HNSW_PRQ
HNSW_PRQ leverages Hierarchical Navigable Small World (HNSW) graphs with Product Residual Quantization (PRQ), offering an advanced vector indexing method that allows you to finely tune the trade-off between index size and accuracy. PRQ goes beyond traditional Product Quantization (PQ) by introducing a residual quantization (RQ) step to capture additional information, resulting in higher accuracy or more compact indexes compared to purely PQ-based methods. However, the extra steps can lead to higher computational overhead during index building and searching.
Overview
HNSW_PRQ combines two indexing techniques: HSNW for fast graph-based navigation and PRQ for efficient vector compression.
HNSW
HNSW constructs a multi-layer graph where each node corresponds to a vector in the dataset. In this graph, nodes are connected based on their similarity, enabling rapid traversal through the data space. The hierarchical structure allows the search algorithm to narrow down the candidate neighbors, significantly accelerating the search process in high-dimensional spaces.
For more information, refer to HNSW.
PRQ
PRQ is a multi-stage vector compression approach that combines two complementary techniques: PQ and RQ. By first splitting a high-dimensional vector into smaller sub-vectors (via PQ) and then quantizing any remaining difference (via RQ), PRQ achieves a compact yet accurate representation of the original data.
The following figure shows how it works.
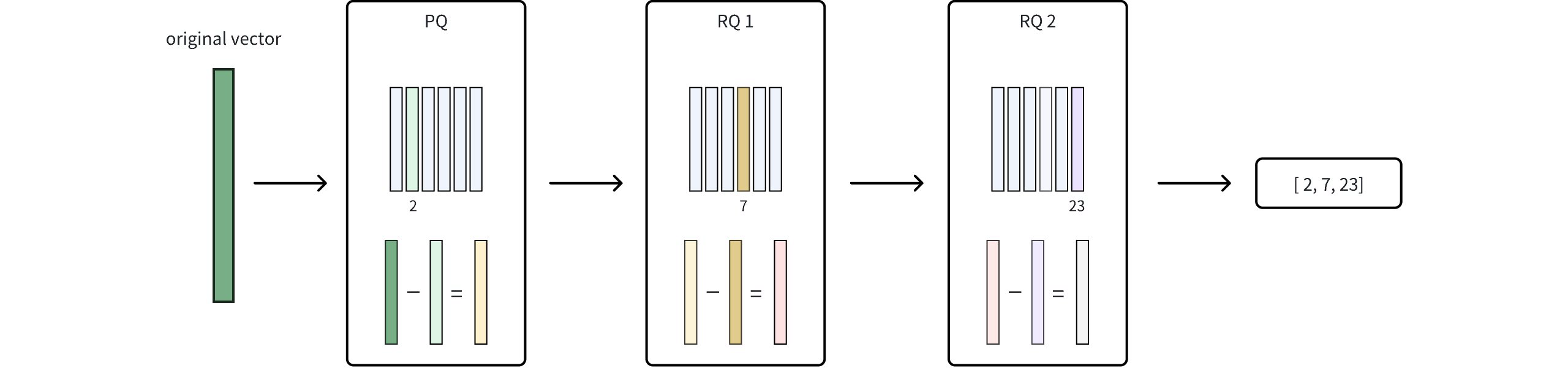 Hnsw Prq
Hnsw Prq
Product Quantization (PQ)
In this phase, the original vector is divided into smaller sub-vectors, and each sub-vector is mapped to its nearest centroid in a learned codebook. This mapping significantly reduces data size but introduces some rounding error since each sub-vector is approximated by a single centroid. For more details, refer to IVF_PQ.
Residual Quantization (RQ)
After the PQ stage, RQ quantizes the residual—the difference between the original vector and its PQ-based approximation—using additional codebooks. Because this residual is typically much smaller, it can be encoded more precisely without a large increase in storage.
The parameter
nrqdetermines how many times this residual is iteratively quantized, allowing you to fine-tune the balance between compression efficiency and accuracy.Final Compression Representation
Once RQ finishes quantizing the residual, the integer codes from both PQ and RQ are combined into a single compressed index. By capturing refined details that PQ alone might miss, RQ enhances accuracy without causing a significant increase in storage. This synergy between PQ and RQ is what defines PRQ.
HNSW + PRQ
By combining HNSW with PRQ, HNSW_PRQ retains HNSW’s fast graph-based search while taking advantage of PRQ’s multi-stage compression. The workflow looks like this:
Data Compression: Each vector is first transformed via PQ to a coarse representation, and then residuals are quantized through RQ for further refinement. The result is a set of compact codes representing each vector.
Graph Construction: The compressed vectors (including both the PQ and RQ codes) form the basis for building the HNSW graph. Because data is stored in a compact form, the graph requires less memory, and navigation through it is accelerated.
Candidate Retrieval: During search, HNSW uses the compressed representations to traverse the graph and retrieve a pool of candidates. This dramatically cuts down the number of vectors needing consideration.
(Optional) Result Refinement: The initial candidate results can be refined for better accuracy, based on the following parameters:
refine: Controls whether this refinement step is activated. When set totrue, the system recalculates distances using higher-precision or uncompressed representations.refine_type: Specifies the precision level of data used during refinement (e.g., SQ6, SQ8, BF16). A higher-precision choice such asFP32can yield more accurate results but requires more memory. This must exceed the precision of the original compressed data set bysq_type.refine_k: Acts as a magnification factor. For instance, if your top k is 100 andrefine_kis 2, the system re-ranks the top 200 candidates and returns the best 100, enhancing overall accuracy.
For a full list of parameters and valid values, refer to Index params.
Build index
To build an HNSW_PRQ index on a vector field in Milvus, use the add_index() method, specifying the index_type, metric_type, and additional parameters for the index.
from pymilvus import MilvusClient
# Prepare index building params
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="HNSW_PRQ", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"M": 30, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 360, # Number of candidate neighbors considered for connection during index construction
"m": 384,
"nbits": 8,
"nrq": 1,
"refine": true, # Whether to enable the refinement step
"refine_type": "SQ8" # Precision level of data used for refinement
} # Index building params
)
In this configuration:
index_type: The type of index to be built. In this example, set the value toHNSW_PQ.metric_type: The method used to calculate the distance between vectors. Supported values includeCOSINE,L2, andIP. For details, refer to Metric Types.params: Additional configuration options for building the index. For details, refer to Index building params.
Once the index parameters are configured, you can create the index by using the create_index() method directly or passing the index params in the create_collection method. For details, refer to Create Collection.
Search on index
Once the index is built and entities are inserted, you can perform similarity searches on the index.
search_params = {
"params": {
"ef": 10, # Parameter controlling query time/accuracy trade-off
"refine_k": 1 # The magnification factor
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # Collection name
anns_field="vector_field", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
limit=3, # TopK results to return
search_params=search_params
)
In this configuration:
params: Additional configuration options for searching on the index. For details, refer to Index-specific search params.
Index params
This section provides an overview of the parameters used for building an index and performing searches on the index.
Index building params
The following table lists the parameters that can be configured in params when building an index.
Parameter |
Description |
Value Range |
Tuning Suggestion |
|
|---|---|---|---|---|
HNSW |
|
Maximum number of connections (or edges) each node can have in the graph, including both outgoing and incoming edges. This parameter directly affects both index construction and search. |
Type: Integer Range: [2, 2048] Default value: |
A larger Consider decreasing In most cases, we recommend you set a value within this range: [5, 100]. |
|
Number of candidate neighbors considered for connection during index construction.
A larger pool of candidates is evaluated for each new element, but the maximum number of connections actually established is still limited by |
Type: Integer Range: [1, int_max] Default value: |
A higher Consider decreasing In most cases, we recommend you set a value within this range: [50, 500]. |
|
PRQ |
|
The number of sub-vectors (used for quantization) to divide each high-dimensional vector into during the quantization process. |
Type: Integer Range: [1, 65536] Default value: None |
A higher In most cases, we recommend you set a value within this range: [D/8, D]. |
|
The number of bits used to represent each sub-vector's centroid index in the compressed form. It directly determines the size of each codebook.
Each codebook will contain 2nbits centroids. For example, if |
Type: Integer Range: [1, 24] Default value: |
A higher |
|
|
Controls how many residual subquantizers are used in the RQ stage. More subquantizers potentially achieve greater compression but might introduce more information loss. |
Type: Integer Range: [1, 16] Default value: |
A higher |
|
|
A boolean flag that controls whether a refinement step is applied during search. Refinement involves reranking the initial results by computing exact distances between the query vector and candidates. |
Type: Boolean
Range: [ Default value: |
Set to |
|
|
Determines the precision of the data used during the refinement process.
This precision must be higher than that of the compressed vectors (as set by |
Type: String
Range:[ Default value: None |
Use |
Index-specific search params
The following table lists the parameters that can be configured in search_params.params when searching on the index.
Parameter |
Description |
Value Range |
Tuning Suggestion |
|
|---|---|---|---|---|
HNSW |
|
Controls the breadth of search during nearest neighbor retrieval. It determines how many nodes are visited and evaluated as potential nearest neighbors. This parameter affects only the search process and applies exclusively to the bottom layer of the graph. |
Type: Integer Range: [1, int_max] Default value: limit (TopK nearest neighbors to return) |
A larger Consider decreasing In most cases, we recommend you set a value within this range: [K, 10K]. |
PRQ |
|
The magnification factor that controls how many extra candidates are examined during the refinement (reranking) stage, relative to the requested top K results. |
Type: Float Range: [1, float_max) Default value: 1 |
Higher values of |