Explication du schéma
Un schéma définit la structure des données d'une collection. Avant de créer une collection, vous devez concevoir son schéma. Cette page vous aide à comprendre le schéma d'une collection et à concevoir un exemple de schéma par vous-même.
Vue d'ensemble
Dans Milvus, un schéma de collection assemble une table dans une base de données relationnelle, qui définit la manière dont Milvus organise les données dans la collection.
Un schéma bien conçu est essentiel car il abstrait le modèle de données et décide si vous pouvez atteindre les objectifs de l'entreprise par le biais d'une recherche. En outre, étant donné que chaque ligne de données insérée dans la collection doit respecter le schéma, celui-ci contribue à maintenir la cohérence des données et la qualité à long terme. D'un point de vue technique, un schéma bien défini permet un stockage des données en colonnes bien organisé et une structure d'index plus propre, ce qui améliore les performances de recherche.
Un schéma de collection comporte une clé primaire, au moins un champ vectoriel et plusieurs champs scalaires. Le diagramme suivant illustre la manière de faire correspondre un article à une liste de champs de schéma.
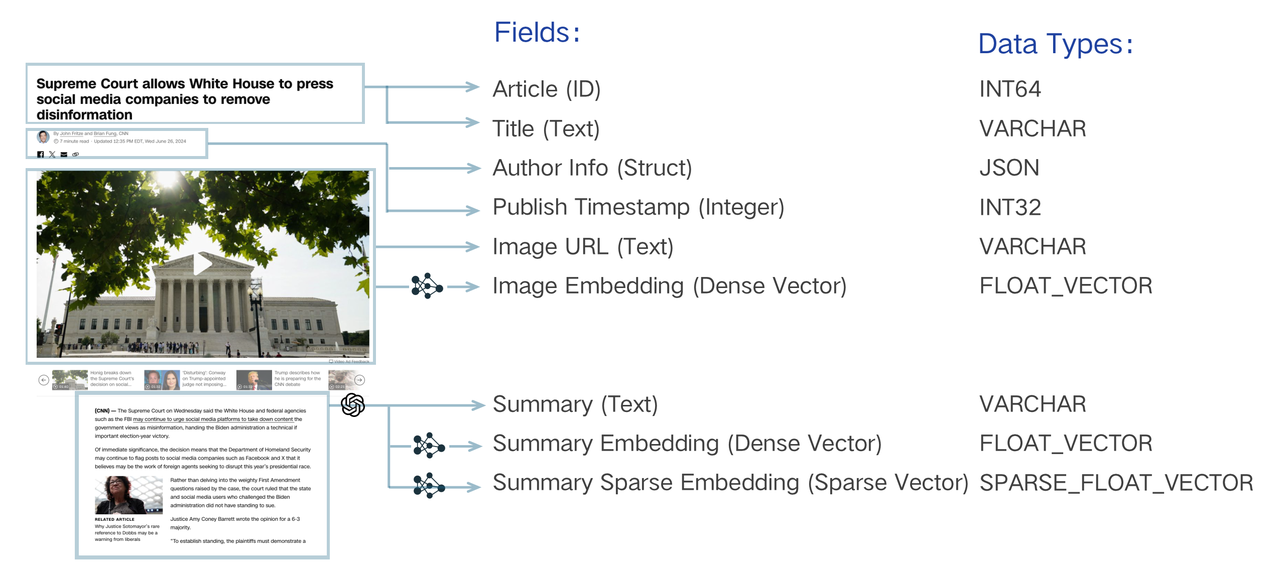 Anatomie de la conception des schémas
Anatomie de la conception des schémas
La conception du modèle de données d'un système de recherche implique l'analyse des besoins de l'entreprise et l'abstraction des informations dans un modèle de données exprimé par un schéma. Par exemple, la recherche d'un morceau de texte doit être "indexée" en convertissant la chaîne littérale en un vecteur par "incorporation" et en permettant la recherche vectorielle. Au-delà de cette exigence essentielle, il peut être nécessaire de stocker d'autres propriétés telles que l'horodatage de la publication et l'auteur. Ces métadonnées permettent d'affiner les recherches sémantiques par filtrage, en ne renvoyant que les textes publiés après une date spécifique ou par un auteur particulier. Vous pouvez également récupérer ces scalaires avec le texte principal pour rendre le résultat de la recherche dans l'application. Un identifiant unique doit être attribué à chaque scalaire pour organiser ces morceaux de texte, sous la forme d'un nombre entier ou d'une chaîne de caractères. Ces éléments sont essentiels pour obtenir une logique de recherche sophistiquée.
Reportez-vous à Schema Design Hands-On pour savoir comment créer un schéma bien conçu.
Créer un schéma
L'extrait de code suivant montre comment créer un schéma.
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const schema = []
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
export schema='{
"fields": []
}'
Ajouter un champ primaire
Le champ primaire d'une collection identifie de manière unique une entité. Il n'accepte que les valeurs Int64 ou VarChar. Les extraits de code suivants montrent comment ajouter un champ primaire.
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("my_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.push({
name: "my_id",
data_type: DataType.Int64,
is_primary_key: true,
autoID: false
});
schema.WithField(entity.NewField().WithName("my_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(false),
)
export primaryField='{
"fieldName": "my_id",
"dataType": "Int64",
"isPrimary": true
}'
export schema='{
\"autoID\": false,
\"fields\": [
$primaryField
]
}'
Lors de l'ajout d'un champ, vous pouvez explicitement préciser qu'il s'agit du champ primaire en définissant sa propriété is_primary sur True. Un champ primaire accepte par défaut les valeurs Int64. Dans ce cas, la valeur du champ primaire doit être un entier, comme dans 12345. Si vous choisissez d'utiliser des valeurs VarChar dans le champ primaire, la valeur doit être une chaîne de caractères, comme dans my_entity_1234.
Vous pouvez également définir les propriétés autoId sur True pour que Milvus attribue automatiquement des valeurs de champ primaire lors des insertions de données.
Il est conseillé de se fier à autoId dans tous les cas, à moins que la définition manuelle des clés primaires ne soit avantageuse.
Pour plus de détails, voir Champ primaire & AutoId.
Ajouter des champs vectoriels
Les champs vectoriels acceptent diverses intégrations de vecteurs denses et éparses. Sur Milvus, vous pouvez ajouter quatre champs vectoriels à une collection. Les extraits de code suivants montrent comment ajouter un champ vectoriel.
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
schema.addField(AddFieldReq.builder()
.fieldName("my_vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.push({
name: "my_vector",
data_type: DataType.FloatVector,
dim: 5
});
schema.WithField(entity.NewField().WithName("my_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
export vectorField='{
"fieldName": "my_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField
]
}"
Le paramètre dim dans les extraits de code ci-dessus indique la dimensionnalité des encastrements vectoriels à conserver dans le champ vectoriel. La valeur FLOAT_VECTOR indique que le champ vectoriel contient une liste de nombres flottants 32 bits, qui sont généralement utilisés pour représenter les antilogarithmes.En outre, Milvus prend également en charge les types suivants d'incrustations vectorielles :
FLOAT16_VECTORUn champ vectoriel de ce type contient une liste de nombres flottants en demi-précision sur 16 bits et s'applique généralement à des scénarios d'apprentissage profond ou de calcul basé sur le GPU limités par la mémoire ou la bande passante.
BFLOAT16_VECTORUn champ vectoriel de ce type contient une liste de nombres à virgule flottante de 16 bits qui ont une précision réduite mais la même plage d'exposants que Float32. Ce type de données est couramment utilisé dans les scénarios d'apprentissage profond, car il réduit l'utilisation de la mémoire sans avoir d'impact significatif sur la précision.
INT8_VECTORUn champ vectoriel de ce type stocke des vecteurs composés d'entiers signés sur 8 bits (int8), chaque composante étant comprise entre -128 et 127. Adapté aux architectures d'apprentissage profond quantifiées, telles que ResNet et EfficientNet, il réduit considérablement la taille du modèle et augmente la vitesse d'inférence, tout en ne subissant qu'une perte de précision minime. Remarque: ce type de vecteur n'est pris en charge que pour les index HNSW.
BINARY_VECTORUn champ vectoriel de ce type contient une liste de 0 et de 1. Ils servent de caractéristiques compactes pour représenter les données dans les scénarios de traitement d'images et de recherche d'informations.
SPARSE_FLOAT_VECTORUn champ vectoriel de ce type contient une liste de nombres non nuls et leurs numéros de séquence afin de représenter des encastrements vectoriels épars.
Ajouter des champs scalaires
Dans des cas courants, vous pouvez utiliser des champs scalaires pour stocker les métadonnées des intégrations vectorielles stockées dans Milvus et effectuer des recherches ANN avec filtrage des métadonnées pour améliorer l'exactitude des résultats de la recherche. Milvus prend en charge plusieurs types de champs scalaires, notamment VarChar, Boolean, Int, Float et Double.
Ajout de champs de type chaîne
Dans Milvus, vous pouvez utiliser des champs VarChar pour stocker des chaînes de caractères. Pour plus d'informations sur le champ VarChar, reportez-vous à la section Champ de chaîne.
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512
)
schema.addField(AddFieldReq.builder()
.fieldName("my_varchar")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
schema.push({
name: "my_varchar",
data_type: DataType.VarChar,
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_varchar").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
export varCharField='{
"fieldName": "my_varchar",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField
]
}"
Ajout de champs numériques
Les types de nombres pris en charge par Milvus sont Int8, Int16, Int32, Int64, Float et Double. Pour plus d'informations sur les champs de nombres, voir Champ de nombres.
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_int64")
.dataType(DataType.Int64)
.build());
schema.push({
name: "my_int64",
data_type: DataType.Int64,
});
schema.WithField(entity.NewField().WithName("my_int64").
WithDataType(entity.FieldTypeInt64),
)
export int64Field='{
"fieldName": "my_int64",
"dataType": "Int64"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field
]
}"
Ajouter des champs booléens
Milvus prend en charge les champs booléens. Les extraits de code suivants montrent comment ajouter un champ booléen.
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_bool")
.dataType(DataType.Bool)
.build());
schema.push({
name: "my_bool",
data_type: DataType.Boolean,
});
schema.WithField(entity.NewField().WithName("my_bool").
WithDataType(entity.FieldTypeBool),
)
export boolField='{
"fieldName": "my_bool",
"dataType": "Boolean"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField
]
}"
Ajout de champs composites
Dans Milvus, un champ composite est un champ qui peut être divisé en sous-champs plus petits, tels que les clés dans un champ JSON ou les indices dans un champ Tableau.
Ajouter des champs JSON
Un champ JSON stocke généralement des données JSON semi-structurées. Pour en savoir plus sur les champs JSON, voir Champ JSON.
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_json")
.dataType(DataType.JSON)
.build());
schema.push({
name: "my_json",
data_type: DataType.JSON,
});
schema.WithField(entity.NewField().WithName("my_json").
WithDataType(entity.FieldTypeJSON),
)
export jsonField='{
"fieldName": "my_json",
"dataType": "JSON"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField
]
}"
Ajouter des champs de type tableau
Un champ de type tableau stocke une liste d'éléments. Les types de données de tous les éléments d'un champ tableau doivent être identiques. Pour plus d'informations sur les champs de type tableau, voir Champ de type tableau.
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_array")
.dataType(DataType.Array)
.elementType(DataType.VarChar)
.maxCapacity(5)
.maxLength(512)
.build());
schema.push({
name: "my_array",
data_type: DataType.Array,
element_type: DataType.VarChar,
max_capacity: 5,
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_array").
WithDataType(entity.FieldTypeArray).
WithElementType(entity.FieldTypeInt64).
WithMaxLength(512).
WithMaxCapacity(5),
)
export arrayField='{
"fieldName": "my_array",
"dataType": "Array",
"elementDataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField,
$arrayField
]
}"