Building a Milvus Cluster Based on JuiceFS
Collaborations between open-source communities are a magical thing. Not only do passionate, intelligent, and creative volunteers keep open-source solutions innovative, they also work to bring different tools together in interesting and useful ways. Milvus, the world’s most popular vector database, and JuiceFS, a shared file system designed for cloud-native environments, were united in this spirit by their respective open-source communities. This article explains what JuiceFS is, how to build a Milvus cluster based on JuiceFS shared file storage, and the performance users can expect using this solution.
What is JuiceFS?
JuiceFS is a high-performance, open-source distributed POSIX file system, which can be built on top of Redis and S3. It was designed for cloud-native environments and supports managing, analyzing, archiving, and backing up data of any type. JuiceFS is commonly used for solving big data challenges, building artificial intelligence (AI) applications, and log collection. The system also supports data sharing across multiple clients and can be used directly as shared storage in Milvus.
After data, and its corresponding metadata, are persisted to object storage and Redis respectively, JuiceFS serves as a stateless middleware. Data sharing is realized by enabling different applications to dock with each other seamlessly through a standard file system interface. JuiceFS relies on Redis, an open-source in-memory data store, for metadata storage. Redis is used because it guarantees atomicity and provides high performance metadata operations. All data is stored in object storage through the JuiceFS client. The architecture diagram is as follows:
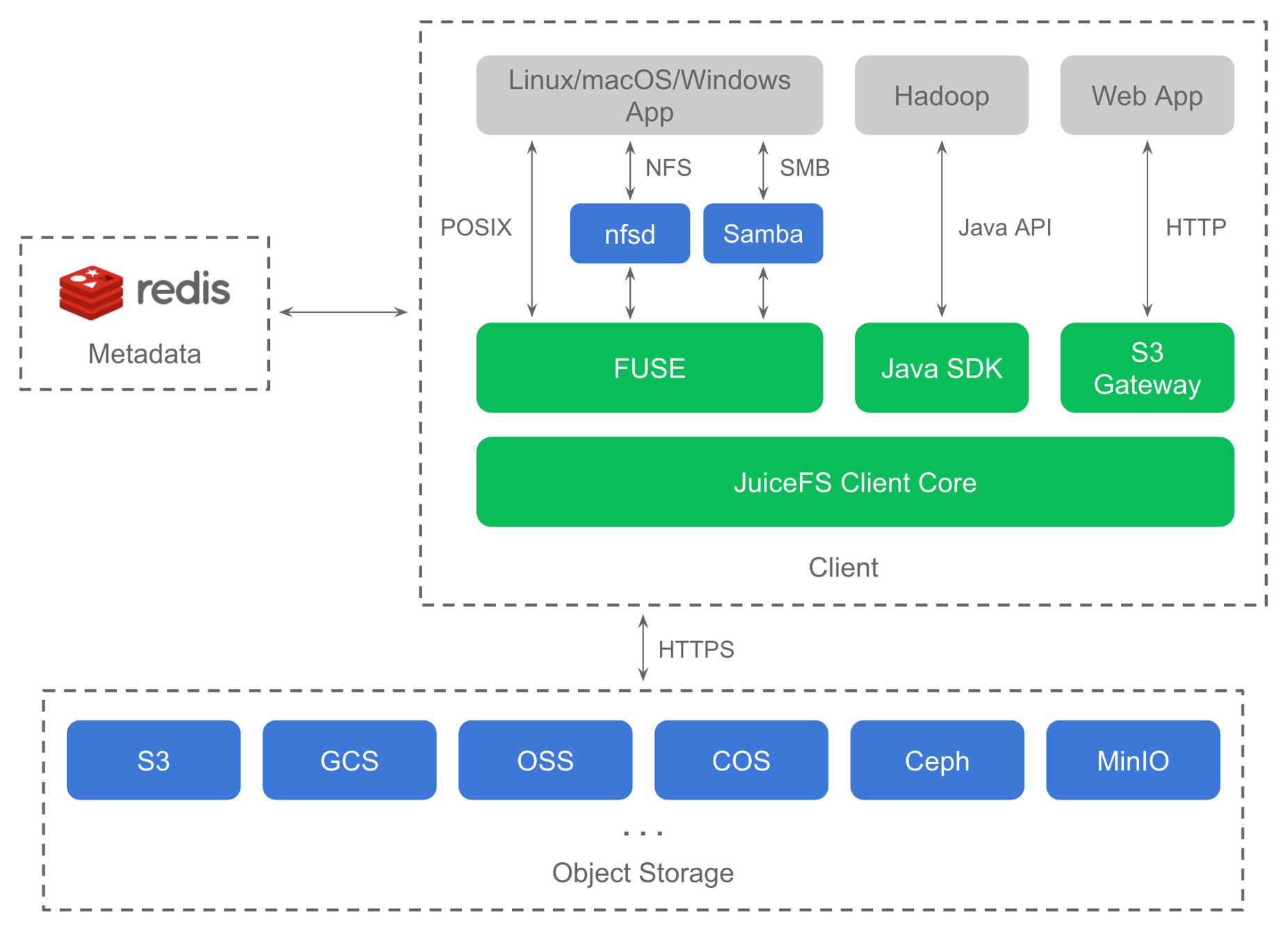 juicefs-architecture.png
juicefs-architecture.png
Build a Milvus cluster based on JuiceFS
A Milvus cluster built with JuiceFS (see architecture diagram below) works by splitting upstream requests using Mishards, a cluster sharding middleware, to cascade the requests down to its sub-modules. When inserting data, Mishards allocates upstream requests to the Milvus write node, which stores newly inserted data in JuiceFS. When reading data, Mishards loads the data from JuiceFS through a Milvus read node to memory for processing, then collects and returns results from sub-services upstream.
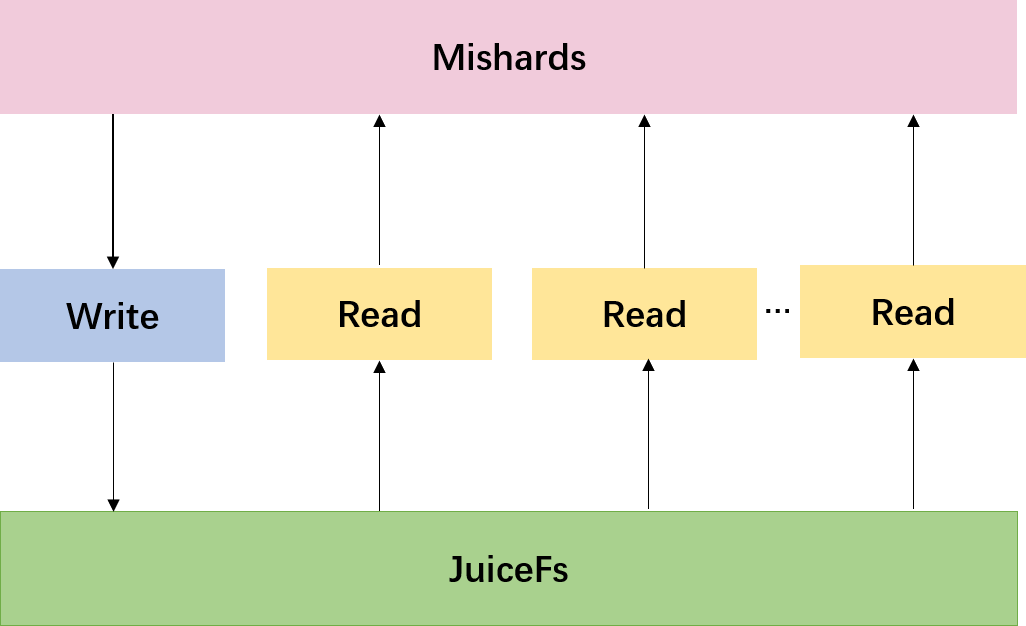 milvus-cluster-built-with-juicefs.png
milvus-cluster-built-with-juicefs.png
Step 1: Launch MySQL service
Launch the MySQL service on any node in the cluster. For details, see Manage Metadata with MySQL.
Step 2: Create a JuiceFS file system
For demonstration purposes, the pre-compiled binary JuiceFS program is used. Download the correct installation package for your system and follow the JuiceFS Quick Start Guide for detailed install instructions. To create a JuiceFS file system, first set up a Redis database for metadata storage. It is recommended that for public cloud deployments you host the Redis service on the same cloud as the application. Additionally, set up object storage for JuiceFS. In this example, Azure Blob Storage is used; however, JuiceFS supports almost all object services. Select the object storage service that best suits the demands of your scenario.
After configuring the Redis service and object storage, format a new file system and mount JuiceFS to the local directory:
1 $ export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=https;AccountName=XXX;AccountKey=XXX;EndpointSuffix=core.windows.net"
2 $ ./juicefs format \
3 --storage wasb \
4 --bucket https://<container> \
5 ... \
6 localhost test #format
7 $ ./juicefs mount -d localhost ~/jfs #mount
8
If the Redis server is not running locally, replace the localhost with the following address:
redis://<user:password>@host:6379/1.
When the installation succeeds, JuiceFS returns the shared storage page /root/jfs.
 installation-success.png
installation-success.png
Step 3: Start Milvus
All the nodes in the cluster should have Milvus installed, and each Milvus node should be configured with read or write permission. Only one Milvus node can be configured as write node, and the rest must be read nodes. First, set the parameters of sections cluster and general in the Milvus system configuration file server_config.yaml:
Section cluster
| Parameter | Description | Configuration |
|---|---|---|
enable | Whether to enable cluster mode | true |
role | Milvus deployment role | rw/ro |
Section general
# meta_uri is the URI for metadata storage, using MySQL (for Milvus Cluster). Format: mysql://<username:password>@host:port/database
general:
timezone: UTC+8
meta_uri: mysql://root:milvusroot@host:3306/milvus
During installation, the configured JuiceFS shared storage path is set as /root/jfs/milvus/db.
1 sudo docker run -d --name milvus_gpu_1.0.0 --gpus all \
2 -p 19530:19530 \
3 -p 19121:19121 \
4 -v /root/jfs/milvus/db:/var/lib/milvus/db \ #/root/jfs/milvus/db is the shared storage path
5 -v /home/$USER/milvus/conf:/var/lib/milvus/conf \
6 -v /home/$USER/milvus/logs:/var/lib/milvus/logs \
7 -v /home/$USER/milvus/wal:/var/lib/milvus/wal \
8 milvusdb/milvus:1.0.0-gpu-d030521-1ea92e
9
After the installation completes, start Milvus and confirm that it is launched properly. Finally, start the Mishards service on any of the nodes in the cluster. The image below shows a successful launch of Mishards. For more information, refer to the GitHub tutorial.
 mishards-launch-success.png
mishards-launch-success.png
Performance benchmarks
Shared storage solutions are usually implemented by network-attached storage (NAS) systems. Commonly used NAS systems types include Network File System (NFS) and Server Message Block (SMB). Public cloud platforms generally provide managed storage services compatible with these protocols, such as Amazon Elastic File System (EFS).
Unlike traditional NAS systems, JuiceFS is implemented based on Filesystem in Userspace (FUSE), where all data reading and writing takes place directly on the application side, further reducing access latency. There are also features unique to JuiceFS that cannot be found in other NAS systems, such as data compression and caching.
Benchmark testing reveals that JuiceFS offers major advantages over EFS. In the metadata benchmark (Figure 1), JuiceFS sees I/O operations per second (IOPS) up to ten times higher than EFS. Additionally, the I/O throughput benchmark (Figure 2) shows JuiceFS outperforms EFS in both single- and multi-job scenarios.
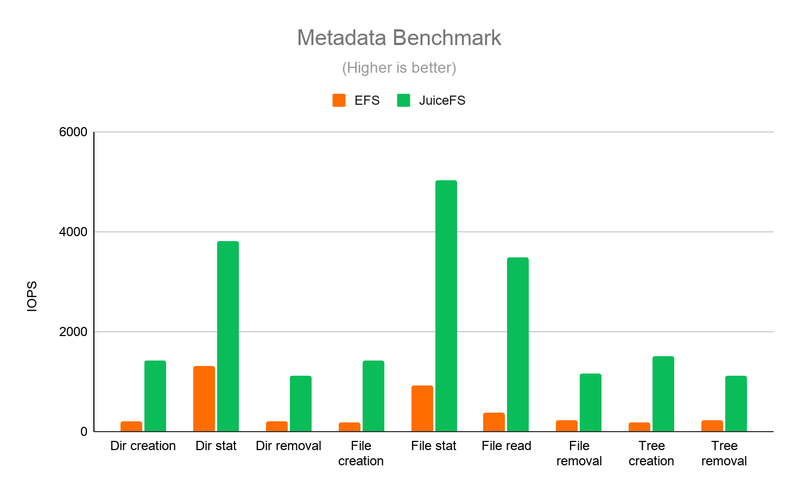 performance-benchmark-1.png
performance-benchmark-1.png
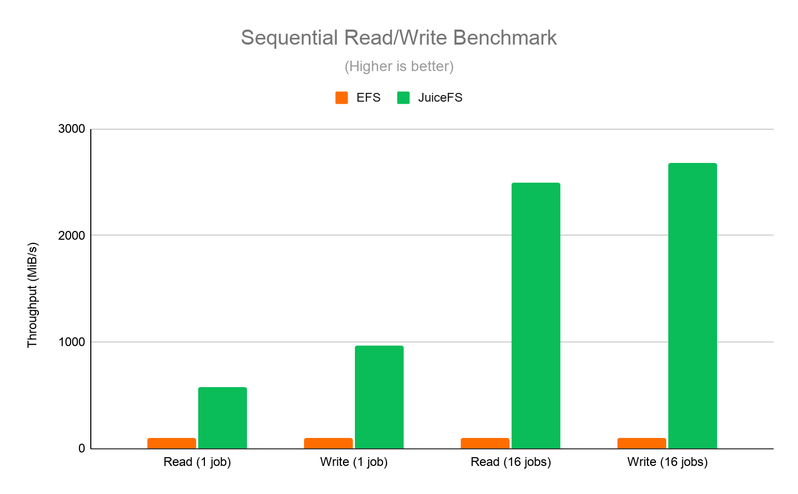 performance-benchmark-2.png
performance-benchmark-2.png
Additionally, benchmark testing shows first query retrieval time, or time to load newly inserted data from disk to memory, for the JuiceFS-based Milvus cluster is just 0.032 seconds on average, indicating that data is loaded from disk to memory almost instantaneously. For this test, first query retrieval time is measured using one million rows of 128-dimensional vector data inserted in batches of 100k at intervals of 1 to 8 seconds.
JuiceFS is a stable and reliable shared file storage system, and the Milvus cluster built on JuiceFS offers both high performance and flexible storage capacity.
Learn more about Milvus
Milvus is a powerful tool capable of powering a vast array of artificial intelligence and vector similarity search applications. To learn more about the project, check out the following resources:
- Read our blog.
- Interact with our open-source community on Slack.
- Use or contribute to the world’s most popular vector database on GitHub.
- Quickly test and deploy AI applications with our new bootcamp.
 writer bio-changjian gao.png
writer bio-changjian gao.png
 writer bio-jingjing jia.png
writer bio-jingjing jia.png
- What is JuiceFS?
- Build a Milvus cluster based on JuiceFS
- Performance benchmarks
- Learn more about Milvus
Content
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word


