Hands-on RAG with Qwen3 Embedding and Reranking Models using Milvus
If you’ve been keeping an eye on the embedding model space, you’ve probably noticed Alibaba just dropped their Qwen3 Embedding series. They released both embedding and reranking models in three sizes each (0.6B, 4B, 8B), all built on the Qwen3 foundation models and designed specifically for retrieval tasks.
The Qwen3 series has a few features I found interesting:
Multilingual embeddings - they claim a unified semantic space across 100+ languages
Instruction prompting - you can pass custom instructions to modify embedding behavior
Variable dimensions - supports different embedding sizes via Matryoshka Representation Learning
32K context length - can process longer input sequences
Standard dual/cross-encoder setup - embedding model uses dual-encoder, reranker uses cross-encoder
Looking at the benchmarks, Qwen3-Embedding-8B achieved a score of 70.58 on the MTEB multilingual leaderboard, surpassing BGE, E5, and even Google Gemini. The Qwen3-Reranker-8B hit 69.02 on multilingual ranking tasks. These aren’t just “pretty good among open-source models” - they’re comprehensively matching or even surpassing mainstream commercial APIs. In RAG retrieval, cross-language search, and code search systems, especially in Chinese contexts, these models already have production-ready capabilities.
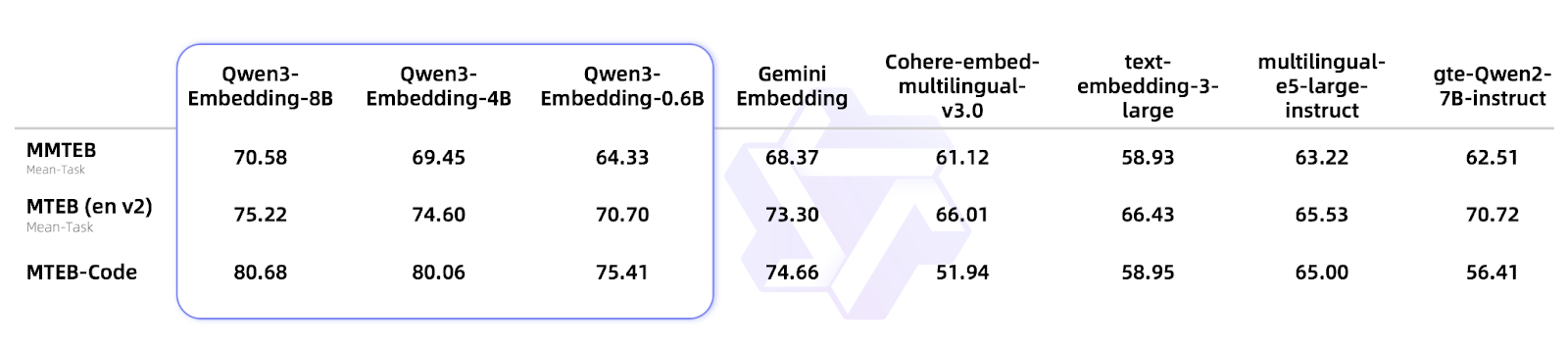
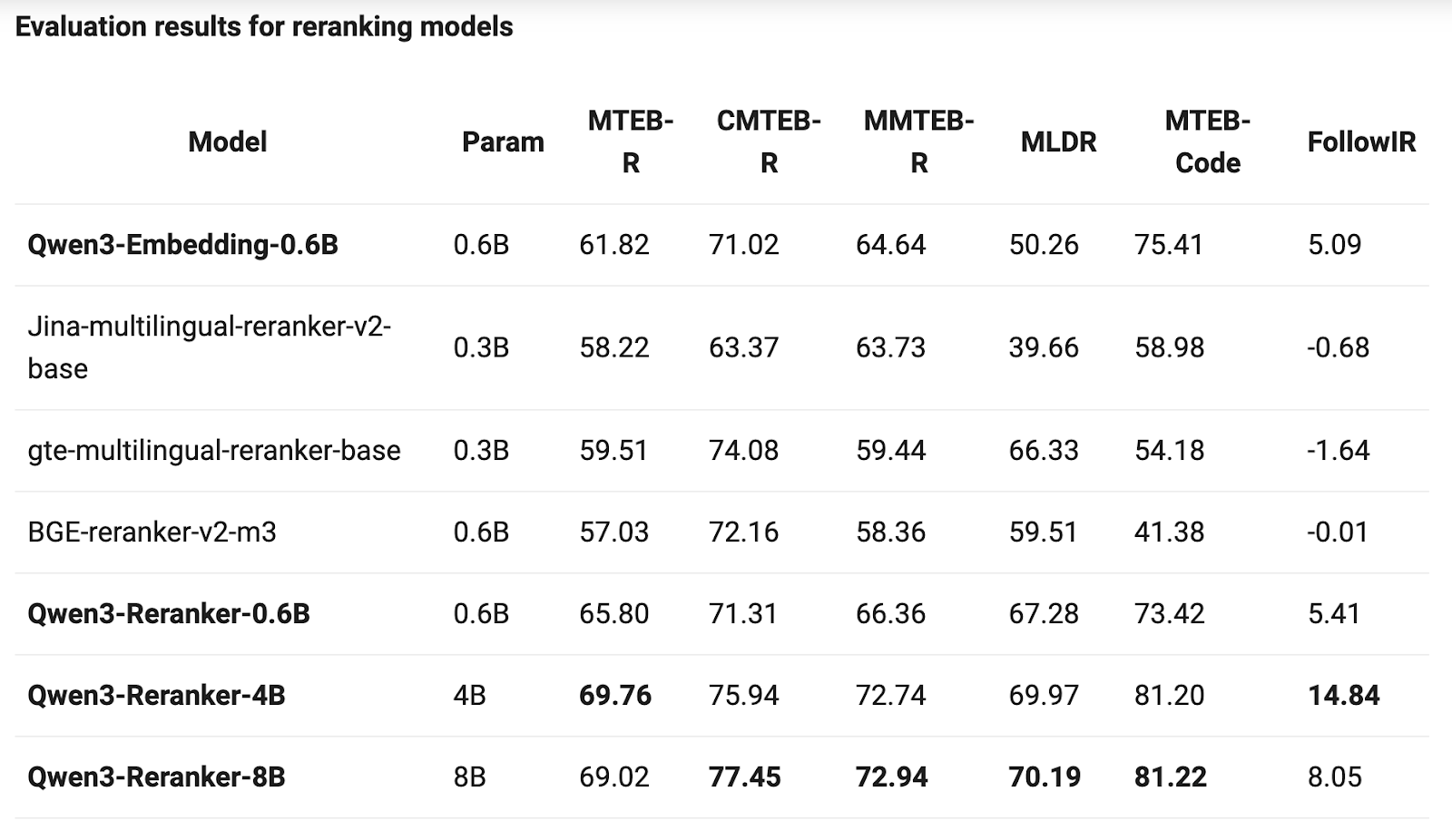
As someone who’s likely dealt with the usual suspects (OpenAI’s embeddings, BGE, E5), you might be wondering if these are worth your time. Spoiler: they are.
What We’re Building
This tutorial walks through building a complete RAG system using Qwen3-Embedding-0.6B and Qwen3-Reranker-0.6B with Milvus. We’ll implement a two-stage retrieval pipeline:
Dense retrieval with Qwen3 embeddings for fast candidate selection
Reranking with Qwen3 cross-encoder for precision refinement
Generation with OpenAI’s GPT-4 for final responses
By the end, you’ll have a working system that handles multilingual queries, uses instruction prompting for domain tuning, and balances speed with accuracy through intelligent reranking.
Environment Setup
Let’s start with the dependencies. Note the minimum version requirements - they’re important for compatibility:
pip install --upgrade pymilvus openai requests tqdm sentence-transformers transformers
Requires transformers>=4.51.0 and sentence-transformers>=2.7.0
For this tutorial, we’ll use OpenAI as our generation model. Set up your API key:
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
Data Preparation
We’ll use Milvus documentation as our knowledge base - it’s a good mix of technical content that tests both retrieval and generation quality.
Download and extract the documentation:
! wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
! unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
Load and chunk the markdown files. We’re using a simple header-based splitting strategy here - for production systems, consider more sophisticated chunking approaches:
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
Model Setup
Now let’s initialize our models. We’re using the lightweight 0.6B versions, which offer a good balance of performance and resource requirements:
from openai import OpenAI
from sentence_transformers import SentenceTransformer
import torch
from transformers import AutoModel, AutoTokenizer, AutoModelForCausalLM
# Initialize OpenAI client for LLM generation
openai_client = OpenAI()
# Load Qwen3-Embedding-0.6B model for text embeddings
embedding_model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# Load Qwen3-Reranker-0.6B model for reranking
reranker_tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Reranker-0.6B", padding_side='left')
reranker_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-Reranker-0.6B").eval()
# Reranker configuration
token_false_id = reranker_tokenizer.convert_tokens_to_ids("no")
token_true_id = reranker_tokenizer.convert_tokens_to_ids("yes")
max_reranker_length = 8192
prefix = "<|im_start|>system\nJudge whether the Document meets the requirements based on the Query and the Instruct provided. Note that the answer can only be \"yes\" or \"no\".<|im_end|>\n<|im_start|>user\n"
suffix = "<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n"
prefix_tokens = reranker_tokenizer.encode(prefix, add_special_tokens=False)
suffix_tokens = reranker_tokenizer.encode(suffix, add_special_tokens=False)
The expected output:
Embedding Function
The key insight with Qwen3 embeddings is the ability to use different prompts for queries versus documents. This seemingly small detail can significantly improve retrieval performance:
def emb_text(text, is_query=False):
"""
Generate text embeddings using Qwen3-Embedding-0.6B model.
Args:
text: Input text to embed
is_query: Whether this is a query (True) or document (False)
Returns:
List of embedding values
"""
if is_query:
# For queries, use the "query" prompt for better retrieval performance
embeddings = embedding_model.encode([text], prompt_name="query")
else:
# For documents, use default encoding
embeddings = embedding_model.encode([text])
return embeddings[0].tolist()
Let’s test the embedding function and check the output dimensions:
test_embedding = emb_text("This is a test")
embedding_dim = len(test_embedding)
print(f"Embedding dimension: {embedding_dim}")
print(f"First 10 values: {test_embedding[:10]}")
Expected output:
Embedding dimension: 1024
First 10 values: [-0.009923271834850311, -0.030248118564486504, -0.011494234204292297, ...]
Reranking Implementation
The reranker uses a cross-encoder architecture to evaluate query-document pairs. This is more computationally expensive than the dual-encoder embedding model, but provides much more nuanced relevance scoring.
Here’s the complete reranking pipeline:
def format_instruction(instruction, query, doc):
"""Format instruction for reranker input"""
if instruction is None:
instruction = 'Given a web search query, retrieve relevant passages that answer the query'
output = "<Instruct>: {instruction}\n<Query>: {query}\n<Document>: {doc}".format(
instruction=instruction, query=query, doc=doc
)
return output
def process_inputs(pairs):
"""Process inputs for reranker"""
inputs = reranker_tokenizer(
pairs, padding=False, truncation='longest_first',
return_attention_mask=False, max_length=max_reranker_length - len(prefix_tokens) - len(suffix_tokens)
)
for i, ele in enumerate(inputs['input_ids']):
inputs['input_ids'][i] = prefix_tokens + ele + suffix_tokens
inputs = reranker_tokenizer.pad(inputs, padding=True, return_tensors="pt", max_length=max_reranker_length)
for key in inputs:
inputs[key] = inputs[key].to(reranker_model.device)
return inputs
@torch.no_grad()
def compute_logits(inputs, **kwargs):
"""Compute relevance scores using reranker"""
batch_scores = reranker_model(**inputs).logits[:, -1, :]
true_vector = batch_scores[:, token_true_id]
false_vector = batch_scores[:, token_false_id]
batch_scores = torch.stack([false_vector, true_vector], dim=1)
batch_scores = torch.nn.functional.log_softmax(batch_scores, dim=1)
scores = batch_scores[:, 1].exp().tolist()
return scores
def rerank_documents(query, documents, task_instruction=None):
"""
Rerank documents based on query relevance using Qwen3-Reranker
Args:
query: Search query
documents: List of documents to rerank
task_instruction: Task instruction for reranking
Returns:
List of (document, score) tuples sorted by relevance score
"""
if task_instruction is None:
task_instruction = 'Given a web search query, retrieve relevant passages that answer the query'
# Format inputs for reranker
pairs = [format_instruction(task_instruction, query, doc) for doc in documents]
# Process inputs and compute scores
inputs = process_inputs(pairs)
scores = compute_logits(inputs)
# Combine documents with scores and sort by score (descending)
doc_scores = list(zip(documents, scores))
doc_scores.sort(key=lambda x: x[1], reverse=True)
return doc_scores
Setting Up Milvus Vector Database
Now let’s set up our vector database. We’re using Milvus Lite for simplicity, but the same code works with full Milvus deployments:
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
Deployment Options:
Local file (like
./milvus.db): Uses Milvus Lite, perfect for developmentDocker/Kubernetes: Use server URI like
http://localhost:19530for productionZilliz Cloud: Use cloud endpoint and API key for managed service
Clean up any existing collection and create a new one:
# Remove existing collection if it exists
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
# Create new collection with our embedding dimensions
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim, # 1024 for Qwen3-Embedding-0.6B
metric_type="IP", # Inner product for similarity
consistency_level="Strong", # Ensure data consistency
)
Loading Data into Milvus
Now let’s process our documents and insert them into the vector database:
from tqdm import tqdm
data = []
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": emb_text(line), "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Expected output:
Creating embeddings: 100%|████████████| 72/72 [00:08<00:00, 8.68it/s]
Inserted 72 documents
Enhancing RAG with Reranking Technology
Now comes the exciting part - putting it all together into a complete retrieval-augmented generation system.
Step 1: Query and Initial Retrieval
Let’s test with a common question about Milvus:
question = "How is data stored in milvus?"
# Perform initial dense retrieval to get top candidates
search_res = milvus_client.search(
collection_name=collection_name,
data=[emb_text(question, is_query=True)], # Use query prompt
limit=10, # Get top 10 candidates for reranking
search_params={"metric_type": "IP", "params": {}},
output_fields=["text"], # Return the actual text content
)
print(f"Found {len(search_res[0])} initial candidates")
Step 2: Reranking for Precision
Extract candidate documents and apply reranking:
# Extract candidate documents
candidate_docs = [res["entity"]["text"] for res in search_res[0]]
# Rerank using Qwen3-Reranker
print("Reranking documents...")
reranked_docs = rerank_documents(question, candidate_docs)
# Select top 3 after reranking
top_reranked_docs = reranked_docs[:3]
print(f"Selected top {len(top_reranked_docs)} documents after reranking")
Step 3: Compare Results
Let’s examine how reranking changes the results:
Reranked results (top 3):
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
0.9997891783714294
],
[
"How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",
0.9989748001098633
],
[
"Does the query perform in memory? What are incremental data and historical data?\n\nYes. When a query request comes, Milvus searches both incremental data and historical data by loading them into memory. Incremental data are in the growing segments, which are buffered in memory before they reach the threshold to be persisted in storage engine, while historical data are from the sealed segments that are stored in the object storage. Incremental data and historical data together constitute the whole dataset to search.\n\n###",
0.9984032511711121
]
]
================================================================================
Original embedding-based results (top 3):
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
0.8306853175163269
],
[
"How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",
0.7302717566490173
],
[
"How does Milvus handle vector data types and precision?\n\nMilvus supports Binary, Float32, Float16, and BFloat16 vector types.\n\n- Binary vectors: Store binary data as sequences of 0s and 1s, used in image processing and information retrieval.\n- Float32 vectors: Default storage with a precision of about 7 decimal digits. Even Float64 values are stored with Float32 precision, leading to potential precision loss upon retrieval.\n- Float16 and BFloat16 vectors: Offer reduced precision and memory usage. Float16 is suitable for applications with limited bandwidth and storage, while BFloat16 balances range and efficiency, commonly used in deep learning to reduce computational requirements without significantly impacting accuracy.\n\n###",
0.7003671526908875
]
]
The reranking typically shows much higher discriminative scores (closer to 1.0 for relevant documents) compared to embedding similarity scores.
Step 4: Generate Final Response
Now let’s use the retrieved context to generate a comprehensive answer:
First: Convert the retrieved documents to string format.
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
Provide system prompt and user prompt for the large language model. This prompt is generated from documents retrieved from Milvus.
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
Use GPT-4o to generate a response based on the prompts.
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response.choices[0].message.content)
Expected output:
In Milvus, data is stored in two main forms: inserted data and metadata.
Inserted data, which includes vector data, scalar data, and collection-specific
schema, is stored in persistent storage as incremental logs. Milvus supports
multiple object storage backends for this purpose, including MinIO, AWS S3,
Google Cloud Storage, Azure Blob Storage, Alibaba Cloud OSS, and Tencent
Cloud Object Storage. Metadata for Milvus is generated by its various modules
and stored in etcd.
Wrapping Up
This tutorial demonstrated a complete RAG implementation using Qwen3’s embedding and reranking models. The key takeaways:
Two-stage retrieval (dense + reranking) consistently improves accuracy over embedding-only approaches
Instruction prompting allows domain-specific tuning without retraining
Multilingual capabilities work naturally without additional complexity
Local deployment is feasible with the 0.6B models
The Qwen3 series offers solid performance in a lightweight, open-source package. While not revolutionary, they provide incremental improvements and useful features like instruction prompting that can make a real difference in production systems.
Test these models against your specific data and use cases - what works best always depends on your content, query patterns, and performance requirements.
- What We're Building
- Environment Setup
- Data Preparation
- Model Setup
- Embedding Function
- Reranking Implementation
- Setting Up Milvus Vector Database
- Loading Data into Milvus
- Enhancing RAG with Reranking Technology
- Step 1: Query and Initial Retrieval
- Step 2: Reranking for Precision
- Step 3: Compare Results
- Step 4: Generate Final Response
- Wrapping Up
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



