I Built a Deep Research with Open Source—and So Can You!
Well actually, a minimally scoped agent that can reason, plan, use tools, etc. to perform research using Wikipedia. Still, not bad for a few hours of work…
Unless you reside under a rock, in a cave, or in a remote mountain monastery, you will have heard about OpenAI’s release of Deep Research on Feb 2, 2025. This new product promises to revolutionize how we answer questions requiring the synthesis of large amounts of diverse information.
You type in your query, select the Deep Research option, and the platform autonomously searches the web, performs reasoning on what it discovers, and synthesizes multiple sources into a coherent, fully-cited report. It takes several orders of magnitude longer to produce its output relative to a standard chatbot, but the result is more detailed, more informed, and more nuanced.
How does it work?
But how does this technology work, and why is Deep Research a noticeable improvement over previous attempts (like Google’s Deep Research - incoming trademark dispute alert)? We’ll leave the latter for a future post. As for the former, there is no doubt much “secret sauce” underlying Deep Research. We can glean a few details from OpenAI’s release post, which I summarize.
Deep Research exploits recent advances in foundation models specialized for reasoning tasks:
“…fine-tuned on the upcoming OpenAI o3 reasoning model…”
“…leverages reasoning to search, interpret, and analyze massive amounts of text…”
Deep Research makes use of a sophisticated agentic workflow with planning, reflection, and memory:
“…learned to plan and execute a multi-step trajectory…”
“…backtracking and reacting to real-time information…”
“…pivoting as needed in reaction to information it encounters…”
Deep Research is trained on proprietary data, using several types of fine-tuning, which is likely a key component in its performance:
“…trained using end-to-end reinforcement learning on hard browsing and reasoning tasks across a range of domains…”
“…optimized for web browsing and data analysis…”
The exact design of the agentic workflow is a secret, however, we can build something ourselves based on well-established ideas about how to structure agents.
One note before we begin: It is easy to be swept away by Generative AI fever, especially when a new product that seems a step-improvement is released. However, Deep Research, as OpenAI acknowledges, has limitations common to Generative AI technology. We should remember to think critically about the output in that it may contain false facts (“hallucinations”), incorrect formatting and citations, and vary significantly in quality based on the random seed.
Can I build my own?
Why certainly! Let’s build our own “Deep Research”, running locally and with open-source tools. We’ll be armed with just a basic knowledge of Generative AI, common sense, a couple of spare hours, a GPU, and the open-source Milvus, DeepSeek R1, and LangChain.
We cannot hope to replicate OpenAI’s performance of course, but our prototype will minimally demonstrate some of the key ideas likely underlying their technology, combining advances in reasoning models with advances in agentic workflows. Importantly, and unlike OpenAI, we will be using only open-source tools, and be able to deploy our system locally - open-source certainly provides us great flexibility!
We will make a few simplifying assumptions to reduce the scope of our project:
We will use an open-source reasoning mode distilled then quantized for 4-bits that can be run locally.
We will not perform additional fine-tuning on our reasoning model ourselves.
The only tool our agent has is the ability to download and read a Wikipedia page and perform separate RAG queries (we will not have access to the entire web).
Our agent will only process text data, not images, PDFs, etc.
Our agent will not backtrack or consider pivots.
Our agent will (not yet) control its execution flow based on its output.
Wikipedia contains the truth, the whole truth and nothing but the truth.
We will use Milvus for our vector database, DeepSeek R1 as our reasoning model, and LangChain to implement RAG. Let’s get started!
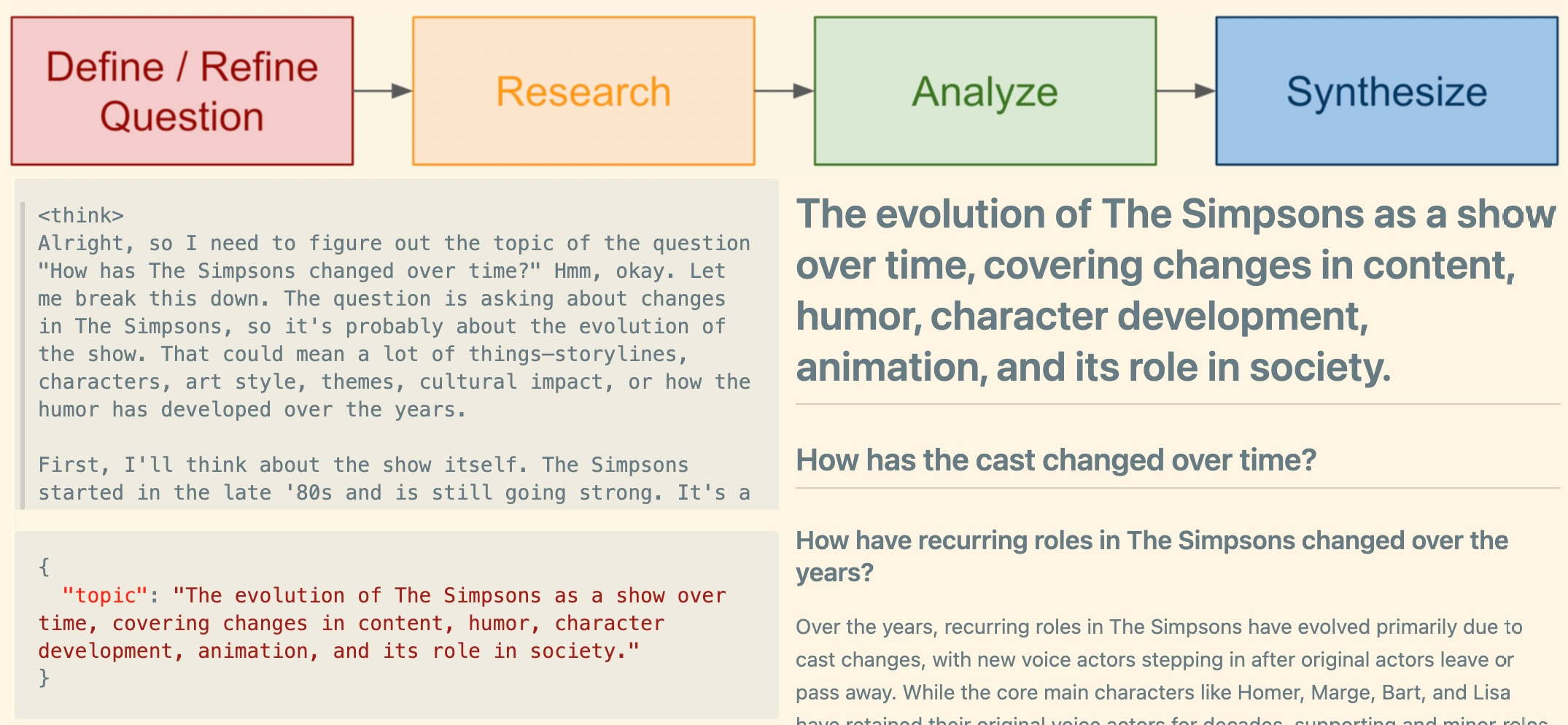
We will use our mental model of how humans conduct research to design the agentic workflow:
Define/Refine Question
Research starts by defining a question. We take the question to be the user’s query, however, we use our reasoning model to ensure the question is expressed in a way that is specific, clear, and focused. That is, our first step is to rewrite the prompt and extract any subqueries or subquestions. We make effective use of our foundation models specialization for reasoning, and a simple method for JSON structured output.
Here is an example reasoning trace as DeepSeek refines the question “How has the cast changed over time?”:
<think>
Alright, so I need to break down the question "How has the cast changed over time?" related to the evolution of The Simpsons. Let me think about what aspects are involved here.
First, I know that the cast has changed a lot, but I need to figure out the intermediate questions to approach this. The main question is about changes in the cast over time, so I should consider different areas that contribute to this change.
I guess the first sub-question would be about the original cast members. Who were the main voices and how did they evolve? Then, there might be new cast additions over the years, so another sub-question about that.
Also, some original voice actors have left, so I should include a sub-question about departures. Then, new voice actors joining would be another point.
The show has been popular for a long time, so recurring roles changing might be another aspect. Additionally, the role of the show in society might have influenced casting choices, so a sub-question about that.
Lastly, the overall impact on the cast's careers could be another angle. So, I should list these as sub-questions to cover all aspects.
</think>
Search
Next, we conduct a “literature review” of Wikipedia articles. For now, we read a single article and leave navigating links to a future iteration. We discovered during prototyping that link exploration can become very expensive if each link requires a call to the reasoning model. We parse the article, and store its data in our vector database, Milvus, akin to taking notes.
Here is a code snippet showing how we store our Wikipedia page in Milvus using its LangChain integration:
wiki_wiki = wikipediaapi.Wikipedia(user_agent='MilvusDeepResearchBot (<insert your email>)', language='en')
page_py = wiki_wiki.page(page_title)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.create_documents([page_py.text])
vectorstore = Milvus.from_documents( # or Zilliz.from_documents
documents=docs,
embedding=embeddings,
connection_args={
"uri": "./milvus_demo.db",
},
drop_old=True,
index_params={
"metric_type": "COSINE",
"index_type": "FLAT",
"params": {},
},
)
Analyze
The agent returns to its questions and answers them based on the relevant information in the document. We will leave a multi-step analysis/reflection workflow for future work, as well as any critical thinking on the credibility and bias of our sources.
Here is a code snippet illustrating constructing a RAG with LangChain and answering our subquestions separately.
# Define the RAG chain for response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Prompt the RAG for each question
answers = {}
total = len(leaves(breakdown))
pbar = tqdm(total=total)
for k, v in breakdown.items():
if v == []:
print(k)
answers[k] = rag_chain.invoke(k).split('</think>')[-1].strip()
pbar.update(1)
else:
for q in v:
print(q)
answers[q] = rag_chain.invoke(q).split('</think>')[-1].strip()
pbar.update(1)
Synthesize
After the agent has performed its research, it creates a structured outline, or rather, a skeleton, of its findings to summarize in a report. It then completes each section, filling it in with a section title and the corresponding content. We leave a more sophisticated workflow with reflection, reordering, and rewriting for a future iteration. This part of the agent involves planning, tool usage, and memory.
See accompanying notebook for the full code and the saved report file for example output.
Results
Our query for testing is “How has The Simpsons changed over time?” and the data source is the Wikipedia article for “The Simpsons”. Here is one section of the generated report:

Summary: What we built and what’s next
In just a few hours, we have designed a basic agentic workflow that can reason, plan, and retrieve information from Wikipedia to generate a structured research report. While this prototype is far from OpenAI’s Deep Research, it demonstrates the power of open-source tools like Milvus, DeepSeek, and LangChain in building autonomous research agents.
Of course, there’s plenty of room for improvement. Future iterations could:
Expand beyond Wikipedia to search multiple sources dynamically
Introduce backtracking and reflection to refine responses
Optimize execution flow based on the agent’s own reasoning
Open-source gives us flexibility and control that closed source doesn’t. Whether for academic research, content synthesis, or AI-powered assistance, building our own research agents open up exciting possibilities. Stay tuned for the next post where we explore adding real-time web retrieval, multi-step reasoning, and conditional execution flow!
Resources
Notebook: “Baseline for An Open-Source Deep Research”
- How does it work?
- Can I build my own?
- Results
- Summary: What we built and what’s next
- Resources
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



