AI for Smarter Browsing: Filtering Web Content with Pixtral, Milvus, and Browser Use
As a Developer Advocate for Milvus, I spend a lot of time on Socials, listening to what people have to say about us and if I can help as well. There is a slight clash of worlds though when you look for "Milvus". It is both a Vector DB and genus of bird, meaning that one moment I’m deep in a thread about vector similarity algorithms, the next I’m admiring stunning photographs of black birds flying through the sky.
While both topics are interesting, mixing them up isn’t really helpful in my case, what if there was a smart way to solve this problem without me having to check manually?
Let’s build something smarter - by combining visual understanding with context awareness, we can build an assistant that knows the difference between a black kite’s migration patterns and a new article from us.
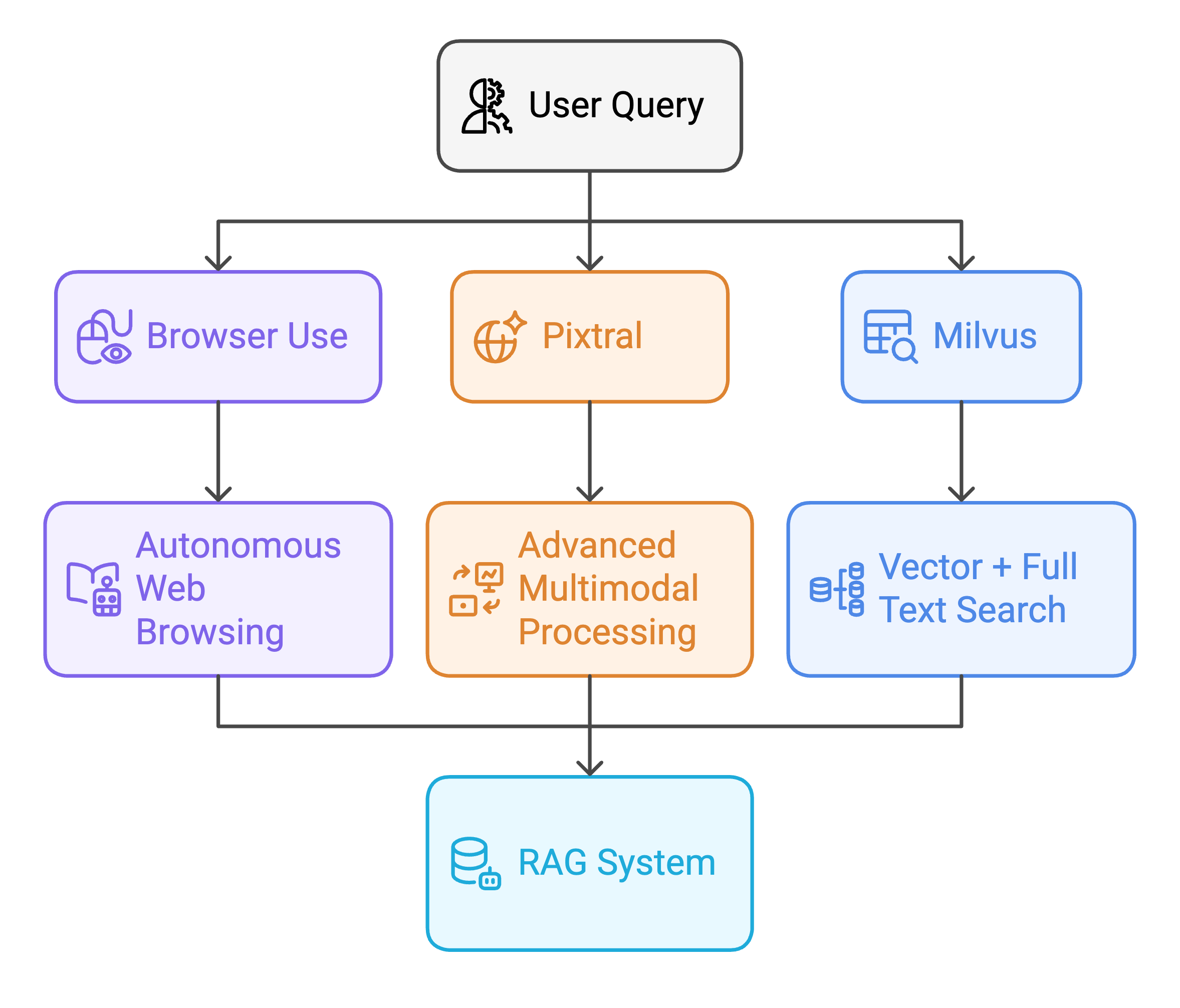
The tech stack
We combine three different technologies:
- Browser-Use: This tool navigates various websites (e.g., Twitter) to fetch content.
- Pixtral: A vision-language model that analyzes images and context. In this example, it distinguishes between a technical diagram about our Vector DB and a stunning bird photograph.
- Milvus: A high performance and open-source Vector DB. His is where we will store the relevant posts for later querying.
Seeing it in action
Let’s have a look at those 2 posts:
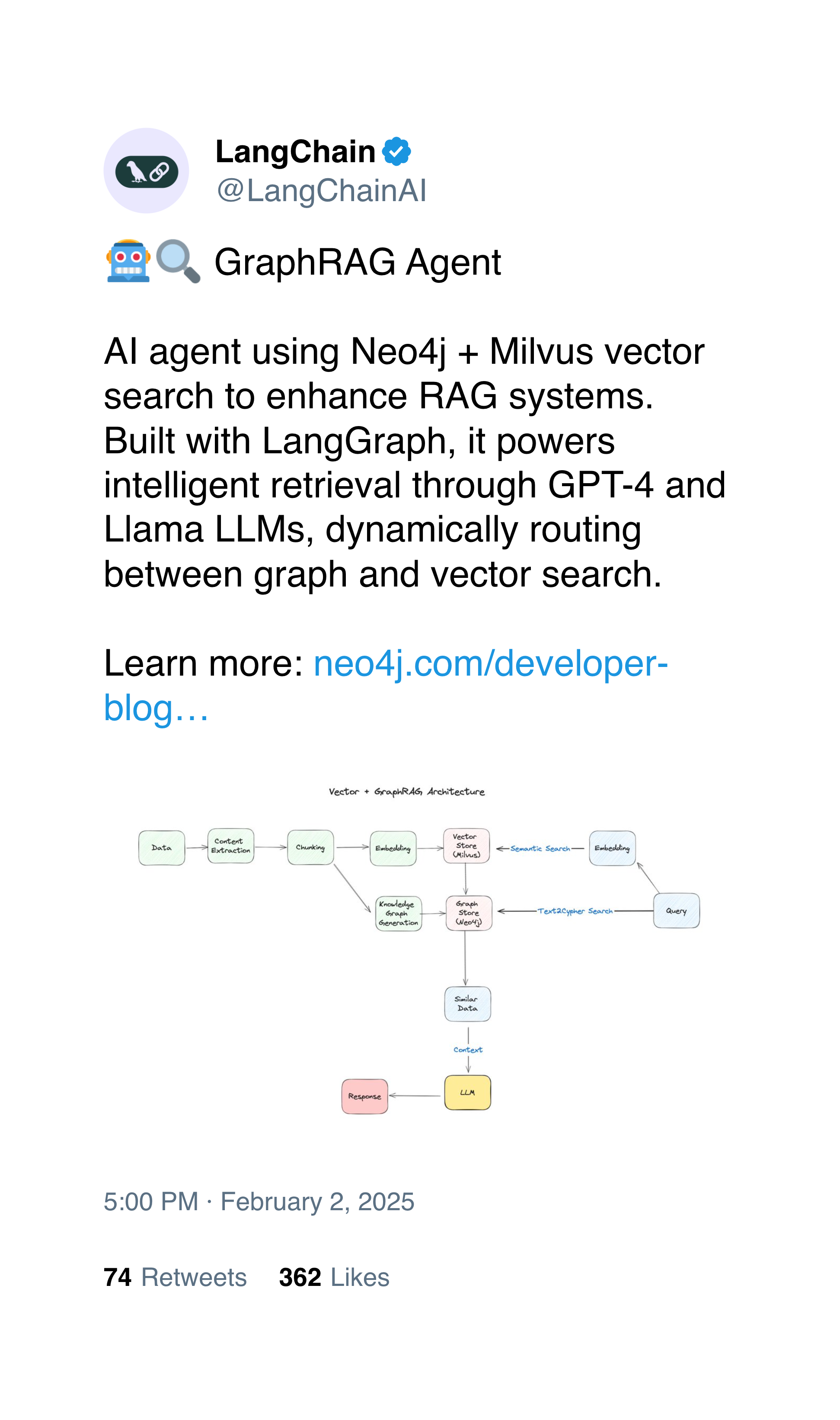

For the one on the left, Pixtral recognizes that this is a post about Milvus, the Vector DB. It mentioned some implementation details, but also an image showing a system diagram, indicating that this is indeed, about the Vector DB. We can see below that Pixtral also thinks the same.
INFO [src.agent.custom_agent] 🧠 New Memory: 1. The post by LangChainAI discusses the 'GraphRAG Agent' which uses Neo4j and Milvus vector search to enhance RAG systems.
2. Replies include praise for the use of Milvus in intelligent retrieval and vector search.
3. Specific mention of Milvus as a key component in innovative RAG systems.
4. No content related to birds or photography was found.
INFO [src.agent.custom_agent] ⏳ Task Progress:
1. Navigated to the post URL. 2. Extracted relevant post content. 3. Analyzed the content for relevance to Milvus, the Vector DB.
INFO [src.agent.custom_agent] 📋 Future Plans:
1. Summarize the findings and confirm the relevance to Milvus. 2. Complete the task by providing a clear and concise report.
INFO [src.agent.custom_agent] 🤔 Thought: The task required analyzing the post content for relevance to Milvus, the Vector DB, ignoring any content about birds or photography. The extracted content is entirely relevant to Milvus and its applications in vector search and RAG systems. I will now summarize the findings and complete the task.
INFO [src.agent.custom_agent] 🎯 Summary: The post and its replies are relevant to Milvus, the Vector DB, focusing on its use in intelligent retrieval and vector search. No content about birds or photography was found.
INFO [src.agent.custom_agent] 🛠️ Action 1/1: {"done":{"text":"The post by LangChainAI discusses the 'GraphRAG Agent,' which uses Neo4j and Milvus vector search to enhance RAG systems. Replies highlight the innovative use of Milvus for intelligent retrieval and vector search, with no mention of birds or photography. The content is entirely relevant to Milvus, the Vector DB."}}
INFO [src.agent.custom_agent] 🧠 All Memory:
1. The post by LangChainAI discusses the 'GraphRAG Agent' which uses Neo4j and Milvus vector search to enhance RAG systems.
2. Replies focus on the innovative use of Milvus for intelligent retrieval and vector search alongside other technologies.
3. No posts or replies are related to birds or photography.
1. The post by LangChainAI discusses the 'GraphRAG Agent' which uses Neo4j and Milvus vector search to enhance RAG systems.
2. Replies include praise for the use of Milvus in intelligent retrieval and vector search.
3. Specific mention of Milvus as a key component in innovative RAG systems.
4. No content related to birds or photography was found.
The one on the right on the other hand isn’t, we can see that this picture, as beautiful as it is, isn’t about a Vector DB. We can see a bird flying in the sky, therefore, Pixtral will consider this one irrelevant.
INFO [src.agent.custom_agent] 🧠 New Memory: The post and comments primarily discuss photography and birds. No references to Milvus the Vector Database are found.
INFO [src.agent.custom_agent] ⏳ Task Progress:
Navigated to the post. Analyzed the content for relevance to Milvus, the Vector DB. No relevant information found.
INFO [src.agent.custom_agent] 🤔 Thought: The content of the post and comments only discusses birds and photography. Since the task specifies ignoring such topics, there is no relevant information for Milvus, the Vector DB. The task can now be concluded.
INFO [src.agent.custom_agent] 🎯 Summary: The post does not contain relevant information for Milvus, the Vector DB. I will conclude the task.
INFO [src.agent.custom_agent] 🛠️ Action 1/1: {"done":{"text":"The post and comments focus on birds and photography. No relevant information related to Milvus, the Vector DB, was found."}}
INFO [src.agent.custom_agent] 🧠 All Memory:
The post and comments primarily discuss photography and birds. No references to Milvus the Vector Database are found.
Now that we have filtered out the posts we don’t want, we can save the relevant ones in Milvus. Making it possible to query them later using either Vector Search or Full Text Search.
Storing Data in Milvus
Dynamic Fields are a must in this case because it’s not always possible to respect the schema that Milvus expects. With Milvus, you just use enable_dynamic_field=True when creating your schema, and that’s it. Here is a code snippet to showcase the process:
from pymilvus import MilvusClient
# Connect to Milvus
client = MilvusClient(uri="http://localhost:19530")
# Create a Schema that handles Dynamic Fields
schema = self.client.create_schema(enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=384)
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)
Then we define the data we want to have access to:
# Prepare data with dynamic fields
data = {
'text': content_str,
'vector': embedding,
'url': url,
'type': content_type,
'metadata': json.dumps(metadata or {})
}
# Insert into Milvus
self.client.insert(
collection_name=self.collection_name,
data=[data]
)
This simple setup means you don’t have to worry about every field being perfectly defined upfront. Just set up the schema to allow for dynamic additions and let Milvus do the heavy lifting.
Conclusion
By combining Browser Use’s web navigation, Pixtral’s visual understanding, and Milvus’s efficient storage, we’ve built an intelligent assistant that truly understands context. Now I am using it to distinguish between birds and vector DB, but the same approach could help with another problem you may be facing.
On my end, I wanna continue working on agents that can help me in my daily work in order to reduce my cognitive load 😌
We’d Love to Hear What You Think!
If you like this blog post, please consider:
- ⭐ Giving us a star on GitHub
- 💬 Joining our Milvus Discord community to share your experiences or if you need help building Agents
- 🔍 Exploring our Bootcamp repository for examples of applications using Milvus
- The tech stack
- Seeing it in action
- Storing Data in Milvus
- Conclusion
- We'd Love to Hear What You Think!
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



