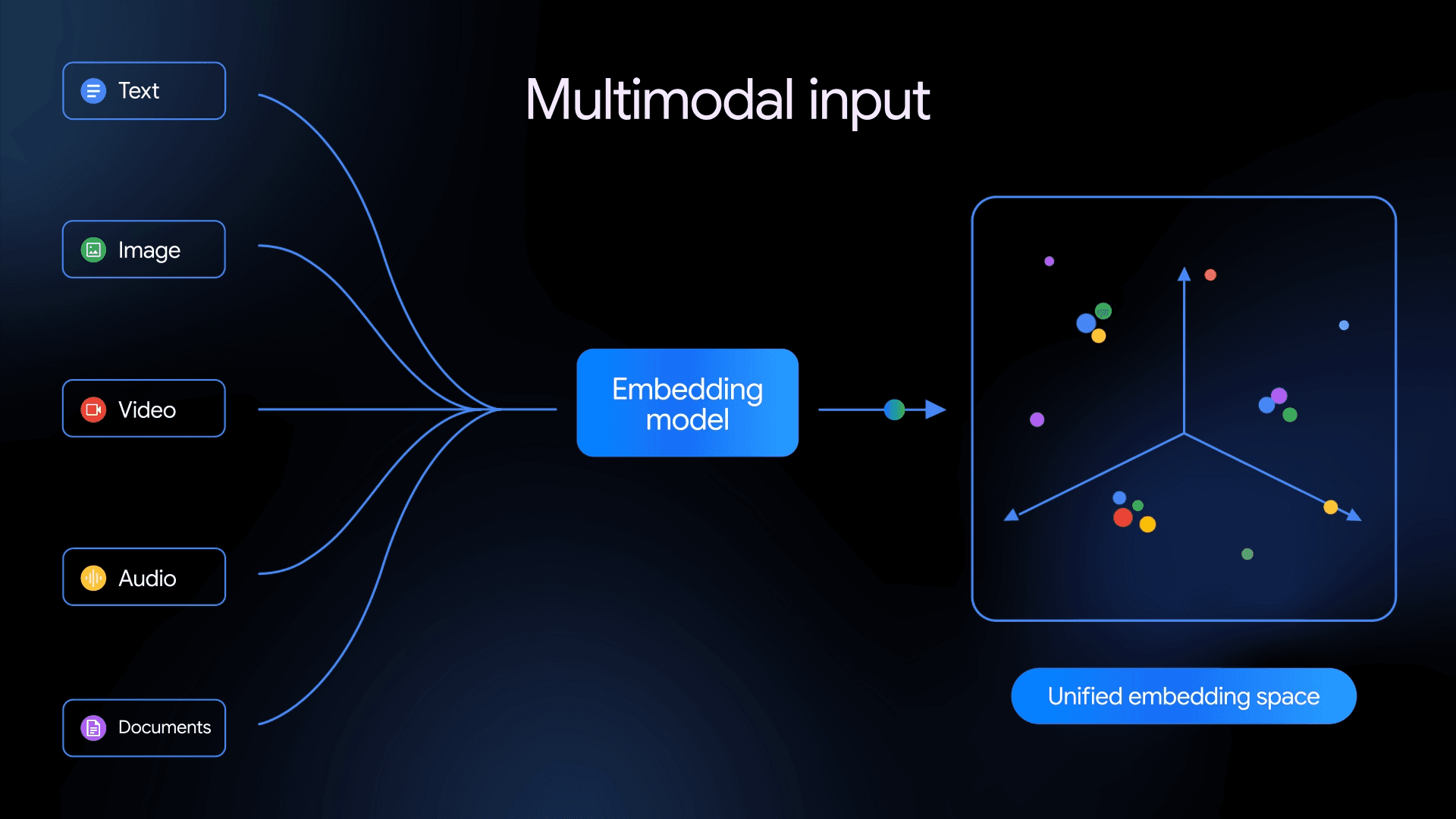
Introducing PyMilvus Integration with Embedding Models
Milvus is an open-source vector database designed specifically for AI applications. Whether you’re working on machine learning, deep learning, or any other AI-related project, Milvus offers a robust and efficient way to handle large-scale vector data.
Now, with the model module integration in PyMilvus, the Python SDK for Milvus, it’s even easier to add Embedding and Reranking models. This integration simplifies transforming your data into searchable vectors or reranking results for more accurate outcomes, such as in Retrieval Augmented Generation (RAG).
In this blog, we will review dense embedding models, sparse embedding models, and re-rankers and demonstrate how to use them in practice using Milvus Lite, a lightweight version of Milvus that can run locally in your Python applications.
Dense vs Sparse Embeddings
Before we walk you through how to use our integrations, let’s look at two main categories of vector embeddings.
Vector Embeddings generally fall into two main categories: Dense Embeddings and Sparse Embeddings.
Dense Embeddings are high-dimensional vectors in which most or all elements are non-zero, making them ideal for encoding text semantics or fuzzy meaning.
Sparse Embeddings are high-dimensional vectors with many zero elements, better suited for encoding exact or adjacent concepts.
Milvus supports both types of embeddings and offers hybrid search. Hybrid Search allows you to conduct searches across various vector fields within the same collection. These vectors can represent different facets of data, use diverse embedding models, or employ distinct data processing methods, combining the results using re-rankers.
How to Use Our Embedding and Reranking Integrations
In the following sections, we’ll demonstrate three practical examples of using our integrations to generate embeddings and conduct vector searches.
Example 1: Use the Default Embedding Function to Generate Dense Vectors
You must install the pymilvus client with the model package to use embedding and reranking functions with Milvus.
pip install "pymilvus[model]"
This step will install Milvus Lite, allowing you to run Milvus locally within your Python application. It also includes the model subpackage, which includes all utilities for Embedding and reranking.
The model subpackage supports various embedding models, including those from OpenAI, Sentence Transformers, BGE-M3, BM25, SPLADE, and Jina AI pre-trained models.
This example uses the DefaultEmbeddingFunction, based on the all-MiniLM-L6-v2 Sentence Transformer model for simplicity. The model is about 70MB and will be downloaded during the first use:
from pymilvus import model
# This will download "all-MiniLM-L6-v2", a lightweight model.
ef = model.DefaultEmbeddingFunction()
# Data from which embeddings are to be generated
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
embeddings = ef.encode_documents(docs)
print("Embeddings:", embeddings)
# Print dimension and shape of embeddings
print("Dim:", ef.dim, embeddings[0].shape)
The expected output should be something like the following:
Embeddings: [array([-3.09392996e-02, -1.80662833e-02, 1.34775648e-02, 2.77156215e-02,
-4.86349640e-03, -3.12581174e-02, -3.55921760e-02, 5.76934684e-03,
2.80773244e-03, 1.35783911e-01, 3.59678417e-02, 6.17732145e-02,
...
-4.61330153e-02, -4.85207550e-02, 3.13997865e-02, 7.82178566e-02,
-4.75336798e-02, 5.21207601e-02, 9.04406682e-02, -5.36676683e-02],
dtype=float32)]
Dim: 384 (384,)
Example 2: Generate Sparse Vectors Using The BM25 Model
BM25 is a well-known method that uses word occurrence frequencies to determine the relevance between queries and documents. In this example, we’ll show how to use BM25EmbeddingFunction to generate sparse embeddings for queries and documents.
In BM25, it’s important to calculate the statistics in your documents to obtain the IDF (Inverse Document Frequency), which can represent the patterns in your documents. The IDF measures how much information a word provides, whether it’s common or rare across all documents.
from pymilvus.model.sparse import BM25EmbeddingFunction
# 1. Prepare a small corpus to search
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
query = "Where was Turing born?"
bm25_ef = BM25EmbeddingFunction()
# 2. Fit the corpus to get BM25 model parameters on your documents.
bm25_ef.fit(docs)
# 3. Store the fitted parameters to expedite future processing.
bm25_ef.save("bm25_params.json")
# 4. Load the saved params
new_bm25_ef = BM25EmbeddingFunction()
new_bm25_ef.load("bm25_params.json")
docs_embeddings = new_bm25_ef.encode_documents(docs)
query_embeddings = new_bm25_ef.encode_queries([query])
print("Dim:", new_bm25_ef.dim, list(docs_embeddings)[0].shape)
Example 3: Using a ReRanker
A search system aims to find the most relevant results quickly and efficiently. Traditionally, methods like BM25 or TF-IDF have been used to rank search results based on keyword matching. Recent methods, such as embedding-based cosine similarity, are straightforward but can sometimes miss the subtleties of language and, most importantly, the interaction between documents and a query’s intent.
This is where using a re-ranker helps. A re-ranker is an advanced AI model that takes the initial set of results from a search—often provided by an embeddings/token-based search—and re-evaluates them to ensure they align more closely with the user’s intent. It looks beyond the surface-level matching of terms to consider the deeper interaction between the search query and the content of the documents.
For this example, we’ll use the Jina AI Reranker.
from pymilvus.model.reranker import JinaRerankFunction
jina_api_key = "<YOUR_JINA_API_KEY>"
rf = JinaRerankFunction("jina-reranker-v1-base-en", jina_api_key)
query = "What event in 1956 marked the official birth of artificial intelligence as a discipline?"
documents = [
"In 1950, Alan Turing published his seminal paper, 'Computing Machinery and Intelligence,' proposing the Turing Test as a criterion of intelligence, a foundational concept in the philosophy and development of artificial intelligence.",
"The Dartmouth Conference in 1956 is considered the birthplace of artificial intelligence as a field; here, John McCarthy and others coined the term 'artificial intelligence' and laid out its basic goals.",
"In 1951, British mathematician and computer scientist Alan Turing also developed the first program designed to play chess, demonstrating an early example of AI in game strategy.",
"The invention of the Logic Theorist by Allen Newell, Herbert A. Simon, and Cliff Shaw in 1955 marked the creation of the first true AI program, which was capable of solving logic problems, akin to proving mathematical theorems."
]
results = rf(query, documents)
for result in results:
print(f"Index: {result.index}")
print(f"Score: {result.score:.6f}")
print(f"Text: {result.text}\n")
The expected output is similar to the following:
Index: 1
Score: 0.937096
Text: The Dartmouth Conference in 1956 is considered the birthplace of artificial intelligence as a field; here, John McCarthy and others coined the term 'artificial intelligence' and laid out its basic goals.
Index: 3
Score: 0.354210
Text: The invention of the Logic Theorist by Allen Newell, Herbert A. Simon, and Cliff Shaw in 1955 marked the creation of the first true AI program, which was capable of solving logic problems, akin to proving mathematical theorems.
Index: 0
Score: 0.349866
Text: In 1950, Alan Turing published his seminal paper, 'Computing Machinery and Intelligence,' proposing the Turing Test as a criterion of intelligence, a foundational concept in the philosophy and development of artificial intelligence.
Index: 2
Score: 0.272896
Text: In 1951, British mathematician and computer scientist Alan Turing also developed the first program designed to play chess, demonstrating an early example of AI in game strategy.
Star Us On GitHub and Join Our Discord!
If you liked this blog post, consider starring Milvus on GitHub, and feel free to join our Discord! 💙
- Dense vs Sparse Embeddings
- How to Use Our Embedding and Reranking Integrations
- Example 1: Use the Default Embedding Function to Generate Dense Vectors
- Example 2: Generate Sparse Vectors Using The BM25 Model
- Example 3: Using a ReRanker
- Star Us On GitHub and Join Our Discord!
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word