Recommender System
This tutorial demonstrates how to use Milvus, the open-source vector database, to build a recommendation system.
The ML model and third-party software used include:
- PaddlePaddle
- Redis or MySQL
- Towhee
The recommender system is a subset of the information filtering system, which can be used in various scenarios including personalized movie, music, product, and feed stream recommendation. Unlike search engines, recommender systems do not require users to accurately describe their needs but discover users’ needs and interests by analyzing user behaviors.
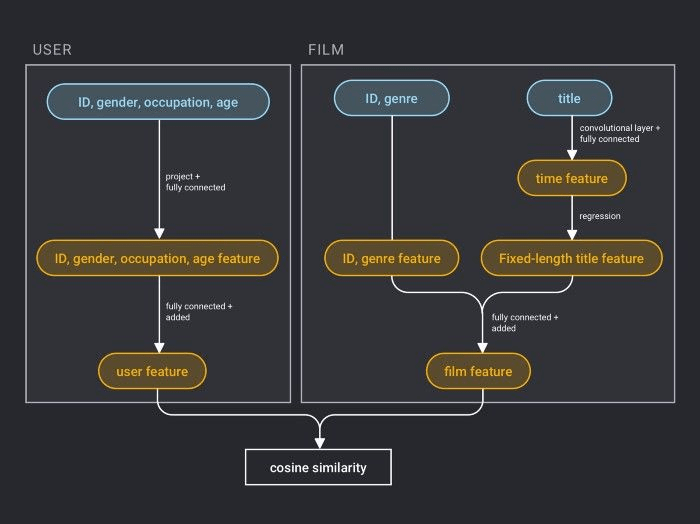
In this tutorial, you will learn how to build a movie recommender system that can suggest movies meeting user interests. To build such a recommender system, first download a movie-related dataset. This tutorial uses MovieLens 1M. Alternatively, you can prepare your own datasets, which should include such information as users’ ratings of movies, users’ demographic characteristics, and movie description. Use PaddlePaddle to combine user IDs and features and convert them into 256-dimensional vectors. Convert movie IDs and features into vectors in a similar way. Store the movie vectors in Milvus and use user vectors for similarity search. If the user vector is similar to a movie vector, Milvus will return the movie vector and its ID as the recommendation result. Then query movie information using the movie vector ID stored in Redis or MySQL.
 recommender_system
recommender_system