![]()
Búsqueda híbrida con Milvus
Si desea experimentar el efecto final de este tutorial, puede ir directamente a https://demos.milvus.io/hybrid-search/.
En este tutorial, demostraremos cómo realizar una búsqueda híbrida con Milvus y el modelo BGE-M3. El modelo BGE-M3 puede convertir texto en vectores densos y dispersos. Milvus admite el almacenamiento de ambos tipos de vectores en una colección, lo que permite una búsqueda híbrida que mejora la relevancia de los resultados.
Milvus admite métodos de recuperación densos, dispersos e híbridos:
- Recuperación densa: Utiliza el contexto semántico para comprender el significado de las consultas.
- Recuperación dispersa: Hace hincapié en la concordancia de palabras clave para encontrar resultados basados en términos específicos, lo que equivale a una búsqueda de texto completo.
- Recuperación híbrida: Combina los enfoques Dense y Sparse, capturando el contexto completo y las palabras clave específicas para obtener resultados de búsqueda completos.
Al integrar estos métodos, la búsqueda híbrida de Milvus equilibra las similitudes semánticas y léxicas, mejorando la relevancia global de los resultados de la búsqueda. Este cuaderno mostrará el proceso de configuración y uso de estas estrategias de recuperación, destacando su eficacia en varios escenarios de búsqueda.
Dependencias y entorno
$ pip install --upgrade pymilvus "pymilvus[model]"
Descargar conjunto de datos
Para demostrar la búsqueda, necesitamos un corpus de documentos. Utilizaremos el conjunto de datos Quora Duplicate Questions y lo colocaremos en el directorio local.
Fuente del conjunto de datos: Primera versión del conjunto de datos de Quora: Pares de Preguntas
# Run this cell to download the dataset
$ wget http://qim.fs.quoracdn.net/quora_duplicate_questions.tsv
Cargar y preparar los datos
Cargaremos el conjunto de datos y prepararemos un pequeño corpus para la búsqueda.
import pandas as pd
file_path = "quora_duplicate_questions.tsv"
df = pd.read_csv(file_path, sep="\t")
questions = set()
for _, row in df.iterrows():
obj = row.to_dict()
questions.add(obj["question1"][:512])
questions.add(obj["question2"][:512])
if len(questions) > 500: # Skip this if you want to use the full dataset
break
docs = list(questions)
# example question
print(docs[0])
What is the strongest Kevlar cord?
Uso del modelo BGE-M3 para la incrustación
El modelo BGE-M3 puede incrustar textos como vectores densos y dispersos.
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
dense_dim = ef.dim["dense"]
# Generate embeddings using BGE-M3 model
docs_embeddings = ef(docs)
Fetching 30 files: 100%|██████████| 30/30 [00:00<00:00, 302473.85it/s]
Inference Embeddings: 100%|██████████| 32/32 [01:59<00:00, 3.74s/it]
Configurar la colección Milvus y el índice
Configuraremos la colección Milvus y crearemos índices para los campos vectoriales.
- Establecer la uri como un archivo local, por ejemplo "./milvus.db", es el método más conveniente, ya que utiliza automáticamente Milvus Lite para almacenar todos los datos en este archivo.
- Si tiene una gran escala de datos, digamos más de un millón de vectores, puede configurar un servidor Milvus más eficiente en Docker o Kubernetes. En esta configuración, por favor, utilice la uri del servidor, por ejemplo.http://localhost:19530, como su uri.
- Si desea utilizar Zilliz Cloud, el servicio en la nube totalmente gestionado para Milvus, ajuste la uri y el token, que se corresponden con el Public Endpoint y la clave API en Zilliz Cloud.
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
# Connect to Milvus given URI
connections.connect(uri="./milvus.db")
# Specify the data schema for the new Collection
fields = [
# Use auto generated id as primary key
FieldSchema(
name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100
),
# Store the original text to retrieve based on semantically distance
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512),
# Milvus now supports both sparse and dense vectors,
# we can store each in a separate field to conduct hybrid search on both vectors
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=dense_dim),
]
schema = CollectionSchema(fields)
# Create collection (drop the old one if exists)
col_name = "hybrid_demo"
if utility.has_collection(col_name):
Collection(col_name).drop()
col = Collection(col_name, schema, consistency_level="Bounded")
# To make vector search efficient, we need to create indices for the vector fields
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
col.create_index("sparse_vector", sparse_index)
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
col.create_index("dense_vector", dense_index)
col.load()
Insertar datos en la colección Milvus
Inserte documentos y sus incrustaciones en la colección.
# For efficiency, we insert 50 records in each small batch
for i in range(0, len(docs), 50):
batched_entities = [
docs[i : i + 50],
docs_embeddings["sparse"][i : i + 50],
docs_embeddings["dense"][i : i + 50],
]
col.insert(batched_entities)
print("Number of entities inserted:", col.num_entities)
Number of entities inserted: 502
Introduzca su consulta de búsqueda
# Enter your search query
query = input("Enter your search query: ")
print(query)
# Generate embeddings for the query
query_embeddings = ef([query])
# print(query_embeddings)
How to start learning programming?
Ejecutar la búsqueda
Primero prepararemos algunas funciones útiles para ejecutar la búsqueda:
dense_searchBuscar sólo en un campo vectorial densosparse_searchbuscar sólo en campos vectoriales dispersoshybrid_searchbúsqueda en campos vectoriales densos y dispersos con un reordenador ponderado
from pymilvus import (
AnnSearchRequest,
WeightedRanker,
)
def dense_search(col, query_dense_embedding, limit=10):
search_params = {"metric_type": "IP", "params": {}}
res = col.search(
[query_dense_embedding],
anns_field="dense_vector",
limit=limit,
output_fields=["text"],
param=search_params,
)[0]
return [hit.get("text") for hit in res]
def sparse_search(col, query_sparse_embedding, limit=10):
search_params = {
"metric_type": "IP",
"params": {},
}
res = col.search(
[query_sparse_embedding],
anns_field="sparse_vector",
limit=limit,
output_fields=["text"],
param=search_params,
)[0]
return [hit.get("text") for hit in res]
def hybrid_search(
col,
query_dense_embedding,
query_sparse_embedding,
sparse_weight=1.0,
dense_weight=1.0,
limit=10,
):
dense_search_params = {"metric_type": "IP", "params": {}}
dense_req = AnnSearchRequest(
[query_dense_embedding], "dense_vector", dense_search_params, limit=limit
)
sparse_search_params = {"metric_type": "IP", "params": {}}
sparse_req = AnnSearchRequest(
[query_sparse_embedding], "sparse_vector", sparse_search_params, limit=limit
)
rerank = WeightedRanker(sparse_weight, dense_weight)
res = col.hybrid_search(
[sparse_req, dense_req], rerank=rerank, limit=limit, output_fields=["text"]
)[0]
return [hit.get("text") for hit in res]
Vamos a ejecutar tres búsquedas diferentes con las funciones definidas:
dense_results = dense_search(col, query_embeddings["dense"][0])
sparse_results = sparse_search(col, query_embeddings["sparse"][[0]])
hybrid_results = hybrid_search(
col,
query_embeddings["dense"][0],
query_embeddings["sparse"][[0]],
sparse_weight=0.7,
dense_weight=1.0,
)
Visualizar los resultados de la búsqueda
Para mostrar los resultados de las búsquedas densas, dispersas e híbridas, necesitamos algunas utilidades para dar formato a los resultados.
def doc_text_formatting(ef, query, docs):
tokenizer = ef.model.tokenizer
query_tokens_ids = tokenizer.encode(query, return_offsets_mapping=True)
query_tokens = tokenizer.convert_ids_to_tokens(query_tokens_ids)
formatted_texts = []
for doc in docs:
ldx = 0
landmarks = []
encoding = tokenizer.encode_plus(doc, return_offsets_mapping=True)
tokens = tokenizer.convert_ids_to_tokens(encoding["input_ids"])[1:-1]
offsets = encoding["offset_mapping"][1:-1]
for token, (start, end) in zip(tokens, offsets):
if token in query_tokens:
if len(landmarks) != 0 and start == landmarks[-1]:
landmarks[-1] = end
else:
landmarks.append(start)
landmarks.append(end)
close = False
formatted_text = ""
for i, c in enumerate(doc):
if ldx == len(landmarks):
pass
elif i == landmarks[ldx]:
if close:
formatted_text += "</span>"
else:
formatted_text += "<span style='color:red'>"
close = not close
ldx = ldx + 1
formatted_text += c
if close is True:
formatted_text += "</span>"
formatted_texts.append(formatted_text)
return formatted_texts
A continuación, podemos mostrar los resultados de la búsqueda en texto con resaltados:
from IPython.display import Markdown, display
# Dense search results
display(Markdown("**Dense Search Results:**"))
formatted_results = doc_text_formatting(ef, query, dense_results)
for result in dense_results:
display(Markdown(result))
# Sparse search results
display(Markdown("\n**Sparse Search Results:**"))
formatted_results = doc_text_formatting(ef, query, sparse_results)
for result in formatted_results:
display(Markdown(result))
# Hybrid search results
display(Markdown("\n**Hybrid Search Results:**"))
formatted_results = doc_text_formatting(ef, query, hybrid_results)
for result in formatted_results:
display(Markdown(result))
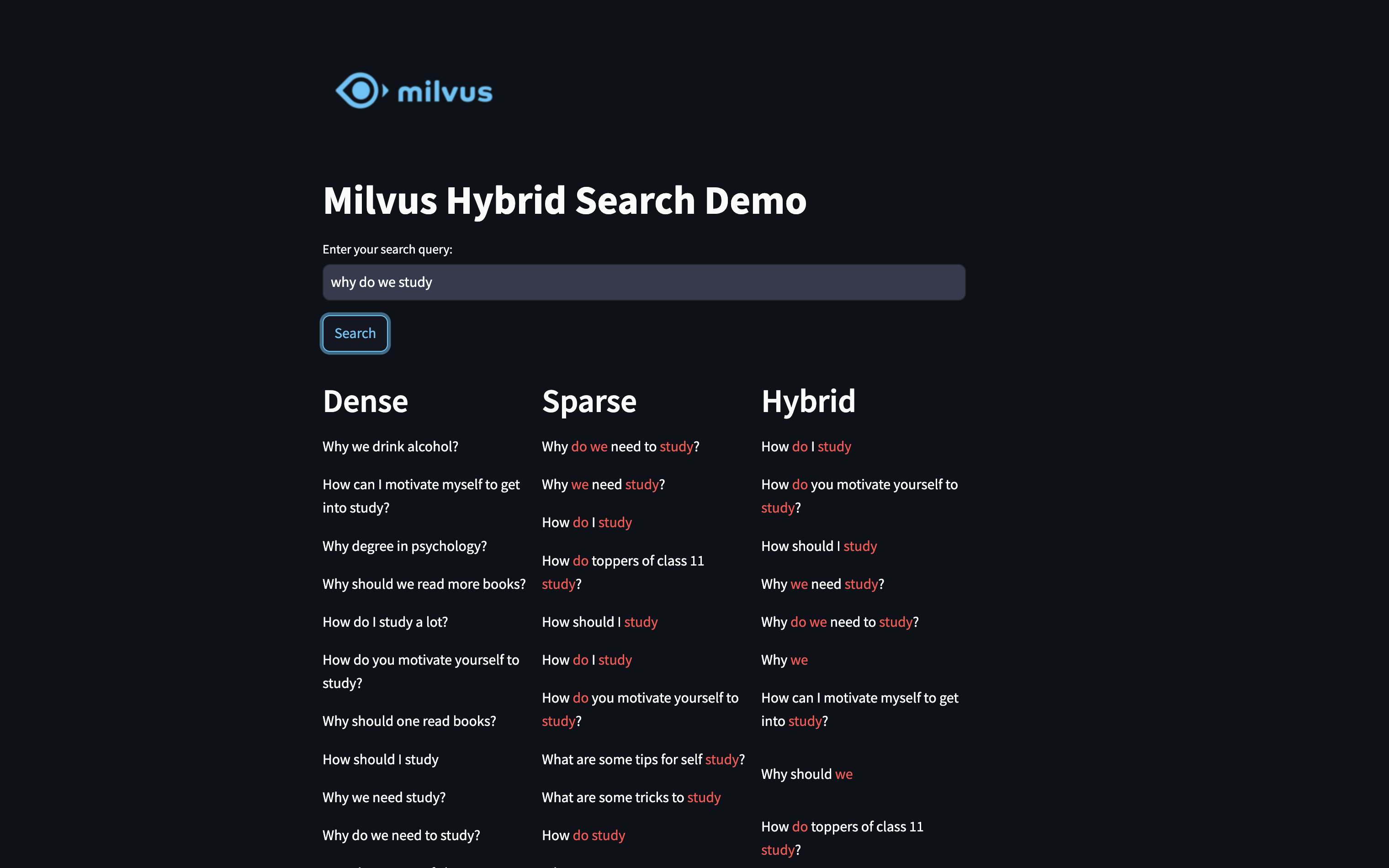
Resultados de búsqueda densos:
¿Cuál es la mejor manera de empezar a aprender robótica?
¿Cómo puedo aprender un lenguaje informático como java?
¿Cómo puedo empezar a aprender seguridad informática?
¿Qué es la programación en Java? ¿Cómo aprender el lenguaje de programación Java?
¿Cómo puedo aprender seguridad informática?
¿Cuál es la mejor manera de iniciarse en la robótica? ¿Cuál es la mejor placa de desarrollo con la que puedo empezar a trabajar?
¿Cómo puedo aprender a hablar inglés con fluidez?
¿Cuáles son las mejores formas de aprender francés?
¿Cómo se puede hacer que la física sea fácil de aprender?
¿Cómo nos preparamos para el UPSC?
Resultados de la búsqueda dispersa:
¿Qué es la programación Java? ¿Cómo aprender el lenguaje de programación Java?
¿Cuál es la mejor manera de empezar a aprender robótica?
¿Cuál es la alternativa al aprendizaje automático?
¿Cómo creo un nuevo Terminal y un nuevo shell en Linux usando programación en C?
¿Cómo puedo crear un nuevo shell en un nuevo terminal utilizando la programación C (terminal de Linux)?
¿Qué negocio es mejor empezar en Hyderabad?
¿Qué negocio es mejor para empezar en Hyderabad?
¿Cuál es la mejor forma de iniciarse en la robótica? ¿Cuál es la mejor placa de desarrollo con la que puedo empezar a trabajar?
¿Qué matemáticas necesita un novato para entender los algoritmos de programación informática? ¿Qué libros sobre algoritmos son adecuados para un completo principiante?
¿Cómo hacer que la vida se adapte a ti y que la vida deje de maltratarte mental y emocionalmente?
Resultados de la búsqueda híbrida:
¿Cuál es la mejor manera de iniciarse en la robótica? ¿Cuál es la mejor placa de desarrollo con la que puedo empezar a trabajar?
¿Qué es la programación Java? ¿Cómo aprender el lenguaje de programación Java?
¿Cuál es la mejor manera de empezar a aprender robótica?
¿Cómo nos preparamos para el UPSC?
¿Cómo hacer que la física sea fácil de aprender?
¿Cuáles son las mejores maneras de aprender francés?
¿Cómo puedo aprender a hablar inglés con fluidez?
¿Cómo puedo aprender seguridad informática?
¿Cómo puedo empezar a aprender seguridad informática?
¿Cómo puedo aprender un lenguaje informático como java?
¿Cuál es la alternativa al aprendizaje automático?
¿Cómo puedo crear un nuevo Terminal y un nuevo shell en Linux utilizando programación en C?
¿Cómo creo un nuevo shell en un nuevo terminal usando programación en C (terminal Linux)?
¿Qué negocio es mejor empezar en Hyderabad?
¿Qué negocio es mejor para empezar en Hyderabad?
¿Qué matemáticas necesita un novato para entender los algoritmos de programación informática? ¿Qué libros sobre algoritmos son adecuados para un principiante?
¿Cómo hacer que la vida se adapte a ti y evitar que la vida abuse de ti mental y emocionalmente?
Despliegue rápido
Para saber cómo iniciar una demostración en línea con este tutorial, consulte la aplicación de ejemplo.