Storage/Computing Disaggregation
Following the principle of data plane and control plane disaggregation, Milvus comprises four layers that are mutually independent in terms of scalability and disaster recovery.
Access layer
Composed of a group of stateless proxies, the access layer is the front layer of the system and endpoint to users. It validates client requests and reduces the returned results:
- The proxy is in itself stateless. It provides a unified service address using load balancing components such as Nginx, Kubernetes Ingress, NodePort, and LVS.
- As Milvus employs a massively parallel processing (MPP) architecture, the proxy aggregates and post-process the intermediate results before returning the final results to the client.
Coordinator service
The coordinator service assigns tasks to the worker nodes and functions as the system’s brain. The tasks it takes on include cluster topology management, load balancing, timestamp generation, data declaration, and data management.
There are three coordinator types: root coordinator (root coord), data coordinator (data coord), and query coordinator (query coord).
Root coordinator (root coord)
Root coord handles data definition language (DDL) and data control language (DCL) requests, such as create or delete collections, partitions, or indexes, as well as manage TSO (timestamp Oracle) and time ticker issuing.
Query coordinator (query coord)
Query coord manages topology and load balancing for the query nodes, and handoff from growing segments to sealed segments.
Data coordinator (data coord)
Data coord manages topology of the data nodes and index nodes, maintains metadata, and triggers flush, compact, and index building and other background data operations.
Worker nodes
Worker nodes are “dumb” executors that follow instructions from the coordinator service and execute data manipulation language (DML) commands from the proxy. Worker nodes are stateless thanks to separation of storage and computation, and can facilitate system scale-out and disaster recovery when deployed on Kubernetes. There are three types of worker nodes:
Query node
Query nodes retrieve incremental log data and turn them into growing segments by subscribing to the log broker, load historical data from the object storage, and run hybrid search between vector and scalar data.
Data node
Data nodes retrieve incremental log data by subscribing to the log broker, process mutation requests, and pack log data into log snapshots and stores them in the object storage.
Index node
Index nodes builds indices. They do not need to be memory resident, and can be implemented with the serverless framework.
Storage
Storage is the bone of the system, responsible for data persistence. It comprises meta storage, log broker, and object storage.
Meta storage
Meta storage stores snapshots of metadata such as collection schema, and message consumption checkpoints. Storing metadata demands extremely high availability, strong consistency, and transaction support, so Milvus chose etcd for this purpose. Milvus also uses etcd for service registration and health checks.
Object storage
Object storage stores snapshot files of logs, index files for scalar and vector data, and intermediate query results. Milvus uses MinIO as object storage and can be readily deployed on AWS S3 and Azure Blob, two of the world’s most popular, cost-effective storage services. However, object storage has high access latency and charges by the number of queries. To improve its performance and lower costs, Milvus plans to implement cold-hot data separation on a memory- or SSD-based cache pool.
Log broker
The log broker is a pub-sub system that supports playback. It is responsible for streaming data persistence and event notification. It also ensures integrity of the incremental data when the worker nodes recover from system breakdown. Milvus Distributed uses Pulsar as the log broker while Milvus Standalone uses RocksDB. The log broker can be readily replaced with streaming data storage platforms such as Kafka.
Milvus follows the “log as data” principle, so Milvus does not maintain a physical table but guarantees data reliability through logging persistence and snapshot logs.
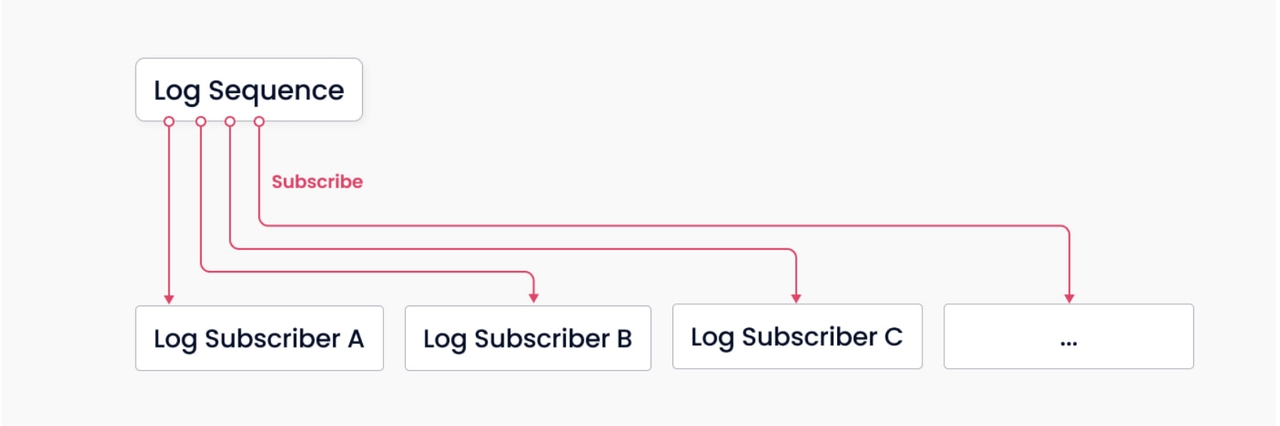 Log_mechanism
Log_mechanism
The log broker is the backbone of Milvus. It is responsible for data persistence and read-write disaggregation, thanks to its innate pub-sub mechanism. The above illustration shows a simplified depiction of the mechanism, where the system is divided into two roles, log broker (for maintaining the log sequence) and log subscriber. The former records all operations that change collection states; the latter subscribes to the log sequence to update the local data and provides services in the form of read-only copies. The pub-sub mechanism also makes room for system extendability in terms of change data capture (CDC) and globally-distributed deployment.
What’s next
- Read Main Components for more details about the Milvus architecture.