Aperçu de la migration Milvus
Reconnaissant les divers besoins de sa base d'utilisateurs, Milvus a étendu ses outils de migration pour faciliter non seulement les mises à niveau à partir des versions antérieures de Milvus 1.x, mais aussi pour permettre l'intégration transparente des données provenant d'autres systèmes tels qu'Elasticsearch et Faiss. Le projet Milvus-migration est conçu pour combler le fossé entre ces divers environnements de données et les dernières avancées de la technologie Milvus, afin que vous puissiez exploiter les fonctionnalités et les performances améliorées de manière transparente.
Migrations prises en charge
L'outil Milvus-migration prend en charge une variété de chemins de migration pour répondre aux différents besoins des utilisateurs :
- Elasticsearch vers Milvus 2.x: Permet aux utilisateurs de migrer des données à partir d'environnements Elasticsearch pour tirer parti des capacités de recherche vectorielle optimisée de Milvus.
- Faiss vers Milvus 2.x: Prise en charge expérimentale du transfert de données à partir de Faiss, une bibliothèque populaire pour la recherche efficace de similarités.
- Milvus 1.x vers Milvus 2.x: Assurer une transition en douceur des données des versions antérieures vers le cadre le plus récent.
- Milvus 2.3.x vers Milvus 2.3.x ou supérieur: Fournir un chemin de migration unique pour les utilisateurs qui ont déjà migré vers 2.3.x.
Caractéristiques
Milvus-migration est conçu avec des fonctionnalités robustes pour gérer divers scénarios de migration :
- Méthodes d'interaction multiples : Vous pouvez effectuer des migrations via une interface de ligne de commande ou via une API Restful, avec une flexibilité dans la manière dont les migrations sont exécutées.
- Prise en charge de divers formats de fichiers et du stockage en nuage : L'outil Milvus-migration peut traiter des données stockées dans des fichiers locaux ainsi que dans des solutions de stockage en nuage telles que S3, OSS et GCP, ce qui garantit une large compatibilité.
- Traitement des types de données : Milvus-migration est capable de traiter des données vectorielles et des champs scalaires, ce qui en fait un choix polyvalent pour différents besoins de migration de données.
Architecture de Milvus-migration
L'architecture de Milvus-migration est stratégiquement conçue pour faciliter les processus efficaces de streaming, d'analyse et d'écriture des données, ce qui permet des capacités de migration robustes dans diverses sources de données.
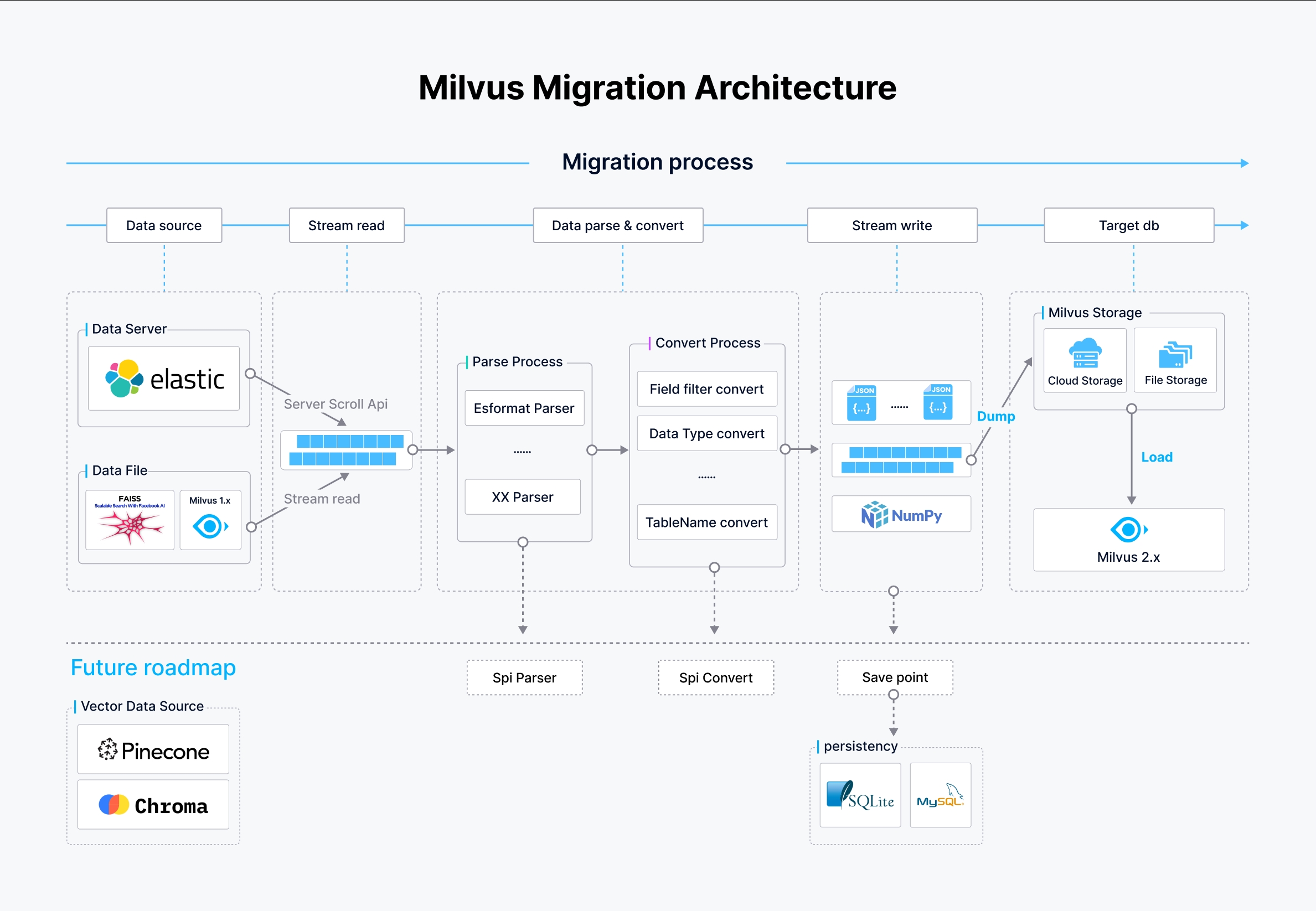 Architecture de Milvus-migration
Architecture de Milvus-migration
Dans la figure précédente :
- Source de données: Milvus-migration prend en charge plusieurs sources de données, notamment Elasticsearch via l'API de défilement, les fichiers de données de stockage local ou dans le nuage et les bases de données de Milvus 1.x. Ces sources sont accédées et lues dans un flux de données. Ces sources sont consultées et lues de manière rationalisée pour lancer le processus de migration.
- Pipeline de flux:
- Processus d'analyse: Les données provenant des sources sont analysées en fonction de leur format. Par exemple, pour une source de données provenant d'Elasticsearch, un analyseur de format Elasticsearch est utilisé, tandis que d'autres formats utilisent des analyseurs respectifs. Cette étape est cruciale pour transformer les données brutes en un format structuré qui peut être traité ultérieurement.
- Processus de conversion: Après l'analyse syntaxique, les données sont converties : les champs sont filtrés, les types de données sont convertis et les noms de tables sont ajustés en fonction du schéma cible Milvus 2.x. Cela garantit que les données sont conformes à la structure et aux types attendus dans Milvus.
- Écriture et chargement des données:
- Écriture des données: Les données traitées sont écrites dans des fichiers JSON ou NumPy intermédiaires, prêts à être chargés dans Milvus 2.x.
- Chargement des données: Les données sont finalement chargées dans Milvus 2.x à l'aide de l'opération BulkInsert, qui écrit efficacement de grands volumes de données dans les systèmes de stockage Milvus, qu'ils soient basés sur le cloud ou sur un dépôt de fichiers.
Projets futurs
L'équipe de développement s'est engagée à améliorer Milvus-migration avec des fonctionnalités telles que :
- Prise en charge d'un plus grand nombre de sources de données: Il est prévu d'étendre la prise en charge à d'autres bases de données et systèmes de fichiers, tels que Pinecone, Chroma, Qdrant. Si vous avez besoin de la prise en charge d'une source de données spécifique, veuillez soumettre votre demande via ce lien GitHub issue.
- Simplification des commandes: Efforts pour rationaliser le processus de commande pour une exécution plus facile.
- SPI parser / convertir: L'architecture prévoit d'inclure des outils SPI (Service Provider Interface) pour l'analyse et la conversion. Ces outils permettent des implémentations personnalisées que les utilisateurs peuvent intégrer dans le processus de migration pour gérer des formats de données ou des règles de conversion spécifiques.
- Reprise au point de contrôle: Permet aux migrations de reprendre à partir du dernier point de contrôle afin d'améliorer la fiabilité et l'efficacité en cas d'interruption. Des points de sauvegarde sont créés pour garantir l'intégrité des données et sont stockés dans des bases de données telles que SQLite ou MySQL pour suivre la progression du processus de migration.