Build RAG with Milvus
![]()
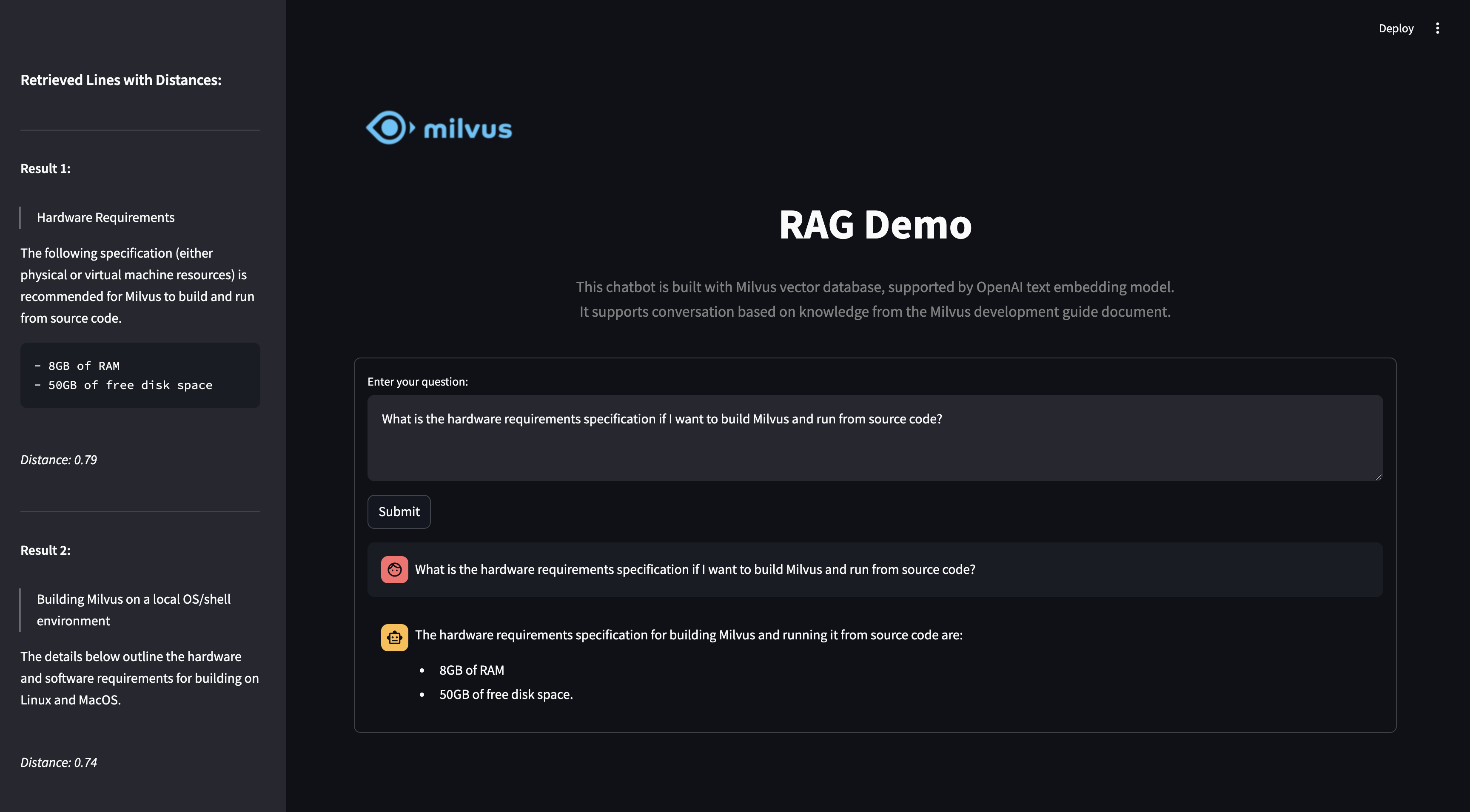
In this tutorial, we will show you how to build a RAG(Retrieval-Augmented Generation) pipeline with Milvus.
The RAG system combines a retrieval system with a generative model to generate new text based on a given prompt. The system first retrieves relevant documents from a corpus using Milvus, and then uses a generative model to generate new text based on the retrieved documents.
Preparation
Dependencies and Environment
$ pip install --upgrade pymilvus openai requests tqdm
If you are using Google Colab, to enable dependencies just installed, you may need to restart the runtime. (Click on the “Runtime” menu at the top of the screen, and select “Restart session” from the dropdown menu).
We will use OpenAI as the LLM in this example. You should prepare the api key OPENAI_API_KEY as an environment variable.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
Prepare the data
We use the FAQ pages from the Milvus Documentation 2.4.x as the private knowledge in our RAG, which is a good data source for a simple RAG pipeline.
Download the zip file and extract documents to the folder milvus_docs.
$ wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
$ unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
We load all markdown files from the folder milvus_docs/en/faq. For each document, we just simply use "# " to separate the content in the file, which can roughly separate the content of each main part of the markdown file.
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
Prepare the Embedding Model
We initialize the OpenAI client to prepare the embedding model.
from openai import OpenAI
openai_client = OpenAI()
Define a function to generate text embeddings using OpenAI client. We use the text-embedding-3-small model as an example.
def emb_text(text):
return (
openai_client.embeddings.create(input=text, model="text-embedding-3-small")
.data[0]
.embedding
)
Generate a test embedding and print its dimension and first few elements.
test_embedding = emb_text("This is a test")
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
1536
[0.00988506618887186, -0.005540902726352215, 0.0068014683201909065, -0.03810417652130127, -0.018254263326525688, -0.041231658309698105, -0.007651153020560741, 0.03220026567578316, 0.01892443746328354, 0.00010708322952268645]
Load data into Milvus
Create the Collection
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
As for the argument of MilvusClient:
- Setting the
urias a local file, e.g../milvus.db, is the most convenient method, as it automatically utilizes Milvus Lite to store all data in this file. - If you have large scale of data, you can set up a more performant Milvus server on docker or kubernetes. In this setup, please use the server uri, e.g.
http://localhost:19530, as youruri. - If you want to use Zilliz Cloud, the fully managed cloud service for Milvus, adjust the
uriandtoken, which correspond to the Public Endpoint and Api key in Zilliz Cloud.
Check if the collection already exists and drop it if it does.
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
Create a new collection with specified parameters.
If we don’t specify any field information, Milvus will automatically create a default id field for primary key, and a vector field to store the vector data. A reserved JSON field is used to store non-schema-defined fields and their values.
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
)
Insert data
Iterate through the text lines, create embeddings, and then insert the data into Milvus.
Here is a new field text, which is a non-defined field in the collection schema. It will be automatically added to the reserved JSON dynamic field, which can be treated as a normal field at a high level.
from tqdm import tqdm
data = []
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": emb_text(line), "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Creating embeddings: 100%|██████████| 72/72 [00:27<00:00, 2.67it/s]
{'insert_count': 72,
'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71],
'cost': 0}
Build RAG
Retrieve data for a query
Let’s specify a frequent question about Milvus.
question = "How is data stored in milvus?"
Search for the question in the collection and retrieve the semantic top-3 matches.
search_res = milvus_client.search(
collection_name=collection_name,
data=[
emb_text(question)
], # Use the `emb_text` function to convert the question to an embedding vector
limit=3, # Return top 3 results
search_params={"metric_type": "IP", "params": {}}, # Inner product distance
output_fields=["text"], # Return the text field
)
Let’s take a look at the search results of the query
import json
retrieved_lines_with_distances = [
(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
0.7883545756340027
],
[
"How does Milvus handle vector data types and precision?\n\nMilvus supports Binary, Float32, Float16, and BFloat16 vector types.\n\n- Binary vectors: Store binary data as sequences of 0s and 1s, used in image processing and information retrieval.\n- Float32 vectors: Default storage with a precision of about 7 decimal digits. Even Float64 values are stored with Float32 precision, leading to potential precision loss upon retrieval.\n- Float16 and BFloat16 vectors: Offer reduced precision and memory usage. Float16 is suitable for applications with limited bandwidth and storage, while BFloat16 balances range and efficiency, commonly used in deep learning to reduce computational requirements without significantly impacting accuracy.\n\n###",
0.6757288575172424
],
[
"How much does Milvus cost?\n\nMilvus is a 100% free open-source project.\n\nPlease adhere to [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0) when using Milvus for production or distribution purposes.\n\nZilliz, the company behind Milvus, also offers a fully managed cloud version of the platform for those that don't want to build and maintain their own distributed instance. [Zilliz Cloud](https://zilliz.com/cloud) automatically maintains data reliability and allows users to pay only for what they use.\n\n###",
0.6421123147010803
]
]
Use LLM to get a RAG response
Convert the retrieved documents into a string format.
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
Define system and user prompts for the Language Model. This prompt is assembled with the retrieved documents from Milvus.
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
Use OpenAI ChatGPT to generate a response based on the prompts.
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response.choices[0].message.content)
Milvus stores data in persistent storage as incremental logs, including inserted data (vector data, scalar data, and collection-specific schema) and metadata. Inserted data is stored in various object storage backends like MinIO, AWS S3, Google Cloud Storage, Azure Blob Storage, Alibaba Cloud OSS, and Tencent Cloud Object Storage. Metadata generated within Milvus is stored in etcd.
Quick Deploy
To learn about how to start an online demo with this tutorial, please refer to the example application.