HNSW
Der HNSW-Index ist ein graphbasierter Indizierungsalgorithmus, der die Leistung bei der Suche nach hochdimensionalen fließenden Vektoren verbessern kann. Er bietet eine ausgezeichnete Suchgenauigkeit und eine geringe Latenzzeit, erfordert jedoch einen hohen Speicheraufwand, um seine hierarchische Graphenstruktur zu erhalten.
Überblick
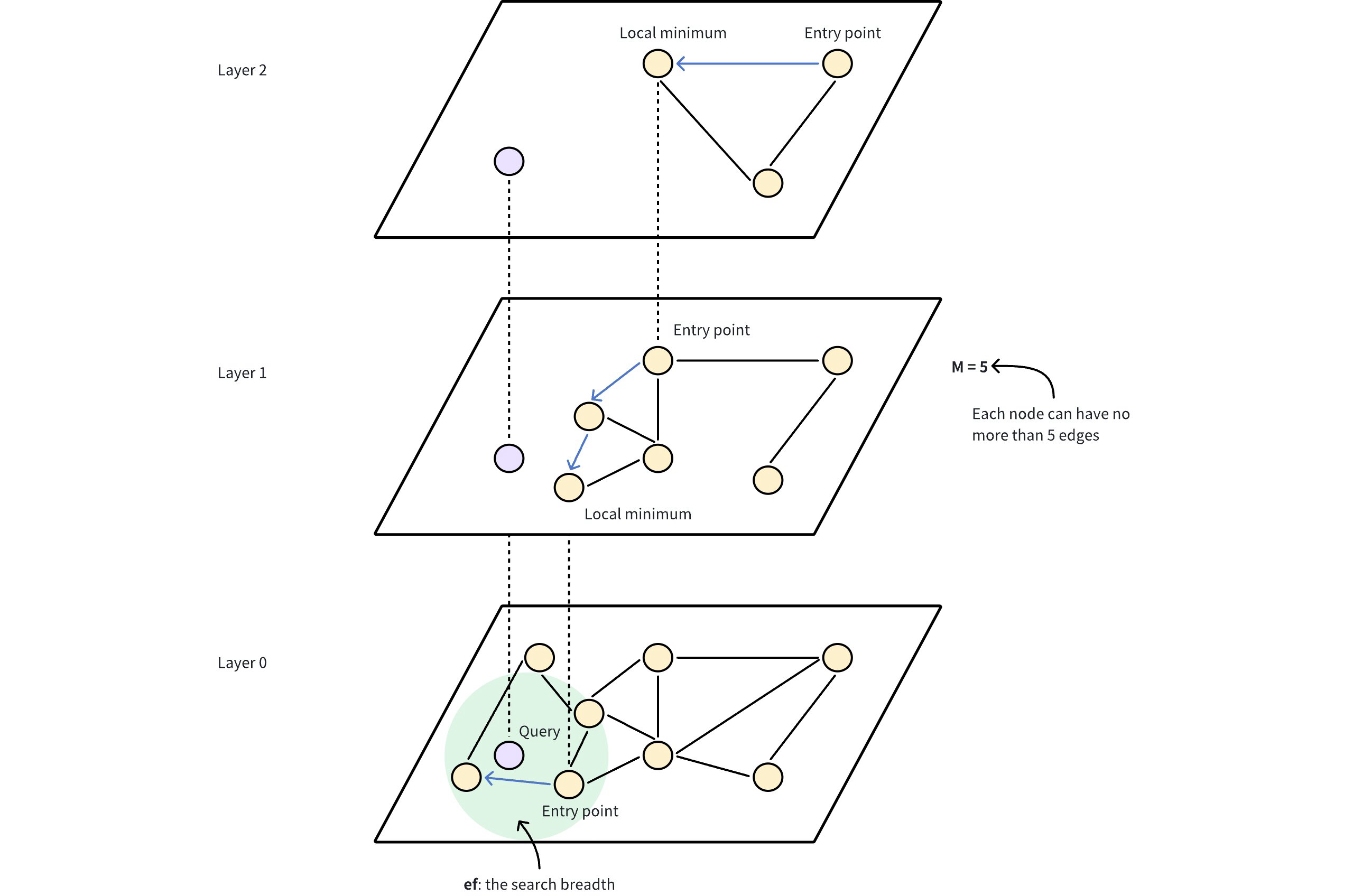
Der Algorithmus Hierarchical Navigable Small World (HNSW) baut einen mehrschichtigen Graphen auf, ähnlich wie eine Karte mit verschiedenen Zoomstufen. Die unterste Ebene enthält alle Datenpunkte, während die oberen Ebenen aus einer Teilmenge von Datenpunkten bestehen, die aus der unteren Ebene entnommen wurden.
In dieser Hierarchie enthält jede Ebene Knoten, die Datenpunkte darstellen und durch Kanten verbunden sind, die ihre Nähe anzeigen. Die höheren Schichten ermöglichen Sprünge über große Entfernungen, um schnell in die Nähe des Ziels zu gelangen, während die unteren Schichten eine feinkörnige Suche ermöglichen, um möglichst genaue Ergebnisse zu erzielen.
Und so funktioniert es:
Einstiegspunkt: Die Suche beginnt an einem festen Einstiegspunkt auf der obersten Ebene, der ein vorher festgelegter Knoten im Graphen ist.
Gierige Suche: Der Algorithmus bewegt sich gierig zum nächsten Nachbarn auf der aktuellen Ebene, bis er nicht mehr näher an den Abfragevektor herankommt. Die oberen Ebenen dienen der Navigation und fungieren als grober Filter, um potenzielle Einstiegspunkte für die feinere Suche auf den unteren Ebenen zu finden.
Ebene absteigen: Sobald in der aktuellen Ebene ein lokales Minimum erreicht ist, springt der Algorithmus über eine zuvor hergestellte Verbindung in die untere Ebene und wiederholt die gierige Suche.
Letzte Verfeinerung: Dieser Prozess wird fortgesetzt, bis die unterste Ebene erreicht ist, wo in einem letzten Verfeinerungsschritt die nächsten Nachbarn ermittelt werden.
 HNSW
HNSW
Die Leistung von HNSW hängt von mehreren Schlüsselparametern ab, die sowohl die Struktur des Graphen als auch das Suchverhalten steuern. Dazu gehören:
M: Die maximale Anzahl von Kanten oder Verbindungen, die jeder Knoten im Graphen auf jeder Ebene der Hierarchie haben kann. Eine höhereMführt zu einem dichteren Graphen und erhöht die Auffindbarkeit und die Genauigkeit, da die Suche mehr Pfade zu erkunden hat, was aber auch mehr Speicherplatz verbraucht und die Einfügezeit aufgrund zusätzlicher Verbindungen verlangsamt. Wie in der obigen Abbildung dargestellt, bedeutet M = 5, dass jeder Knoten im HNSW-Graphen direkt mit maximal 5 anderen Knoten verbunden ist. Dadurch entsteht eine mäßig dichte Graphenstruktur, bei der die Knoten über mehrere Pfade zu anderen Knoten gelangen können.efConstruction: Die Anzahl der Kandidaten, die bei der Indexerstellung berücksichtigt werden. Eine höhereefConstructionführt im Allgemeinen zu einer besseren Qualität des Graphen, erfordert aber mehr Zeit für die Erstellung.ef: Die Anzahl der Nachbarn, die während einer Suche ausgewertet werden. Eine Erhöhung vonefverbessert die Wahrscheinlichkeit, die nächsten Nachbarn zu finden, verlangsamt aber den Suchprozess.
Wie Sie diese Einstellungen an Ihre Bedürfnisse anpassen können, erfahren Sie unter Index-Parameter.
Index erstellen
Um einen HNSW -Index für ein Vektorfeld in Milvus zu erstellen, verwenden Sie die Methode add_index() und geben Sie die Parameter index_type, metric_type und zusätzliche Parameter für den Index an.
from pymilvus import MilvusClient
# Prepare index building params
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="HNSW", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"M": 64, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 100 # Number of candidate neighbors considered for connection during index construction
} # Index building params
)
In dieser Konfiguration:
index_type: Der Typ des zu erstellenden Index. In diesem Beispiel setzen Sie den Wert aufHNSW.metric_type: Die Methode zur Berechnung des Abstands zwischen Vektoren. Unterstützte Werte sindCOSINE,L2undIP. Einzelheiten finden Sie unter Metrische Typen.params: Zusätzliche Konfigurationsoptionen für den Aufbau des Index.M: Maximale Anzahl von Nachbarn, mit denen sich jeder Knoten verbinden kann.efConstruction: Anzahl der Nachbarschaftskandidaten, die während des Indexaufbaus für eine Verbindung in Frage kommen.
Weitere Informationen zu den für den Index
HNSWverfügbaren Parametern finden Sie unter Indexaufbau-Parameter.
Sobald die Indexparameter konfiguriert sind, können Sie den Index erstellen, indem Sie die Methode create_index() direkt verwenden oder die Indexparameter in der Methode create_collection übergeben. Weitere Informationen finden Sie unter Sammlung erstellen.
Suche im Index
Sobald der Index erstellt und die Entitäten eingefügt sind, können Sie Ähnlichkeitssuchen im Index durchführen.
search_params = {
"params": {
"ef": 10, # Number of neighbors to consider during the search
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # Collection name
anns_field="vector_field", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
limit=10, # TopK results to return
search_params=search_params
)
In dieser Konfiguration:
params: Zusätzliche Konfigurationsoptionen für die Suche im Index.ef: Anzahl der Nachbarn, die bei einer Suche berücksichtigt werden sollen.
Weitere Suchparameter, die für den Index
HNSWverfügbar sind, finden Sie unter Indexspezifische Suchparameter.
Index-Parameter
Dieser Abschnitt gibt einen Überblick über die Parameter, die für den Aufbau eines Index und die Durchführung von Suchen im Index verwendet werden.
Indexaufbau-Parameter
In der folgenden Tabelle sind die Parameter aufgeführt, die in params beim Aufbau eines Index konfiguriert werden können.
Parameter |
Beschreibung |
Wertebereich |
Tuning-Vorschlag |
|---|---|---|---|
|
Maximale Anzahl von Verbindungen (oder Kanten), die jeder Knoten im Graphen haben kann, einschließlich ausgehender und eingehender Kanten. Dieser Parameter wirkt sich direkt auf den Indexaufbau und die Suche aus. |
Typ: Integer Bereich: [2, 2048] Standardwert: |
Eine größere Ziehen Sie eine Verringerung von In den meisten Fällen wird empfohlen, einen Wert innerhalb dieses Bereichs zu wählen: [5, 100]. |
|
Anzahl der Nachbarschaftskandidaten, die bei der Indexerstellung für die Verbindung berücksichtigt werden. Für jedes neue Element wird ein größerer Pool von Kandidaten ausgewertet, aber die maximale Anzahl der tatsächlich hergestellten Verbindungen ist immer noch durch |
Typ: Integer Bereich: [1, int_max] Standardwert: |
Ein höherer Ziehen Sie eine Verringerung von In den meisten Fällen wird empfohlen, einen Wert innerhalb dieses Bereichs festzulegen: [50, 500]. |
Indexspezifische Suchparameter
In der folgenden Tabelle sind die Parameter aufgeführt, die in search_params.params für die Suche im Index konfiguriert werden können.
Parameter |
Beschreibung |
Wertebereich |
Tuning-Vorschlag |
|---|---|---|---|
|
Steuert die Breite der Suche während der Abfrage der nächsten Nachbarn. Er bestimmt, wie viele Knoten besucht und als potenzielle nächste Nachbarn bewertet werden. Dieser Parameter wirkt sich nur auf den Suchprozess aus und gilt ausschließlich für die unterste Schicht des Graphen. |
Typ: Integer Bereich: [1, int_max] Standardwert: limit (TopK nächste Nachbarn, die zurückgegeben werden) |
Eine größere Ziehen Sie in Erwägung, In den meisten Fällen wird empfohlen, einen Wert innerhalb dieses Bereichs zu wählen: [K, 10K]. |