Improvements of the Data File Cleanup Mechanism
author: Yihua Mo
Date: 2019-12-18
Previous delete strategy and related problems
In Managing Data in Massive-Scale Vector Search Engine, we mentioned the delete mechanism of data files. Delete includes soft-delete and hard-delete. After performing a delete operation on a table, the table is marked with soft-delete. Search or update operations afterwards are no longer allowed. However, the query operation that starts before delete can still run. The table is really deleted together with metadata and other files only when the query operation is complete.
So, when the files marked with soft-delete are really deleted? Before 0.6.0, the strategy is that a file is really deleted after soft-deleted for 5 minutes. The following figure displays the strategy:
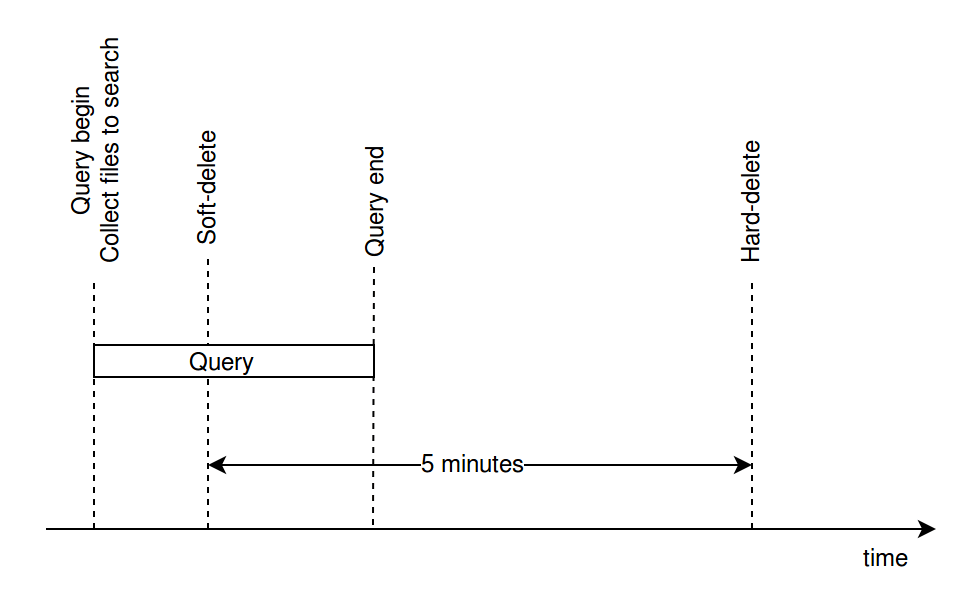 5mins
5mins
This strategy is based on the premise that queries normally do not last more than 5 minutes and is not reliable. If a query lasts more than 5 minutes, the query will fail. The reason is that when a query starts, Milvus collects information about files that can be searched and creates query tasks. Then, the query scheduler loads files to memory one by one and searches for files one by one. If a file no longer exists when loading a file, the query will fail.
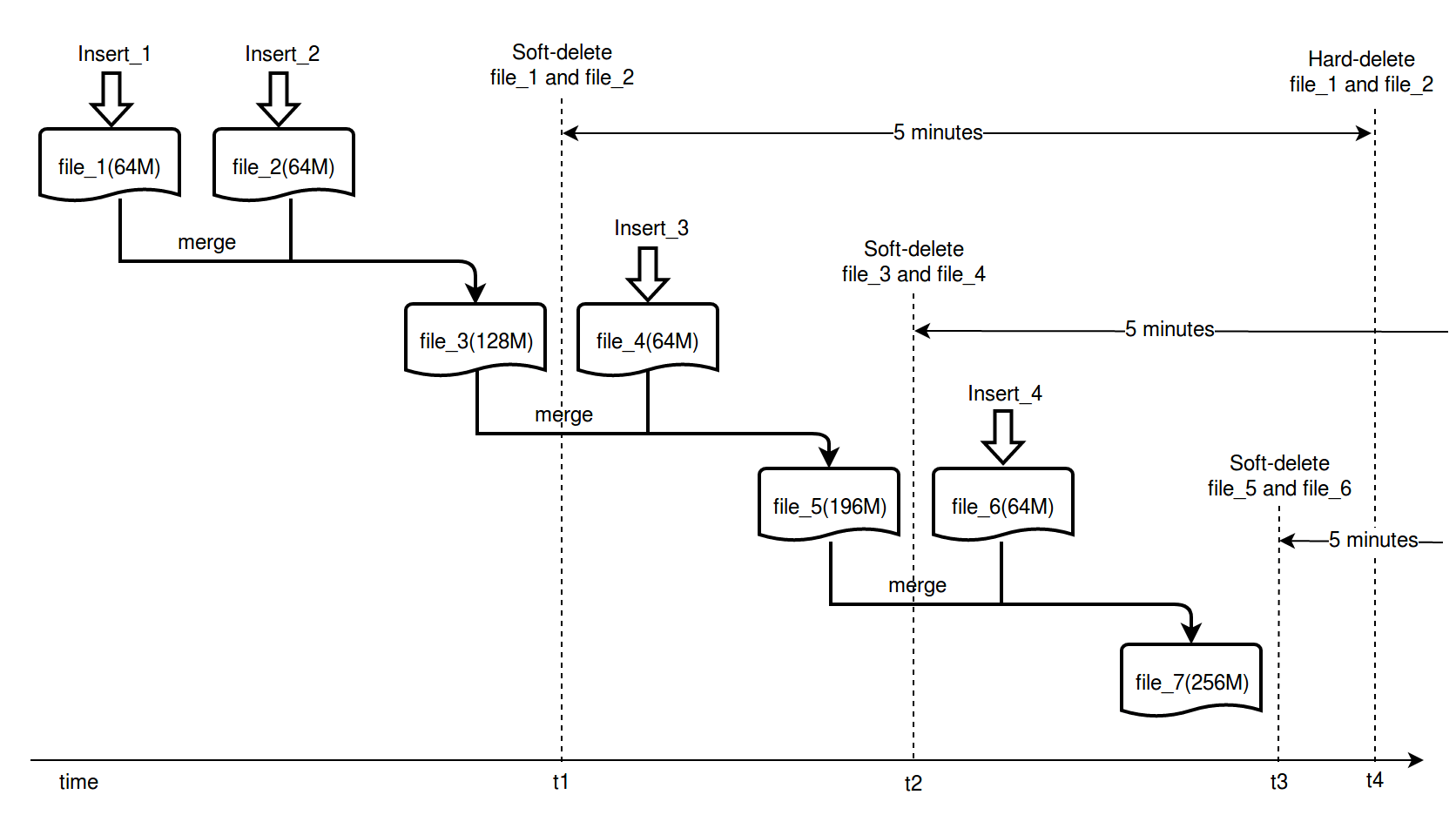
Extending the time may help reduce the risk of query failures, but also causes another problem: disk usage is too large. The reason is that when large quantities of vectors are being inserted, Milvus continually combines data files and the combined files are not immediately removed from the disk, even though no query happens. If data insertion is too fast and/or the amount of inserted data is too large, extra disk usage can amount to tens of GBs. Refer to the following figure as an example:
 result
result
As shown in the previous figure, the first batch of inserted data (insert_1) is flushed to disk and becomes file_1, then insert_2 becomes file_2. The thread responsible for file combination combines the files to file_3. Then, file_1 and file_2 are marked as soft-delete. The third batch of insert data becomes file_4. The thread combines file_3 and file_4 to file_5 and marks file_3 and file_4 as soft-delete.
Likewise, insert_6 and insert_5 are combined. In t3, file_5 and file_6 are marked as soft-delete. Between t3 and t4, although many files are marked as soft-delete, they are still in the disk. Files are really deleted after t4. Thus, between t3 and t4, the disk usage is 64 + 64 + 128 + 64 + 196 + 64 + 256 = 836 MB. The inserted data is 64 + 64 + 64 + 64 = 256 MB. The disk usage is 3 times the size of inserted data. The faster the write speed of the disk, the higher the disk usage during a specific time period.
Improvements of the delete strategy in 0.6.0
Thus, we changed the strategy to delete files in v0.6.0. Hard-delete no longer uses time as triggers. Instead, the trigger is when the file is not in use by any task.
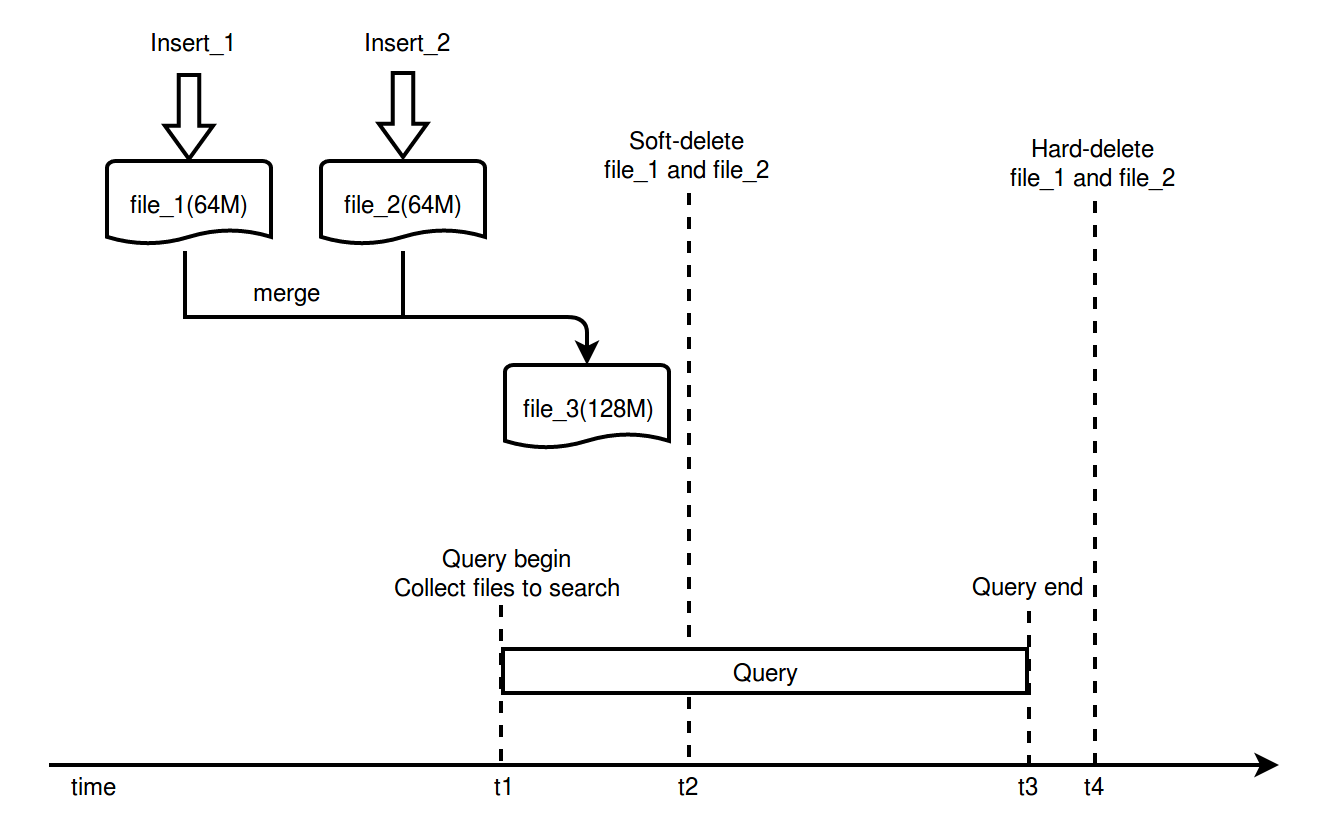 newstrategy
newstrategy
Assume two batches of vectors are inserted. In t1 a query request is given, Milvus acquires two files to be queried (file_1 and file_2, because file_3 still does not exist.) Then, the backend thread starts combining the two files with the query running at the same time. When file_3 is generated, file_1 and file_2 are marked as soft-delete. After the query, no other tasks will use file_1 and file_2, so they will be hard-deleted in t4. The interval between t2 and t4 is very small and depends on the interval of the query. In this way, unused files will be removed in time.
As for internal implementation, reference counting, which is familiar to software engineers, is used to determine whether a file can be hard-deleted. To explain using comparison, when a player has lives in a game, he can still play. When the number of lives becomes 0, the game is over. Milvus monitors the status of each file. When a file is used by a task, a life will be added to the file. When the file is no longer used, a life will be removed from the file. When a file is marked with soft-delete and the number of lives is 0, the file is ready for hard-delete.
Related blogs
- Previous delete strategy and related problems
- Improvements of the delete strategy in 0.6.0
- Related blogs
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word