Frustrated with New Data? Our Vector Database can Help
In the era of Big Data, what database technologies and applications will come into the limelight? What will be the next game-changer?
With unstructured data representing roughly 80-90% of all stored data; what are we supposed to do with these growing data lakes? One might think of using traditional analyitical methods, but these fail to pull out useful information, if any info at all. To answer this question, the “Three Musketeers” of Zilliz’s Research and Developement team, Dr. Rentong Guo, Mr. Xiaofan Luan, and Dr. Xiaomeng Yi, have co-authored an article to discuss the design and challenges faced when building a general-purpose vector database system.
This article has been included in Programmer, a journal produced by CSDN, the biggest software developer community in China. This issue of Programmer also includes articles by Jeffrey Ullman, recipient of the 2020 Turing Award, Yann LeCun, recipient of the 2018 Turing Award, Mark Porter, CTO of MongoDB, Zhenkun Yang, founder of OceanBase, Dongxu Huang, founder of PingCAP, etc.
Below we share the full-length article with you:
Introduction
Modern-day data applications can easily deal with structured data, which accounts for roughly 20% of today’s data. In its toolbox are systems like relational databases, NoSQL databases, etc; in contrast, unstructured data, which accounts for roughly 80% of all data, does not have any reliable systems in place. To solve this problem, this article will discuss the pain points that traditional data analytics has with unstructured data and further discuss the architecture and challenges that we faced building up our own general- purpose vector database system.
Data Revolution in the AI era
With the rapid development of 5G and IoT technologies, industries are seeking to multiply their channels of data collection and further project the real world into the digital space. Although it has brought on some tremendous challenges, it has also brought with it tremendous benefits to the growing industry. One of these tough challenges is how to gain deeper insights into this new incoming data.
According to IDC statistics, more than 40,000 exabytes of new data was generated worldwide in 2020 alone. Of the total, only 20% is structured data - data that is highly ordered and easy to organize and analyze via numerical calculations and relational algebra. In contrast, unstructured data (taking up the remaining 80%) is extremely rich in data type variations, making it difficult to uncover the deep semantics through traditional data analytic methods.
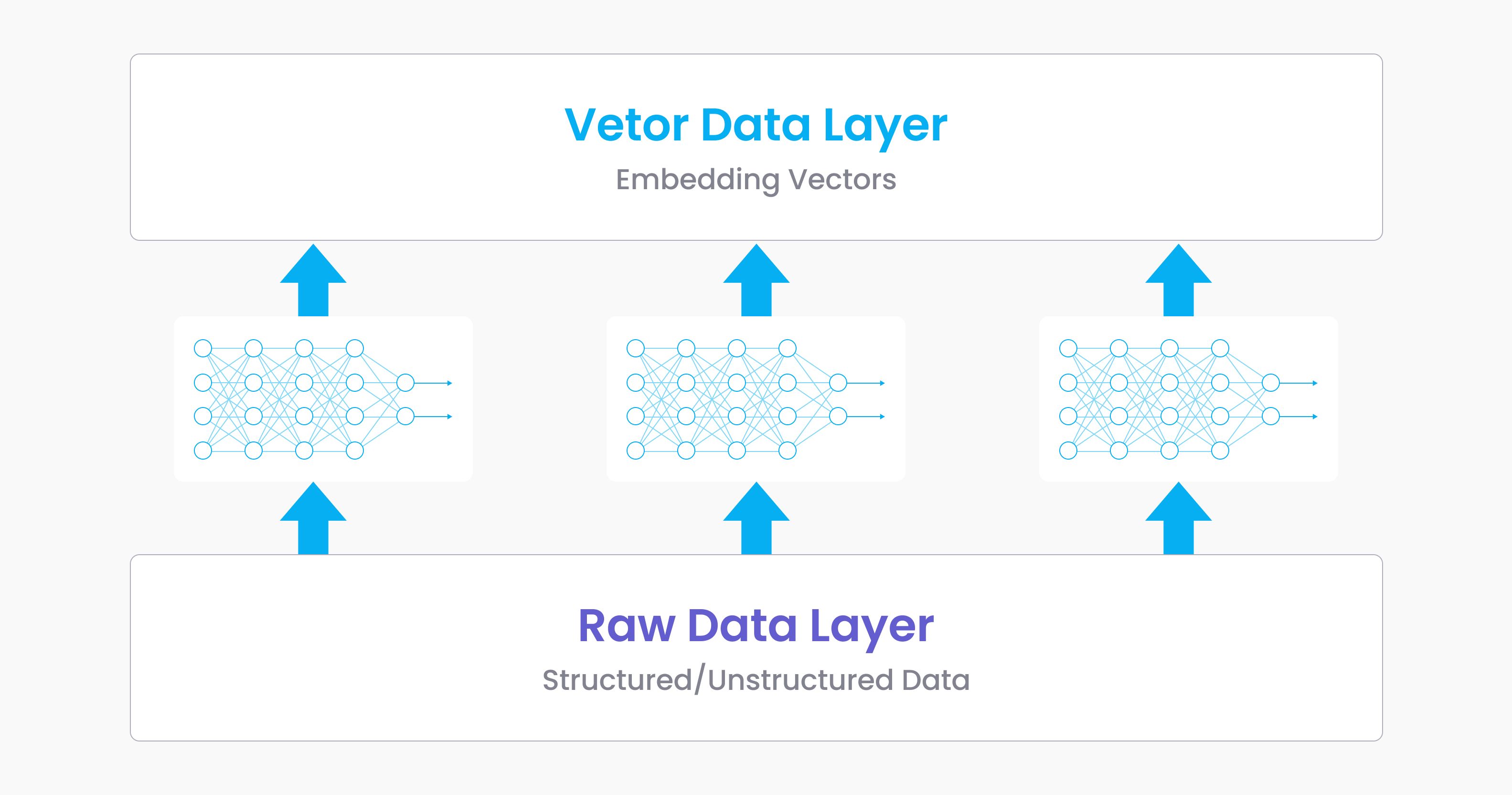
Fortunately, we are experiencing a concurrent, rapid evolution in unstructured data and AI, with AI allowing us to better understand the data through various types of neural networks, as shown in Figure 1.
 newdata1.jpeg
newdata1.jpeg
Embedding technology has quickly gained popularity after the debut of Word2vec, with the idea of “embed everything” reaching all sectors of machine learning. This leads to the emergence of two major data layers: the raw data layer and the vector data layer. The raw data layer is comprised of unstructured data and certain types of structured data; the vector layer is the collection of easily analyzable embeddings that originates from the raw layer passing through machine learning models.
When compared with raw data, vectorized data features the following advantages:
- Embedding vectors are an abstract type of data, meaning we can build a unified algebra system dedicated to reducing the complexity of unstructured data.
- Embedding vectors are expressed through dense floating-point vectors, allowing applications to take advantage of SIMD. With SIMD being supported by GPUs and nearly all modern CPUs, computations across vectors can achieve high performance at a relatively low cost.
- Vector data encoded via machine learning models takes up less storage space than the original unstructured data, allowing for higher throughput.
- Arithmetic can also be performed across embedding vectors. Figure 2 shows an example of cross-modal semantic approximate matching - the pictures shown in the figure are the result of matching words embeddings with image embeddings.
 newdata2.png
newdata2.png
As shown in Figure 3, combining image and word semantics can be done with simple vector addition and subtraction across their corresponding embeddings.
 newdata3.png
newdata3.png
Apart from the above features, these operators support more complicated query statements in practical scenarios. Content recommendation is a well-known example. Generally, the system embeds both the content and the users’ viewing preferences. Next, the system matches the embedded user’s preferences with the most similar embedded content via semantic similarity analysis, resulting in new content that is similar to users’ preferences. This vector data layer isn’t just limited to recommender systems, use cases include e-commerce, malware analysis, data analysis, biometric verification, chemical formula analysis, finance, insurance, etc.
Unstructured data requires a complete basic software stack
System software sits at the foundation of all data-oriented applications, but the data system software built up over the past several decades, e.g. databases, data analysis engines, etc., are meant to deal with structured data. Modern data applications rely almost exclusively on unstructured data and do not benefit from traditional database management systems.
To tackle this issue, we have developed and open-sourced an AI-oriented general-purpose vector database system named Milvus (Reference No. 1~2). When compared with traditional database systems, Milvus works on a different layer of data. Traditional databases, such as relational databases, KV databases, text databases, images/video databases, etc… work on the raw data layer, while Milvus works on the vector data layer.
In the following chapters, we will discuss the novel features, architectural design, and technical challenges we faced when building Milvus.
Major attributes of vector database
Vector databases store, retrieve, analyze vectors, and, just as with any other database, also provide a standard interface for CRUD operations. In addition to these “standard” features, the attributes listed below are also important qualities for a vector database:
- Support for high-efficiency vector operators
Support for vector operators in an analysis engine focuses on two levels. First, the vector database should support different types of operators, for example, semantic similarity matching and semantic arithmetic mentioned above. In addition to this, it should support a variety of similarity metrics for the underlying similarity calculations. Such similarity is usually quantified as spatial distance between vectors, with common metrics being Euclidean distance, cosine distance, and inner product distance.
- Support for vector indexing
Compared to B-tree or LSM-tree based indexes in traditional databases, high-dimensional vector indexes usually consume much more computing resources. We recommend using clustering and graph index algorithms, and giving priority to matrix and vector operations, hence taking full advantage of the hardware vector calculation acceleration abilities previously mentioned.
- Consistent user experience across different deployment environments
Vector databases are usually dveloped and deployed in different environments. At the preliminary stage, data scientists and algorithm engineers work mostly on their laptops and workstations, as they pay more attention to verification efficiency and iteration speed. When verification is completed, they may deploy the full-size database on a private cluster or the cloud. Therefore, a qualified vector database system should deliver consistent performance and user experience across different deployment environments.
- Support for hybrid search
New applications are emerging as vector databases become ubiquitous. Among all these demands, the most frequently mentioned is hybrid search on vectors and other types of data. A few examples of this is approximate nearest neighbor search (ANNS) after scalar filtering, multi-channel recall from full-text search and vector search, and hybrid search of spatio-temporal data and vector data. Such challenges demand elastic scalability and query optimization to effectively fuse vector search engines with KV, text, and other search engines.
- Cloud-native architecture
The volume of vector data mushrooms with the exponential growth of data collection. Trillion-scale, high-dimensional vector data corresponds to thousands of TB of storage, which is far beyond the limit of a single node. As a result, horizontal extendability is a key ability for a vector database, and should satisfy the users’ demands for elasticity and deployment agility. Furthermore, it should also lower the system operation and maintenance complexity while improving observability with the assistance of cloud infrastructure. Some of these needs come in the form of multi-tenant isolation, data snapshot and backup, data encryption, and data visualization, which are common in traditional databases.
Vector database system architecture
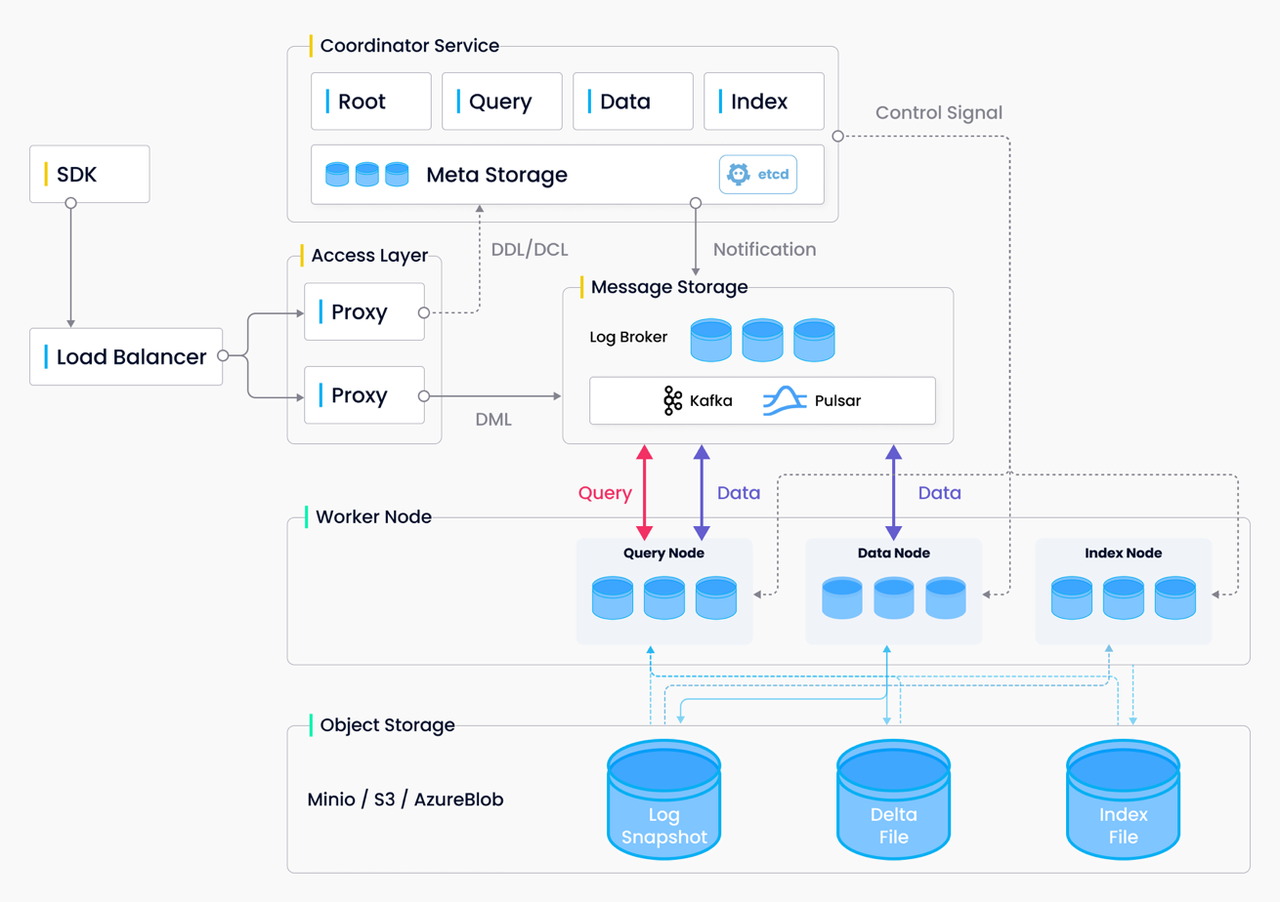
Milvus 2.0 follows the design principles of "log as data", "unified batch and stream processing", "stateless", and "micro-services". Figure 4 depicts the overall architecture of Milvus 2.0.
 newdata4.png
newdata4.png
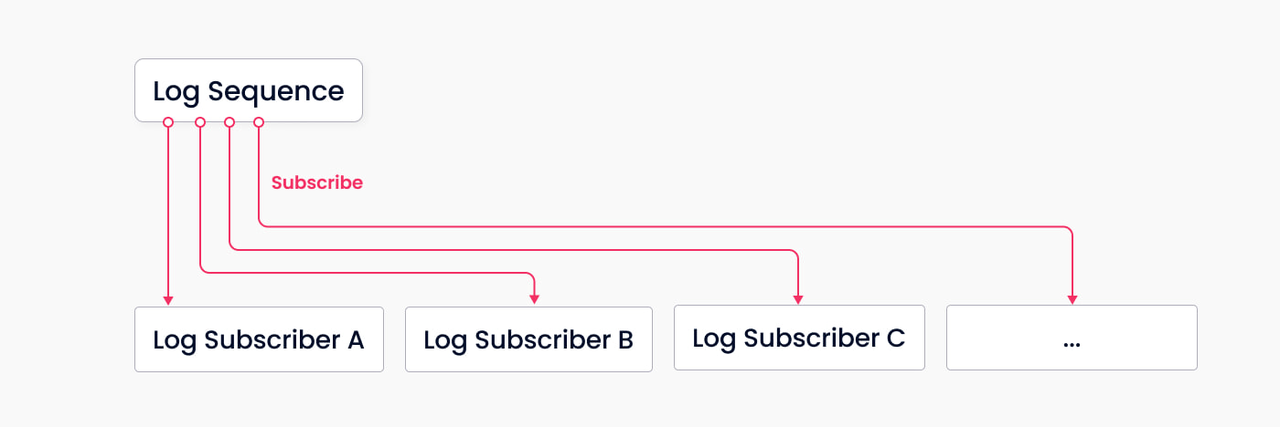
Log as data: Milvus 2.0 does not maintain any physical tables. Instead, it ensures data reliability via log persistence and log snapshots. The log broker (the system’s backbone) stores logs and decouples components and services through the log publication-subscription (pub-sub) mechanism. As shown in Figure 5, the log broker is comprised of “log sequence” and "log subscriber". The log sequence records all operations that change the state of a collection (equivalent to a table in a relational database ); log subscriber subscribes to the log sequence to update its local data and provide services in the form of read-only copies. The pub-sub mechanism also makes room for system extendability in terms of change data capture (CDC) and globally-distributed deployment.
 newdata5.png
newdata5.png
Unified batch and stream processing: Log streaming allows Milvus to update data in real time, thereby ensuring real-time deliverability. Furthermore, by transforming data batches into log snapshots and building index on snapshots, Milvus is able to achieve higher query efficiency. During a query, Milvus merges the query results from both incremental data and historical data to guarantee the integrality of the data returned. Such design better balances real-time performance and efficiency, easing the maintenance burden of both online and offline systems compared to that of the traditional Lambda architecture.
Stateless: Cloud infrastructure and open-source storage components free Milvus from persisting data within its own components. Milvus 2.0 persists data with three types of storage: metadata storage, log storage, and object storage. Metadata storage not only stores the metadata, but also handles services discovery and node management. Log storage executes incremental data persistence and data publication-subscription. Object storage stores log snapshots, indexes, and some intermediate calculation results.
Microservices: Milvus follows the principles of data plane and control plane disaggregation, read/write separation, and online/offline task separation. It is compromised of four layers of service: the access layer, coordinator layer, worker layer, and storage layer. These layers are mutually independent when it comes to scaling and disaster recovery. As the front-facing layer and user endpoint, the access layer handles client connections, validates client requests, and combines query results. As the system’s "brain", the coordinator layer takes on the tasks of cluster topology management, load balancing, data declaration, and data management. The worker layer contains the “limbs” of the system, executing data updates, queries, and index building operations. Finally, the storage layer is in charge of data persistence and replication. Overall, this microservice-based design ensures a controllable system complexity, with each component responsible to its own corresponding function. Milvus clarifies the service boundaries through well-defined interfaces, and decouples the services based on finer granularity, which further optimizes the elastic scalability and resource distribution.
Technical challenges faced by vector databases
Early research on vector databases was mainly concentrated on the design of high-efficiency index structures and query methods - this resulted in a variety of vector search algorithm libraries (Reference No. 3~5). Over the past few years, an increasing number of academic and engineering teams have taken a fresh look at vector search issues from system design perspective, and proposed some systematic solutions. Summarizing existing studies and user demand, we categorize the main technical challenges for vector databases as follows:
- Optimization of cost-to-performance ratio relative to load
Compared to that of traditional data types, analysis of vector data takes much more storage and computing resources because of its high dimensionality. Moreover, users have shown diverse preferences for load characteristics and cost-performance optimization on vector search solutions. For instance, users, who work with extremely large datasets (tens or hundreds of billions of vectors), would prefer solutions with lower data storage costs and variance in search latency, while others may demand higher search performance and a non-varying average latency. To satisfy such diverse preferences, the core index component of the vector database must be able to support index structures and search algorithms with different types of storage and computing hardware.
For example, storing vector data and the corresponding index data in cheaper storage mediums (such as NVM and SSD) should be taken into consideration when lowering storage costs. However, most existing vector search algorithms work on data read directly from memory. To avoid performance loss brought by the usage of disk drives, the vector database should be able to exploit the locality of data access combined with search algorithms in addition to being able to adjust to storage solutions for vector data and index structure (Reference No. 6~8). For the sake of performance improvements, contemporary research has been focused on hardware acceleration technologies involving GPU, NPU, FPGA, etc. (Reference No. 9). However, acceleration-specific hardware and chips vary in architecture design, and the problem of most efficient execution across different hardware accelerators is not yet solved.
- Automated system configuration and tuning
Most existing studies on vector search algorithms seek a flexible balance between storage costs, computational performance, and search accuracy. Generally, both algorithm parameters and data features influence the actual performance of an algorithm. As user demands differ in costs and performance, selecting a vector query method that suits their needs and data features poses a significant challenge.
Nevertheless, manual methods of analyzing the effects of data distribution on search algorithms aren’t effective due to the high dimensionality of the vector data. To address this issue, academia and industry are seeking algorithm recommendation solutions based on machine learning (Reference No. 10).
The design of an ML-powered intelligent vector search algorithm is also a research hotspot. Generally speaking, existing vector search algorithms are developed universally for vector data with various dimensionality and distribution patterns. As a result, they do not support specific index structures according to the data features, and thus have little space for optimization. Future studies should also explore effective machine learning technologies that can tailor index structures for different data features (Reference No. 11-12).
- Support for advanced query semantics
Modern applications often rely on more advanced queries across vectors - traditional nearest neighbour search semantics are no longer applicable to vector data search. Moreover, demand for combined search across multiple vector databases or on vector and non-vector data is emerging (Reference No. 13).
Specifically, variations in distance metrics for vector similarity grow fast. Traditional similarity scores, such as Euclidean distance, inner product distance, and cosine distance cannot satisfy all application demands. With the popularization of artificial intelligence technology, many industries are developing their own field-specific vector similarity metrics, such as Tanimoto distance, Mahalanobis distance, Superstructure, and Substructure. Integrating these evaluation metrics into existing search algorithms and designing novel algorithms utilizing said metrics are both challenging research problems.
As the complexity of user services increase, applications will need to search across both vector data and non-vector data. For example, a content recommender analyzes users’ preferences, social relations, and matches them with current hot topics to pull proper content to users. Such searches normally involve queries on multiple data types or across multiple data processing systems. To support such hybrid searches efficiently and flexibly is another system design challenge.
Authors
Dr. Rentong Guo (Ph.D. of Computer Software and Theory, Huazhong University of Science and Technology), partner and R&D Director of Zilliz. He is a member of China Computer Federation Technical Committee on Distributed Computing and Processing (CCF TCDCP). His research focuses on database, distributed system, caching system, and heterogeneous computing. His research works have been published on several top-tier conferences and journals, including Usenix ATC, ICS, DATE, TPDS. As the architect of Milvus, Dr. Guo is seeking solutions to develop highly scalable and cost-efficient AI-based data analytic systems.
Xiaofan Luan, partner and Engineering Director of Zilliz, and Technical Advisory Committee member of LF AI & Data Foundation. He worked successively in the Oracle US headquarters and Hedvig, a software defined storage startup. He joined Alibaba Cloud Database team and was in charge of the development of NoSQL database HBase and Lindorm. Luan obtained his master’s degree in Electronic Computer Engineering from Cornell University.
Dr. Xiaomeng Yi (Ph.D. of Computer Architecture, Huazhong University of Science and Technology), Senior Researcher and Research team leader of Zilliz. His research concentrates on high-dimension data management, large-scale information retrieval, and resource allocation in distributed systems. Dr. Yi’s research works have been published on leading journals and international conferences including IEEE Network Magazine, IEEE/ACM TON, ACM SIGMOD, IEEE ICDCS, and ACM TOMPECS.
Filip Haltmayer, a Zilliz Data Engineer, graduated from University of California, Santa Cruz with a BS in Computer Science. After joining Zilliz, Filip spends most of his time working on cloud deployments, client interactions, techincal talks, and AI application development.
References
- Milvus Project: https://github.com/milvus-io/milvus
- Milvus: A Purpose-Built Vector Data Management System, SIGMOD’21
- Faiss Project: https://github.com/facebookresearch/faiss
- Annoy Project: https://github.com/spotify/annoy
- SPTAG Project: https://github.com/microsoft/SPTAG
- GRIP: Multi-Store Capacity-Optimized High-Performance Nearest Neighbor Search for Vector Search Engine, CIKM’19
- DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node, NIPS’19
- HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory, NIPS’20
- SONG: Approximate Nearest Neighbor Search on GPU, ICDE’20
- A demonstration of the ottertune automatic database management system tuning service, VLDB’18
- The Case for Learned Index Structures, SIGMOD’18
- Improving Approximate Nearest Neighbor Search through Learned Adaptive Early Termination, SIGMOD’20
- AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data, VLDB’20
Engage with our open-source community:
- Introduction
- Data Revolution in the AI era
- Unstructured data requires a complete basic software stack
- Major attributes of vector database
- Vector database system architecture
- Technical challenges faced by vector databases
- Authors
- References
- Engage with our open-source community:
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



