Milvus performance on AVX-512 vs. AVX2
Conscious intelligent machines that want to take over the world are a steady fixture in science fiction, but in reality modern computers are very obedient. Without being told, they seldom know what to do with themselves. Computers perform tasks based on instructions, or orders, sent from a program to a processor. At their lowest level, each instruction is a sequence of ones and zeroes that describes an operation for a computer to execute. Typically, in computer assembly languages each machine language statement corresponds to a processor instruction. The central processing unit (CPU) relies on instructions to perform calculations and control systems. Additionally, CPU performance is often measured in terms of instruction execution capability (e.g., execution time).
What are Advanced Vector Extensions?
Advanced Vector Extensions (AVX) are an instruction set for microprocessors that rely on the x86 family of instruction set architectures. First proposed by Intel in March 2008, AVX saw broad support three years later with the launch of Sandy Bridge—a microarchitecture used in the second generation of Intel Core processors (e.g, Core i7, i5, i3)— and AMD’s competing microarchitecture also released in 2011, Bulldozer.
AVX introduced a new coding scheme, new features, and new instructions. AVX2 expands most integer operations to 256 bits and introduces fused multiply-accumulate (FMA) operations. AVX-512 expands AVX to 512-bit operations using a new enhanced vector extension (EVEX) prefix encoding.
Milvus is an open-source vector database designed for similarity search and artificial intelligence (AI) applications. The platform supports the AVX-512 instruction set, meaning it can be used with all CPUs that include the AVX-512 instructions. Milvus has broad applications spanning recommender systems, computer vision, natural language processing (NLP) and more. This article presents performance results and analysis of a Milvus vector database on AVX-512 and AVX2.
Milvus performance on AVX-512 vs. AVX2
System configuration
- CPU: Intel® Platinum 8163 CPU @ 2.50GHz24 cores 48 threads
- Number of CPU: 2
- Graphics card, GeForce RTX 2080Ti 11GB 4 cards
- Mem: 768GB
- Disk: 2TB SSD
Milvus parameters
- cahce.cahe_size: 25, The size of CPU memory used for caching data for faster query.
- nlist: 4096
- nprobe: 128
Note: nlist is the indexing parameter to create from the client; nprobe the searching parameter. Both IVF_FLAT and IVF_SQ8 use a clustering algorithm to partition a large number of vectors into buckets, nlist being the total number of buckets to partition during clustering. The first step in a query is to find the number of buckets that are closest to the target vector, and the second step is to find the top-k vectors in these buckets by comparing the distance of the vectors. nprobe refers to the number of buckets in the first step.
Dataset: SIFT10M dataset
These tests use the SIFT10M dataset, which contains one million 128-dimensional vectors and is often used for analyzing the performance of corresponding nearest-neighbor search methods. The top-1 search time for nq = [1, 10, 100, 500, 1000] will be compared between the two instruction sets.
Results by vector index type
Vector indexes are time- and space-efficient data structures built on the vector field of a collection using various mathematical models. Vector indexing allows large datasets to be searched efficiently when trying to identify similar vectors to an input vector. Due to the time consuming nature of accurate retrieval, most of the index types supported by Milvus use approximate nearest neighbor (ANN) search.
For these tests, three indexes were used with AVX-512 and AVX2: IVF_FLAT, IVF_SQ8, and HNSW.
IVF_FLAT
Inverted file (IVF_FLAT) is an index type based on quantization. It is the most basic IVF index, and the encoded data stored in each unit is consistent with the original data. The index divides vector data into a number of cluster units (nlist), and then compares distances between the target input vector and the center of each cluster. Depending on the number of clusters the system is set to query (nprobe), similarity search results are returned based on comparisons between the target input and the vectors in the most similar cluster(s) only — drastically reducing query time. By adjusting nprobe, an ideal balance between accuracy and speed can be found for a given scenario.
Performance results
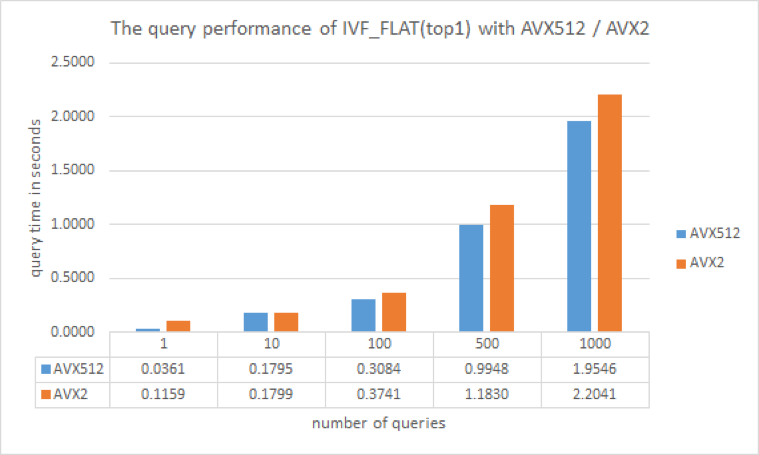 IVF_FLAT.png
IVF_FLAT.png
IVF_SQ8
IVF_FLAT does not perform any compression, so the index files it produces are roughly the same size as the original, raw non-indexed vector data. When disk, CPU, or GPU memory resources are limited, IVF_SQ8 is a better option than IVF_FLAT. This index type can convert each dimension of the original vector from a four-byte floating-point number to a one-byte unsigned integer by performing scalar quantization. This reduces disk, CPU, and GPU memory consumption by 70–75%.
Performance results
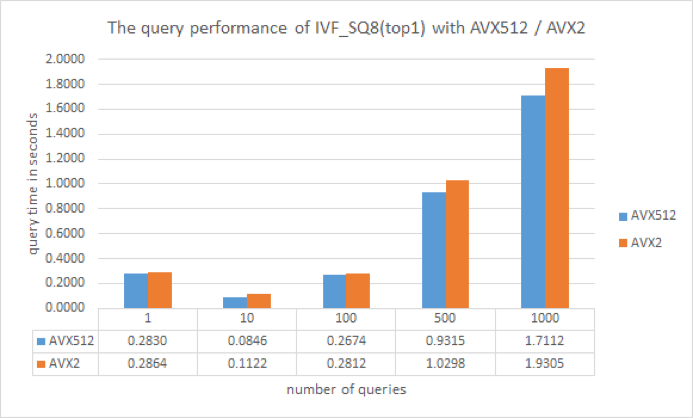 IVF_SQ8.png
IVF_SQ8.png
HNSW
Hierarchical Small World Graph (HNSW) is a graph-based indexing algorithm. Queries begin in the uppermost layer by finding the node closest to the target, it then goes down to the next layer for another round of search. After multiple iterations, it can quickly approach the target position.
Performance results
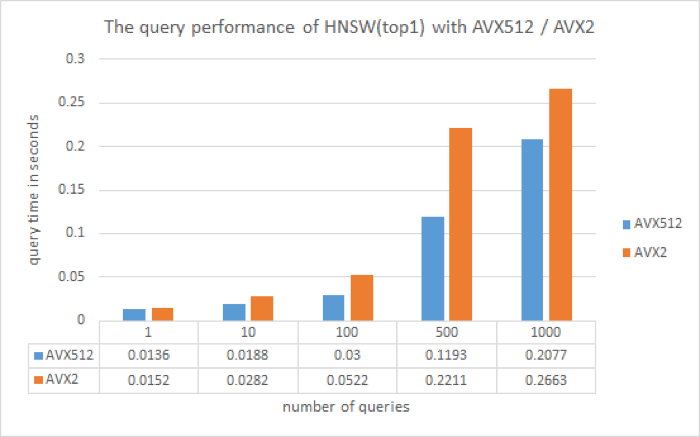 HNSW.png
HNSW.png
Comparing vector indexes
Vector retrieval is consistently faster on the AVX-512 instruction set than on AVX2. This is because AVX-512 supports 512-bit computation, compared to just 256-bit computation on AVX2. Theoretically, AVX-512 should be twice as fast as the AVX2 however, Milvus conducts other time-consuming tasks in addition to vector similarity calculations. The overall retrieval time of AVX-512 is unlikely to be twice as short as AVX2 in real-world scenarios.
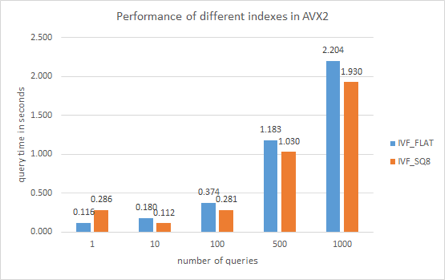 comparison.png
comparison.png
Retrieval is significantly faster on the HNSW index than the other two indexes, while IVF_SQ8 retrieval is slightly faster than IVF_FLAT on both instruction sets. This is likely because IVF_SQ8 requires just 25% of the memory need by IVF_FLAT. IVF_SQ8 loads 1 byte for each vector dimension, while IVF_FLAT loads 4 bytes per vector dimension. The time required for the calculation is most likely constrained by memory bandwidth. As a result, IVF_SQ8 not only takes up less space, but also requires less time to retrieve vectors.
Milvus is a versatile, high-performance vector database
The tests presented in this article demonstrate that Milvus offers excellent performance on both the AVX-512 and AVX2 instruction sets using different indexes. Regardless of the index type, Milvus performs better on AVX-512.
Milvus is compatible with a variety of deep learning platforms and is used in miscellaneous AI applications. Milvus 2.0, a reimagined version of the world’s most popular vector database, was released under an open-source license in July 2021. For more information about the project, check out the following resources:
Like the article? Spread the word


