimensi-D asli menjadimsubruang yang terpisah-pisah, di mana setiap subruang berisi dimensi D/m. Parametermmengontrol granularitas dekomposisi dan secara langsung mempengaruhi rasio kompresi.Pembuatan buku kode subruang: Di dalam setiap subruang, algoritme menerapkan pengelompokan k-means untuk mempelajari sekumpulan vektor representatif (centroid). Centroid ini secara kolektif membentuk codebook untuk subruang tersebut. Jumlah centroid di setiap codebook ditentukan oleh parameter
nbits, di mana setiap codebook berisi 2n bit centroid. Sebagai contoh, jikanbits = 8, setiap codebook akan berisi 256 centroid. Setiap centroid diberi indeks unik dengannbitsbit.Kuantisasivektor: Untuk setiap sub-vektor dalam vektor asli, PQ mengidentifikasi centroid terdekat dalam subruang yang sesuai menggunakan jenis metrik tertentu. Proses ini secara efektif memetakan setiap sub-vektor ke vektor representatif terdekat dalam buku kode. Alih-alih menyimpan koordinat sub-vektor secara lengkap, hanya indeks dari centroid yang cocok yang disimpan.
Representasi terkompresi: Representasi terkompresi akhir terdiri dari
mindeks, satu dari setiap sub-ruang, yang secara kolektif disebut sebagai kode PQ. Pengkodean ini mengurangi kebutuhan penyimpanan dari D × 32 bit (dengan asumsi angka floating-point 32-bit) menjadi m × n bit, mencapai kompresi yang substansial sambil mempertahankan kemampuan untuk memperkirakan jarak vektor.
Untuk detail lebih lanjut tentang penyetelan dan pengoptimalan parameter, lihat Parameter indeks.
Pertimbangkan sebuah vektor dengan dimensi D = 128 menggunakan angka floating-point 32-bit. Dengan parameter PQ m = 64 (sub-vektor) dan nbits = 8 (dengan demikian k =28 = 256 centroid per subruang), kita dapat membandingkan kebutuhan penyimpanan:
Vektor asli: 128 dimensi × 32 bit = 4.096 bit
Vektor yang dikompresi PQ: 64 sub-vektor × 8 bit = 512 bit
Ini merupakan pengurangan 8x lipat dalam kebutuhan penyimpanan.
Komputasi jarak dengan PQ
Ketika melakukan pencarian kemiripan dengan vektor kueri, PQ memungkinkan penghitungan jarak yang efisien melalui langkah-langkah berikut:
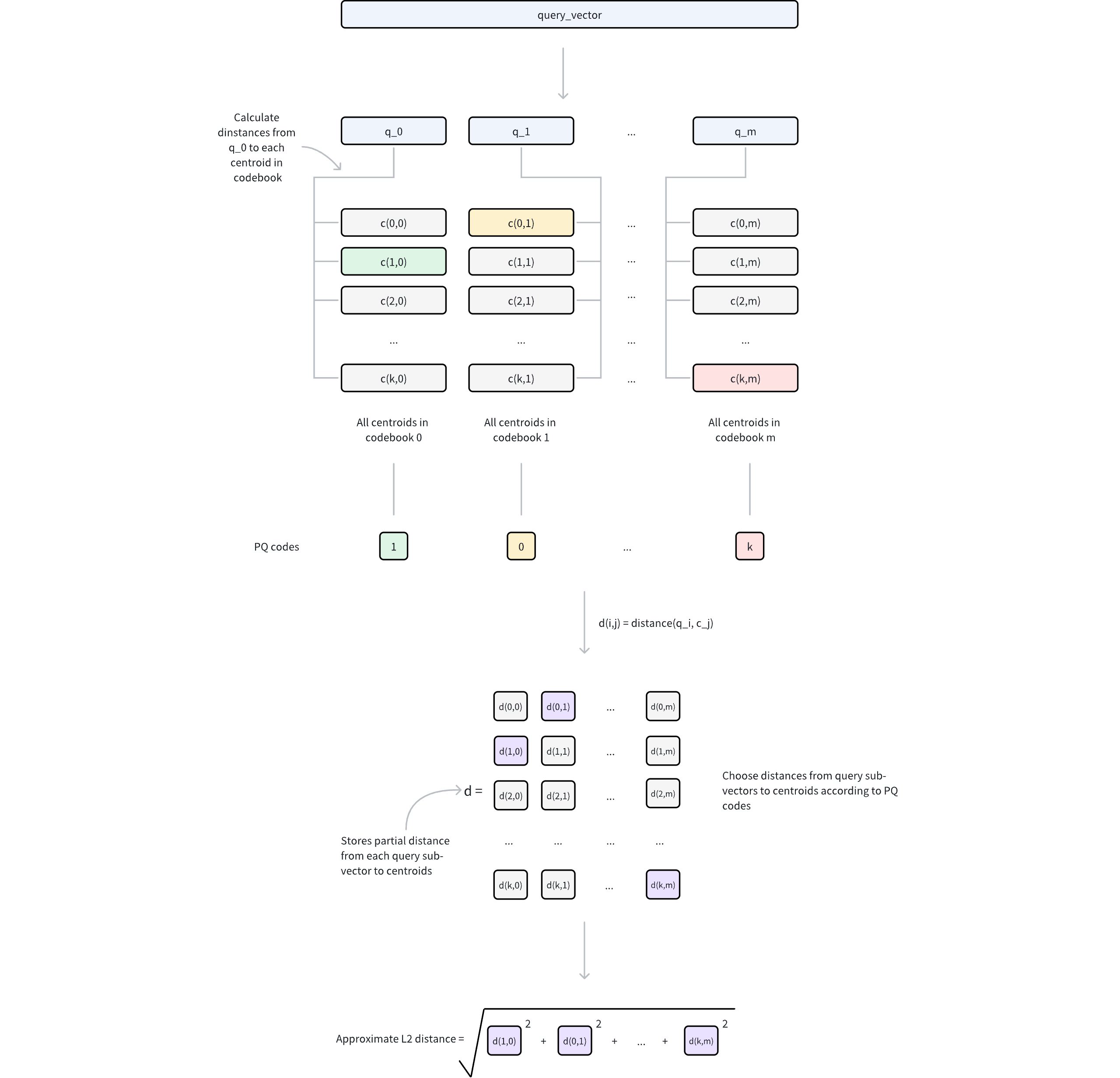
Prapemrosesan kueri
Vektor kueri diuraikan menjadi sub-vektor
m, sesuai dengan struktur penguraian PQ yang asli.Untuk setiap sub-vektor kueri dan buku kode yang sesuai (berisi centroid 2nbit ), hitung dan simpan jarak ke semua centroid.
Hal ini menghasilkan tabel pencarian
m, di mana setiap tabel berisi jarak 2nbit.
Perkiraan jarak
Untuk setiap vektor basis data yang diwakili oleh kode PQ, perkiraan jaraknya ke vektor kueri dihitung sebagai berikut:
Untuk setiap sub-vektor
m, ambil jarak yang telah dihitung sebelumnya dari tabel pencarian yang sesuai menggunakan indeks centroid yang tersimpan.Jumlahkan jarak
mini untuk mendapatkan perkiraan jarak berdasarkan jenis metrik tertentu (misalnya jarak Euclidean).
 Ivf Pq 2
Ivf Pq 2
IVF + PQ
Indeks IVF_PQ menggabungkan kekuatan IVF dan PQ untuk mempercepat pencarian. Prosesnya bekerja dalam dua langkah:
Pemfilteran kasar dengan IVF: IVF mempartisi ruang vektor ke dalam kelompok-kelompok, sehingga mengurangi cakupan pencarian. Alih-alih mengevaluasi seluruh kumpulan data, algoritme ini hanya berfokus pada cluster yang paling dekat dengan vektor kueri.
Perbandingan yang lebih baik dengan PQ: Di dalam cluster yang dipilih, PQ menggunakan representasi vektor yang dikompresi dan dikuantisasi untuk menghitung perkiraan jarak dengan cepat.
Kinerja indeks IVF_PQ secara signifikan dipengaruhi oleh parameter yang mengontrol algoritma IVF dan PQ. Menyetel parameter ini sangat penting untuk mencapai hasil yang optimal untuk set data dan aplikasi tertentu. Informasi lebih rinci tentang parameter ini dan cara menyetelnya dapat ditemukan di Index params.
Membangun indeks
Untuk membangun indeks IVF_PQ pada bidang vektor di Milvus, gunakan metode add_index(), tentukan index_type, metric_type, dan parameter tambahan untuk indeks.
from pymilvus import MilvusClient
# Prepare index building params
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="IVF_PQ", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"m": 4, # Number of sub-vectors to split eahc vector into
} # Index building params
)
Dalam konfigurasi ini:
index_type: Jenis indeks yang akan dibangun. Dalam contoh ini, tetapkan nilainya keIVF_PQ.metric_type: Metode yang digunakan untuk menghitung jarak antara vektor. Nilai yang didukung termasukCOSINE,L2, danIP. Untuk detailnya, lihat Jenis Metrik.params: Opsi konfigurasi tambahan untuk membangun indeks.m: Jumlah sub-vektor yang akan dibagi menjadi vektor.
Untuk mempelajari lebih lanjut parameter pembuatan yang tersedia untuk indeks
IVF_PQ, lihat Parameter pembuatan indeks.
Setelah parameter indeks dikonfigurasi, Anda dapat membuat indeks dengan menggunakan metode create_index() secara langsung atau mengoper parameter indeks dalam metode create_collection. Untuk detailnya, lihat Membuat Koleksi.
Mencari di indeks
Setelah indeks dibuat dan entitas dimasukkan, Anda dapat melakukan pencarian kemiripan pada indeks.
search_params = {
"params": {
"nprobe": 10, # Number of clusters to search
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # Collection name
anns_field="vector_field", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
limit=3, # TopK results to return
search_params=search_params
)
Dalam konfigurasi ini:
params: Opsi konfigurasi tambahan untuk pencarian pada indeks.nprobe: Jumlah kluster yang akan dicari.
Untuk mempelajari lebih lanjut parameter pencarian yang tersedia untuk indeks
IVF_PQ, lihat Parameter pencarian khusus indeks.
Parameter indeks
Bagian ini memberikan gambaran umum tentang parameter yang digunakan untuk membangun indeks dan melakukan pencarian pada indeks.
Parameter pembangunan indeks
Tabel berikut mencantumkan parameter yang dapat dikonfigurasi di params saat membangun indeks.
Parameter |
Deskripsi |
Rentang Nilai |
Saran Penyetelan |
|
|---|---|---|---|---|
IVF |
|
Jumlah klaster yang akan dibuat menggunakan algoritme k-means selama pembuatan indeks. |
Jenis: Rentang bilangan bulat: [1, 65536] Nilai default: |
Nilai |
PQ |
|
Jumlah sub-vektor (digunakan untuk kuantisasi) untuk membagi setiap vektor dimensi tinggi selama proses kuantisasi. |
Jenis: Bilangan bulat Rentang: [1, 65536] Nilai default: Tidak ada |
Nilai Dalam kebanyakan kasus, kami sarankan Anda menetapkan nilai dalam kisaran ini: [D/8, D]. |
|
Jumlah bit yang digunakan untuk merepresentasikan indeks centroid setiap sub-vektor dalam bentuk terkompresi. Ini secara langsung menentukan ukuran setiap codebook. Setiap codebook akan berisi centroid 2nbit. Sebagai contoh, jika |
Jenis: Rentang Bilangan Bulat: [1, 24] Nilai default: |
Nilai |
Parameter pencarian khusus indeks
Tabel berikut mencantumkan parameter yang dapat dikonfigurasi di search_params.params saat mencari di indeks.
Parameter |
Deskripsi |
Rentang Nilai |
Saran Penyetelan |
|
|---|---|---|---|---|
IVF |
|
Jumlah cluster untuk mencari kandidat. |
Tipe Bilangan bulat Rentang: [1, nlist] Nilai default: |
Nilai yang lebih tinggi memungkinkan lebih banyak klaster untuk dicari, meningkatkan daya ingat dengan memperluas cakupan pencarian, tetapi dengan biaya peningkatan latensi kueri. Tetapkan Pada kebanyakan kasus, kami menyarankan Anda menetapkan nilai dalam kisaran ini: [1, nlist]. |