DISKANN
In large-scale scenarios, where datasets can include billions or even trillions of vectors, standard in-memory indexing methods (e.g., HNSW, IVF_FLAT) often fail to keep pace due to memory limitations. DISKANN offers a disk-based approach that addresses these challenges by maintaining high search accuracy and speed when the dataset size exceeds available RAM.
Overview
DISKANN combines two key techniques for efficient vector search:
Vamana Graph – A disk-based, graph-based index that connects data points (or vectors) for efficient navigation during search.
Product Quantization (PQ) – An in-memory compression method that reduces the size of vectors, enabling quick approximate distance calculations between vectors.
Index construction
Vamana graph
The Vamana graph is central to DISKANN’s disk-based strategy. It can handle very large datasets because it does not need to fully reside in memory during or after construction.
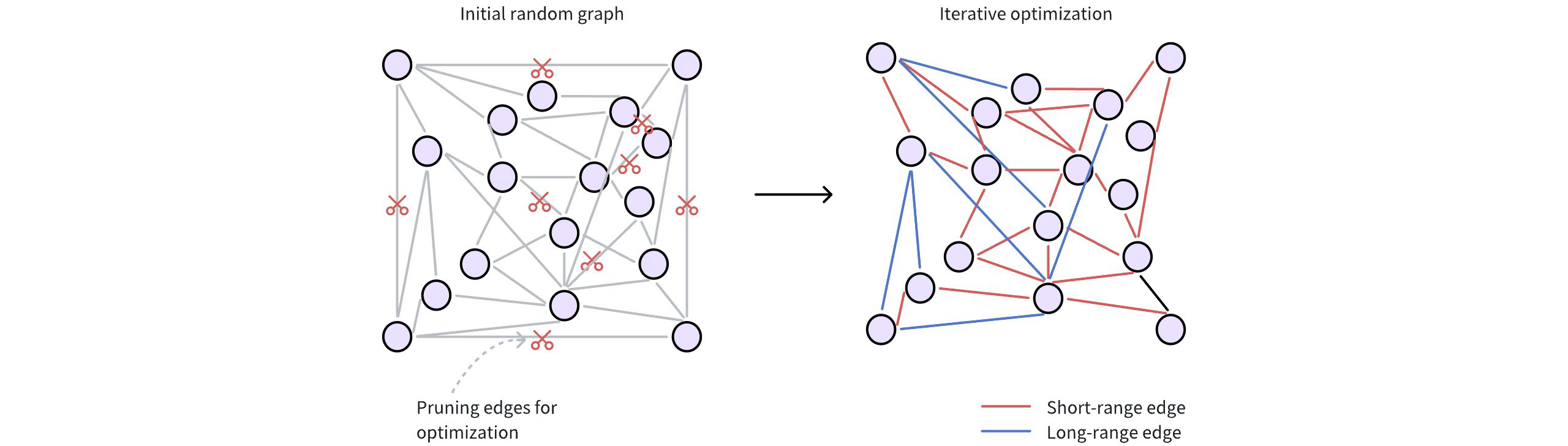
The following figure shows how a Vamana graph is constructed.
 Diskann
Diskann
Initial random connections: Each data point (vector) is represented as a node in the graph. These nodes are initially connected randomly, forming a dense network. Typically, a node starts with around 500 edges (or connections) for broad connectivity.
Refining for efficiency: The initial random graph undergoes an optimization process to make it more efficient for searching. This involves two key steps:
Pruning redundant edges: The algorithm discards unnecessary connections based on distances between nodes. This step prioritizes higher-quality edges.
The
max_degreeparameter restricts the maximum number of edges per node. A highermax_degreeresults in a denser graph, potentially finding more relevant neighbors (higher recall) but also increasing memory usage and search time.Adding strategic shortcuts: Vamana introduces long-range edges, connecting data points that are far apart in the vector space. These shortcuts allow searches to quickly jump across the graph, bypassing intermediate nodes and significantly speeding up navigation.
The
search_list_sizeparameter determines the breadth of the graph refinement process. A highersearch_list_sizeextends the search for neighbors during construction and can improve final accuracy, but increases index-building time.
To learn more about parameter tuning, refer to DISKANN params.
PQ
DISKANN uses PQ to compress high-dimensional vectors into smaller representations (PQ codes), which are stored in memory for rapid approximate distance calculations.
The pq_code_budget_gb_ratio parameter manages the memory footprint dedicated to storing these PQ codes. It represents a ratio between the total size of the vectors (in gigabytes) and the space allocated for storing the PQ codes. You can calculate the actual PQ code budget (in gigabytes) with this formula:
PQ Code Budget (GB) = vec_field_size_gb * pq_code_budget_gb_ratio
where:
vec_field_size_gbis the total size of the vectors (in gigabytes).pq_code_budget_gb_ratiois a user-defined ratio, representing the fraction of the total data size reserved for PQ codes. This parameter allows for a trade-off between search accuracy and memory resources. For more information on parameter tuning, refer to DISKANN configs.
For technical details on the underlying PQ method, refer to IVF_PQ.
Search process
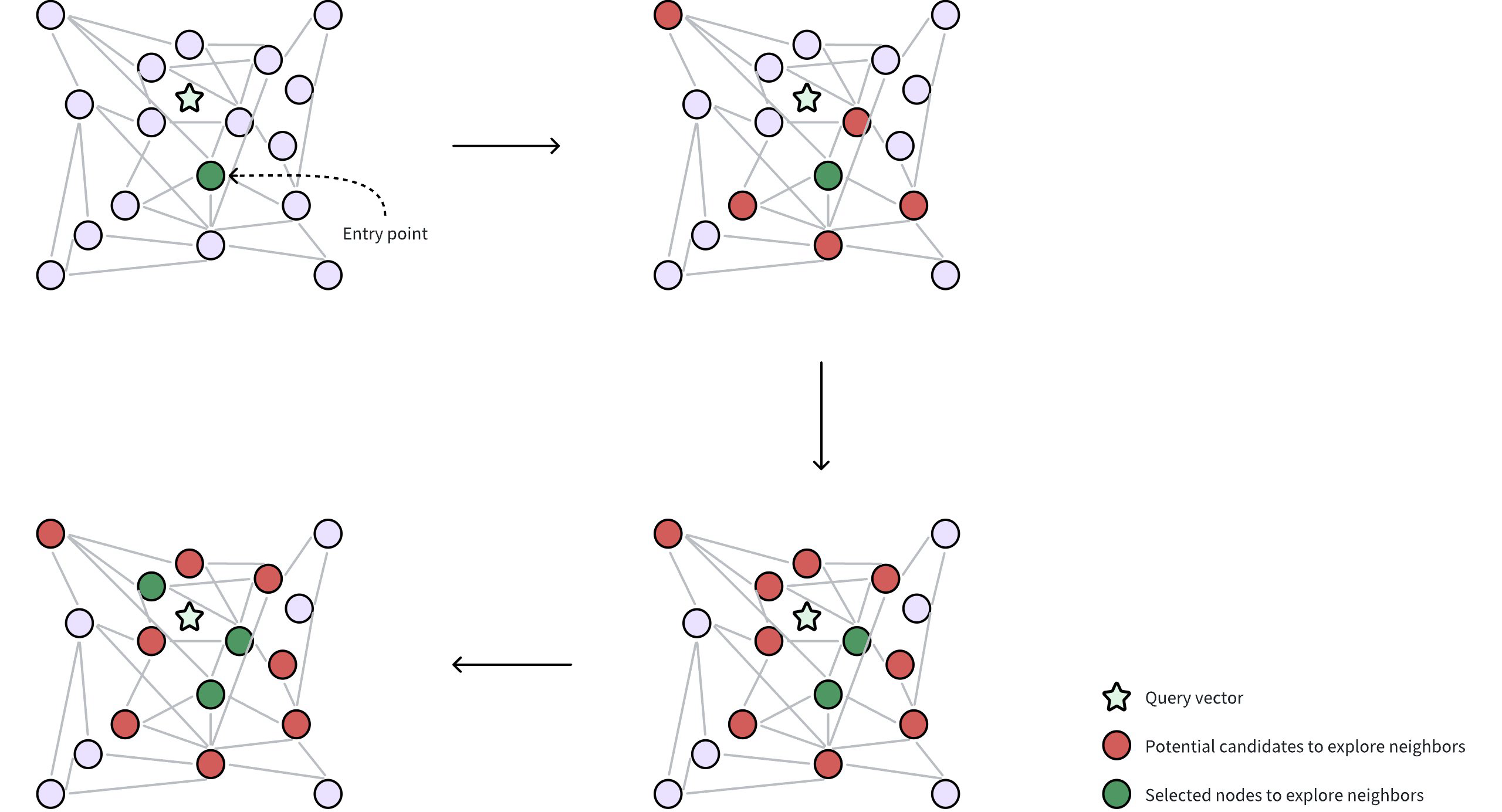
Once the index (the Vamana graph on disk and PQ codes in memory) is built, DISKANN performs ANN searches as follows:
 Diskann 2
Diskann 2
Query and entry point: A query vector is provided to locate its nearest neighbors. DISKANN starts from a selected entry point in the Vamana graph, often a node near the global centroid of the dataset. The global centroid represents the average of all vectors, which helps to minimize the traversal distance through the graph to find desired neighbors.
Neighborhood exploration: The algorithm gathers potential candidate neighbors (circles in red in the figure) from the edges of the current node, leveraging in-memory PQ codes to approximate the distances between these candidates and the query vector. These potential candidate neighbors are the nodes directly connected to the selected entry point through edges in the Vamana graph.
Selecting nodes for accurate distance calculation: From the approximate results, a subset of the most promising neighbors (circles in green in the figure) are selected for precise distance evaluations using their original, uncompressed vectors. This requires reading data from disk, which can be time-consuming. DISKANN uses two parameters to control this delicate balance between accuracy and speed:
beam_width_ratio: A ration that controls the breadth of the search, determining how many candidate neighbors are selected in parallel to explore their neighbors. A largerbeam_width_ratioresults in a wider exploration, potentially leading to higher accuracy but also increasing computational cost and disk I/O. The beam width, or the number of nodes selected, is determined using the formula:Beam width = Number of CPU cores * beam_width_ratio.search_cache_budget_gb_ratio: The proportion of memory allocated for caching frequently accessed disk data. This caching helps to minimize disk I/O, making repeated searches faster as the data is already in memory.
To learn more about parameter tuning, refer to DISKANN configs.
Iterative exploration: The search iteratively refines the set of candidates, repeatedly performing approximate evaluations (using PQ) followed by precise checks (using original vectors from disk) until a sufficient number of neighbors are found.
Enable DISKANN in Milvus
By default, DISKANN is disabled in Milvus to prioritize the speed of in-memory indexes for datasets that fit comfortably in RAM. However, if you’re working with massive datasets or want to take advantage of DISKANN's scalability and SSD optimization, you can easily enable it.
Here’s how to enable DISKANN in Milvus:
Update the Milvus Configuration File
Locate your Milvus configuration file. (Refer to the Milvus documentation on Configuration for details on finding this file.)
Find the
queryNode.enableDiskparameter and set its value totrue:queryNode: enableDisk: true # Enables query nodes to load and search using the on-disk index
Optimize Storage for DISKANN
To ensure the best performance with DISKANN, it’s recommended to store your Milvus data on a fast NVMe SSD. Here’s how to do this for both Milvus Standalone and Cluster deployments:
Milvus Standalone
Mount the Milvus data directory to an NVMe SSD within the Milvus container. You can do this in the
docker-compose.ymlfile or using other container management tools.For example, if your NVMe SSD is mounted at
/mnt/nvme, you would update thevolumessection of yourdocker-compose.ymllike this:
volumes: - /mnt/nvme/volumes/milvus:/var/lib/milvusMilvus Cluster
Mount the Milvus data directory to an NVMe SSD in both the QueryNode and IndexNode containers. You can achieve this through your container orchestration setup.
By mounting the data on an NVMe SSD in both node types, you ensure fast read and write speeds for both search and indexing operations.
Once you’ve made these changes, restart your Milvus instance for the settings to take effect. Now, Milvus will leverage DISKANN’s capabilities to handle large datasets, delivering efficient and scalable vector search.
Configure DISKANN
DISKANN-related parameters can only be configured via your Milvus configuration file (milvus.yaml):
# milvus.yaml
common:
DiskIndex:
MaxDegree: 56 # Maximum degree of the Vamana graph
SearchListSize: 100 # Size of the candidate list during building graph
PQCodeBudgetGBRatio: 0.125 # Size limit on the PQ code (compared with raw data)
SearchCacheBudgetGBRatio: 0.1 # Ratio of cached node numbers to raw data
BeamWidthRatio: 4 # Ratio between the maximum number of IO requests per search iteration and CPU number
For details on parameter descriptions, refer to DISKANN params.
DISKANN params
Fine-tuning DISKANN’s parameters allows you to tailor its behavior to your specific dataset and search workload, striking the right balance between speed, accuracy, and memory usage.
Index building params
These parameters influence how the DISKANN index is constructed. Adjusting them can affect the index size, build time, and search quality.
All the index building params in the list below can only be configured via your Milvus configuration file (milvus.yaml)
Parameter |
Description |
Value Range |
Tuning Suggestion |
|
|---|---|---|---|---|
Vamana |
|
Controls the maximum number of connections (edges) each data point can have in the Vamana graph. |
Type: Integer Range: [1, 512] Default value: |
Higher values create denser graphs, potentially increasing recall (finding more relevant results) but also increasing memory usage and build time. In most cases, we recommend you set a value within this range: [10, 100]. |
|
During index construction, this parameter defines the size of the candidate pool used when searching for the nearest neighbors for each node. For every node being added to the graph, the algorithm maintains a list of the |
Type: Integer Range: [1, int_max] Default value: |
A larger |
|
|
Controls the amount of memory allocated for caching frequently accessed parts of the graph during index construction. |
Type: Float Range: [0.0, 0.3) Default value: |
A higher value allocates more memory for caching, significantly reducing disk I/O but consuming more system memory. A lower value uses less memory for caching, potentially increasing the need for disk access. In most cases, we recommend you set a value within this range: [0.0, 0.3). |
|
PQ |
|
Controls the size of the PQ codes (compressed representations of data points) compared to the size of the uncompressed data. |
Type: Float Range: (0.0, 0.25] Default value: |
A higher ratio leads to more accurate search results by allocating a larger proportion of memory for PQ codes, effectively storing more information about the original vectors. However, this requires more memory, limiting the capacity for handling large datasets. A lower ratio reduces memory usage but potentially sacrifices accuracy, as smaller PQ codes retain less information. This approach is suitable for scenarios where memory constraints are a concern, potentially enabling the indexing of larger datasets. In most cases, we recommend you set a value within this range: (0.0625, 0.25] |
Index-specific search params
These parameters influence how DISKANN performs searches. Adjusting them can impact search speed, latency, and resource usage.
The BeamWidthRatio in the list below can only be configured via your Milvus configuration file (milvus.yaml)
The search_list in the list below can only be configured in the search params in SDK.
Parameter |
Description |
Value Range |
Tuning Suggestion |
|
|---|---|---|---|---|
Vamana |
|
Controls the degree of parallelism during search by determining the maximum number of parallel disk I/O requests relative to the number of available CPU cores. |
Type: Float Range: [1, max(128 / CPU number, 16)] Default value: |
Higher values increase parallelism, which can speed up search on systems with powerful CPUs and SSDs. However, setting it too high might lead to excessive resource contention. In most cases, we recommend you set a value within this range: [1.0, 4.0]. |
|
During a search operation, this parameter determines the size of the candidate pool that the algorithm maintains as it traverses the graph. A larger value increases the chances of finding the true nearest neighbors (higher recall) but also increases search latency. |
Type: Integer Range: [1, int_max] Default value: |
For a good balance between performance and accuracy, it is recommended to set this value to be equal to or slightly larger than the number of results you want to retrieve (top_k). |