Mishards — Distributed Vector Search in Milvus
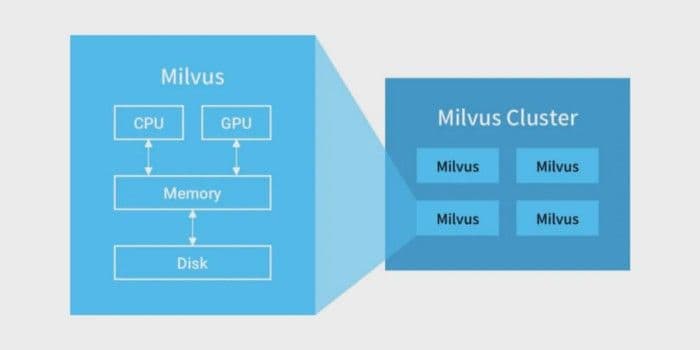
Milvus aims to achieve efficient similarity search and analytics for massive-scale vectors. A standalone Milvus instance can easily handle vector search for billion-scale vectors. However, for 10 billion, 100 billion or even larger datasets, a Milvus cluster is needed. The cluster can be used as a standalone instance for upper-level applications and can meet the business needs of low latency, high concurrency for massive-scale data. A Milvus cluster can resend requests, separate reading from writing, scale horizontally, and expand dynamically, thus providing a Milvus instance that can expand without limit. Mishards is a distributed solution for Milvus.
This article will briefly introduce components of the Mishards architecture. More detailed information will be introduced in the upcoming articles.
 1-milvus-cluster-mishards.png
1-milvus-cluster-mishards.png
Distributed architecture overview
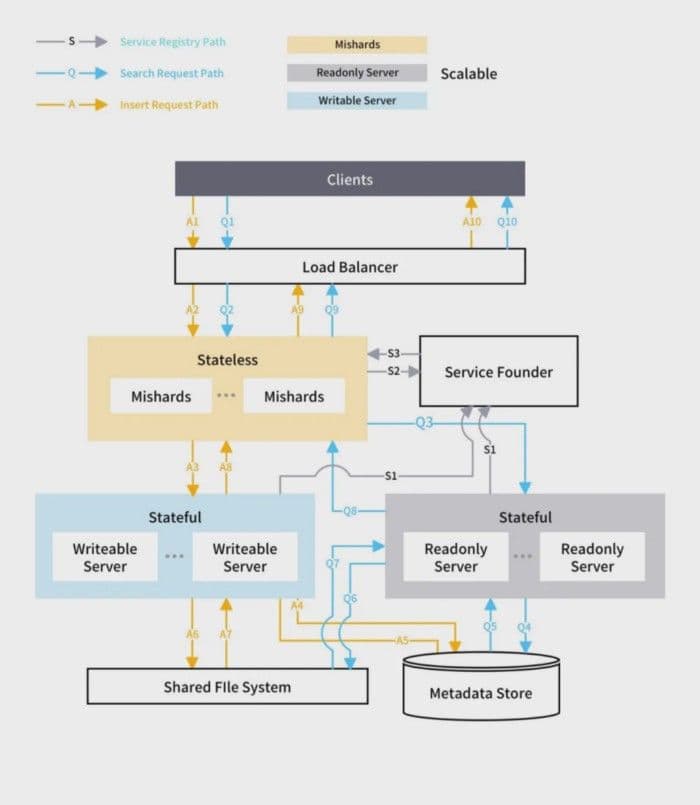 2-distributed-architecture-overview.png
2-distributed-architecture-overview.png
Service tracing
 3-service-tracing-milvus.png
3-service-tracing-milvus.png
Primary service components
- Service discovery framework, such as ZooKeeper, etcd, and Consul.
- Load balancer, such as Nginx, HAProxy, Ingress Controller.
- Mishards node: stateless, scalable.
- Write-only Milvus node: single node and not scalable. You need to use high availability solutions for this node to avoid single-point-of-failure.
- Read-only Milvus node: Stateful node and scalable.
- Shared storage service: All Milvus nodes use shared storage service to share data, such as NAS or NFS.
- Metadata service: All Milvus nodes use this service to share metadata. Currently, only MySQL is supported. This service requires MySQL high availability solution.
Scalable components
- Mishards
- Read-only Milvus nodes
Components introduction
Mishards nodes
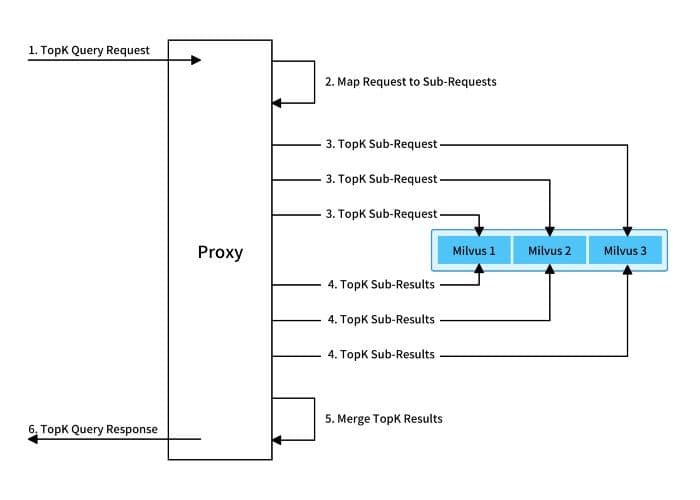
Mishards is responsible for breaking up upstream requests and routing sub-requests to sub-services. The results are summarized to return to upstream.
 4-mishards-nodes.jpg
4-mishards-nodes.jpg
As is indicated in the chart above, after accepting a TopK search request, Mishards first breaks up the request into sub-requests and send the sub-requests to the downstream service. When all sub-responses are collected, the sub-responses are merged and returned to upstream.
Because Mishards is a stateless service, it does not save data or participate in complex computation. Thus, nodes do not have high configuration requirements and the computing power is mainly used in merging sub-results. So, it is possible to increase the number of Mishards nodes for high concurrency.
Milvus nodes
Milvus nodes are responsible for CRUD related core operations, so they have relatively high configuration requirements. Firstly, the memory size should be large enough to avoid too many disk IO operations. Secondly, CPU configurations can also affect performance. As the cluster size increases, more Milvus nodes are required to increase system throughput.
Read-only nodes and writable nodes
- Core operations of Milvus are vector insertion and search. Search has extremely high requirements on CPU and GPU configurations, while insertion or other operations have relatively low requirements. Separating the node that runs search from the node that runs other operations leads to more economical deployment.
- In terms of service quality, when a node is performing search operations, the related hardware is running in full load and cannot ensure the service quality of other operations. Therefore, two node types are used. Search requests are processed by read-only nodes and other requests are processed by writable nodes.
Only one writable node is allowed
Currently, Milvus does not support sharing data for multiple writable instances.
During deployment, a single-point-of-failure of writable nodes needs to be considered. High availability solutions need to be prepared for writable nodes.
Read-only node scalability
When the data size is extremely large, or the latency requirement is extremely high, you can horizontally scale read-only nodes as stateful nodes. Assume there are 4 hosts and each has the following configuration: CPU Cores: 16, GPU: 1, Memory: 64 GB. The following chart shows the cluster when horizontally scaling stateful nodes. Both computing power and memory scale linearly. The data is split into 8 shards with each node processing requests from 2 shards.
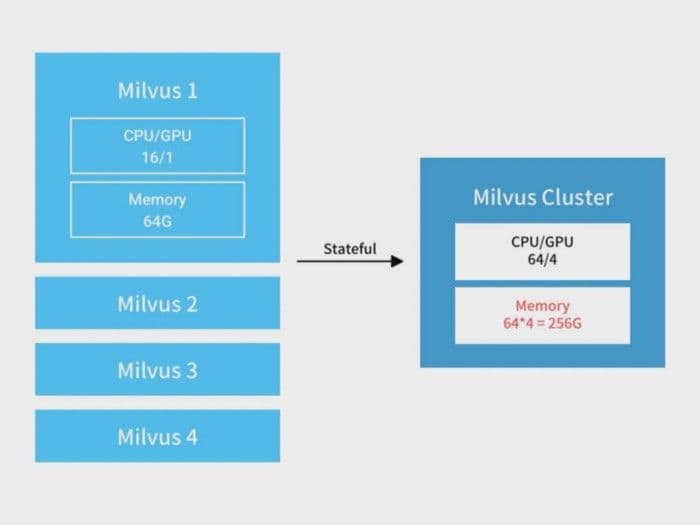 5-read-only-node-scalability-milvus.png
5-read-only-node-scalability-milvus.png
When the number of requests is large for some shards, stateless read-only nodes can be deployed for these shards to increase throughput. Take the hosts above as an example. when the hosts are combined into a serverless cluster, the computing power increases linearly. Because the data to process does not increase, the processing power for the same data shard also increases linearly.
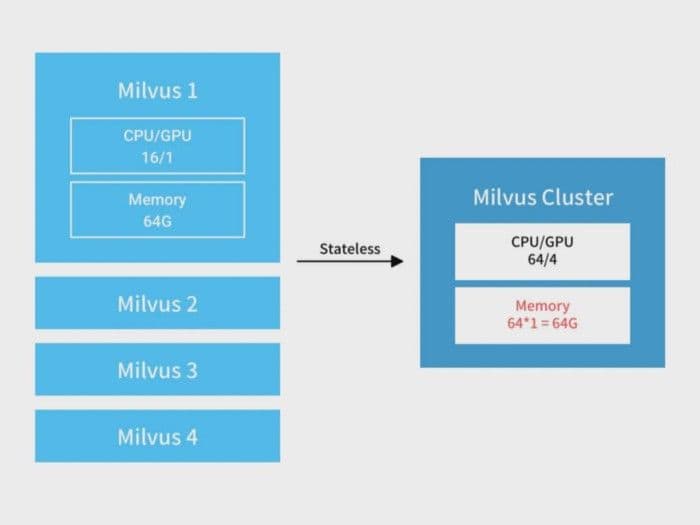 6-read-only-node-scalability-milvus-2.png
6-read-only-node-scalability-milvus-2.png
Metadata service
Keywords: MySQL
For more information about Milvus metadata, refer to How to view metadata. In a distributed system, Milvus writable nodes are the only producer of metadata. Mishards nodes, Milvus writable nodes, and Milvus read-only nodes are all consumers of metadata. Currently, Milvus only supports MySQL and SQLite as the storage backend of metadata. In a distributed system, the service can only be deployed as highly-available MySQL.
Service discovery
Keywords: Apache Zookeeper, etcd, Consul, Kubernetes
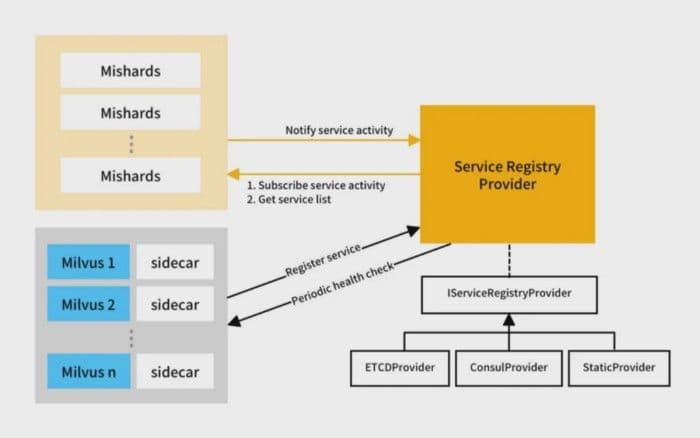 7-service-discovery.png
7-service-discovery.png
Service discovery provides information about all Milvus nodes. Milvus nodes register their information when going online and log out when going offline. Milvus nodes can also detect abnormal nodes by periodically checking the health status of services.
Service discovery contains a lot of frameworks, including etcd, Consul, ZooKeeper, etc. Mishards defines the service discovery interfaces and provides possibilities for scaling by plugins. Currently, Mishards provides two kinds of plugins, which correspond to Kubernetes cluster and static configurations. You can customize your own service discovery by following the implementation of these plugins. The interfaces are temporary and need a redesign. More information about writing your own plugin will be elaborated in the upcoming articles.
Load balancing and service sharding
Keywords: Nginx, HAProxy, Kubernetes
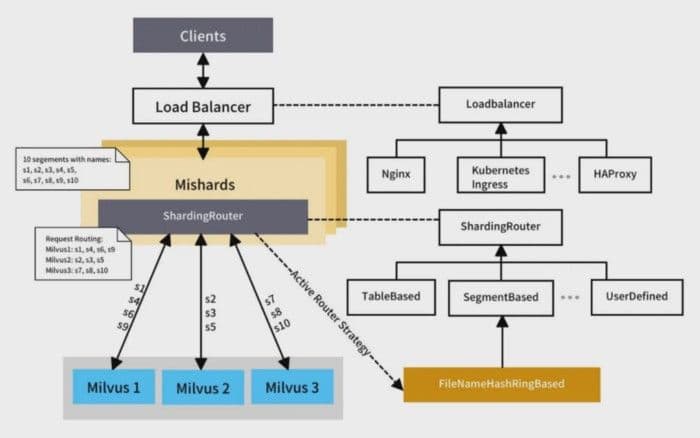 7-load-balancing-and-service-sharding.png
7-load-balancing-and-service-sharding.png
Service discovery and load balancing are used together. Load balancing can be configured as polling, hashing, or consistent hashing.
The load balancer is responsible for resending user requests to the Mishards node.
Each Mishards node acquires the information of all downstream Milvus nodes via the service discovery center. All related metadata can be acquired by metadata service. Mishards implements sharding by consuming these resources. Mishards defines the interfaces related to routing strategies and provides extensions via plugins. Currently, Mishards provides a consistent hashing strategy based on the lowest segment level. As is shown in the chart, there are 10 segments, s1 to s10. Per the segment-based consistent hashing strategy, Mishards routes requests concerning s1, 24, s6, and s9 to the Milvus 1 node, s2, s3, s5 to the Milvus 2 node, and s7, s8, s10 to the Milvus 3 node.
Based on your business needs, you can customize routing by following the default consistent hashing routing plugin.
Tracing
Keywords: OpenTracing, Jaeger, Zipkin
Given the complexity of a distributed system, requests are sent to multiple internal service invocations. To help pinpoint problems, we need to trace the internal service invocation chain. As the complexity increases, the benefits of an available tracing system are self-explanatory. We choose the CNCF OpenTracing standard. OpenTracing provides platform-independent, vendor-independent APIs for developers to conveniently implement a tracing system.
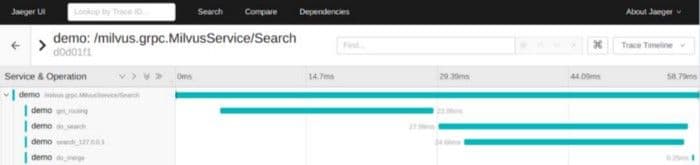 8-tracing-demo-milvus.png
8-tracing-demo-milvus.png
The previous chart is an example of tracing during search invocation. Search invokes get_routing, do_search, and do_merge consecutively. do_search also invokes search_127.0.0.1.
The whole tracing record forms the following tree:
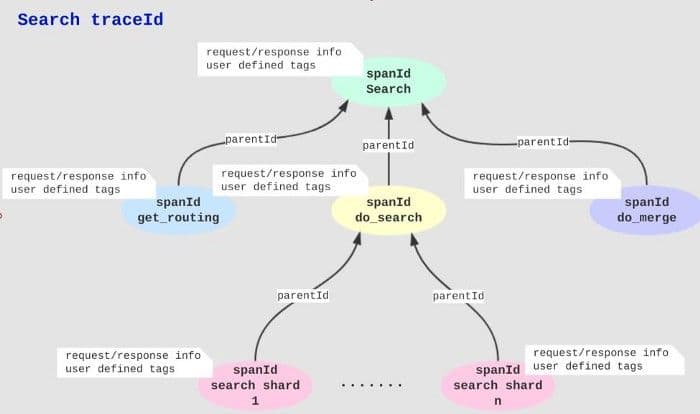 8-search-traceid-milvus.png
8-search-traceid-milvus.png
The following chart shows examples of request/response info and tags of each node:
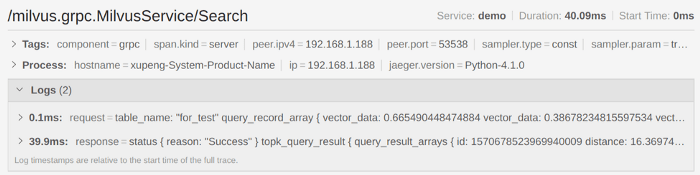 request-response-info-tags-node-milvus.png
request-response-info-tags-node-milvus.png
OpenTracing has been integrated to Milvus. More information will be covered in the upcoming articles.
Monitoring and alerting
Keywords: Prometheus, Grafana
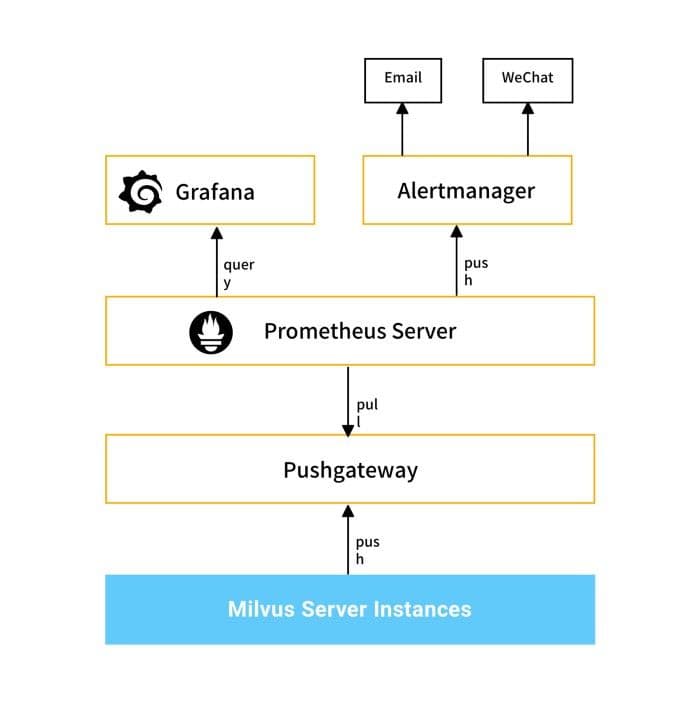 10-monitor-alert-milvus.jpg
10-monitor-alert-milvus.jpg
Summary
As the service middleware, Mishards integrates service discovery, routing request, result merging, and tracing. Plugin-based expansion is also provided. Currently, distributed solutions based on Mishards still have the following setbacks:
- Mishards uses proxy as the middle layer and has latency costs.
- Milvus writable nodes are single-point services.
- Dependent on highly-available MySQL service. -Deployment is complicated when there are multiple shards and a single shard has multiple copies.
- Lacks a cache layer, such as access to metadata.
We will fix these know issues in the upcoming versions so that Mishards can be applied to the production environment more conveniently.
- Distributed architecture overview
- Service tracing
- Primary service components
- Scalable components
- Components introduction
- Milvus nodes
- Summary
Content
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word


