Introducing DeepSearcher: A Local Open Source Deep Research
 DeepSearcher
DeepSearcher
In the previous post, “I Built a Deep Research with Open Source—and So Can You!”, we explained some of the principles underlying research agents and constructed a simple prototype that generates detailed reports on a given topic or question. The article and corresponding notebook demonstrated the fundamental concepts of tool use, query decomposition, reasoning, and reflection. The example in our previous post, in contrast to OpenAI’s Deep Research, ran locally, using only open-source models and tools like Milvus and LangChain. (I encourage you to read the above article before continuing.)
In the following weeks, there was an explosion of interest in understanding and reproducing OpenAI’s Deep Research. See, for example, Perplexity Deep Research and Hugging Face’s Open DeepResearch. These tools differ in architecture and methodology although sharing an objective: iteratively research a topic or question by surfing the web or internal documents and output a detailed, informed, and well-structured report. Importantly, the underlying agent automates reasoning about what action to take at each intermediate step.
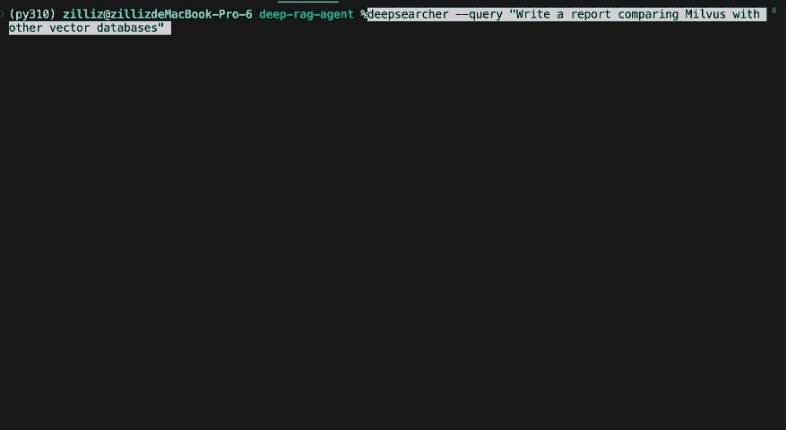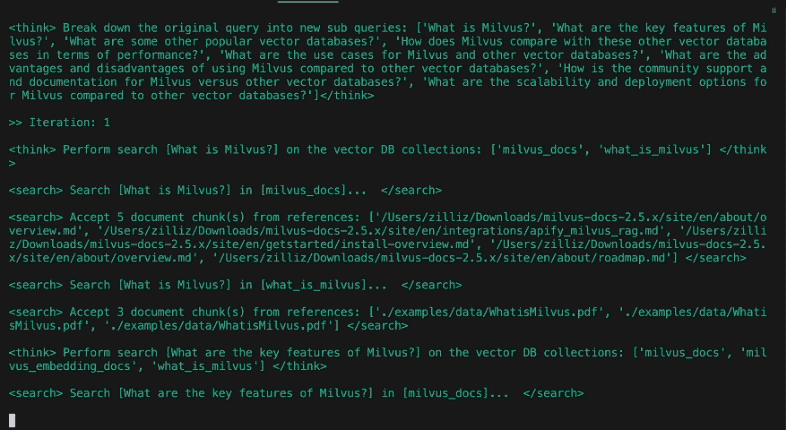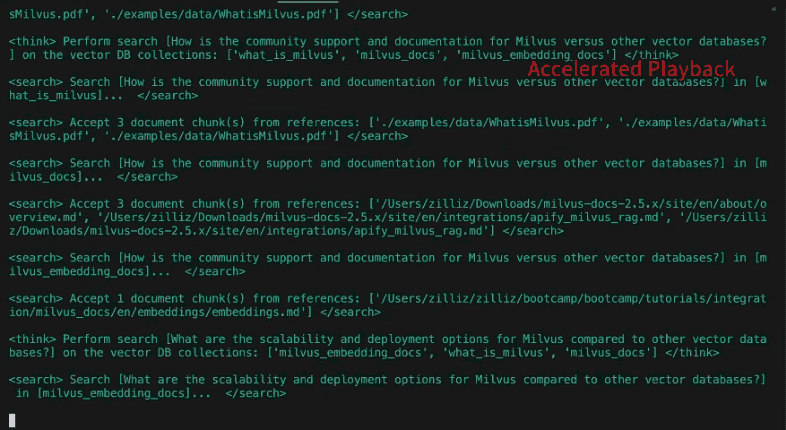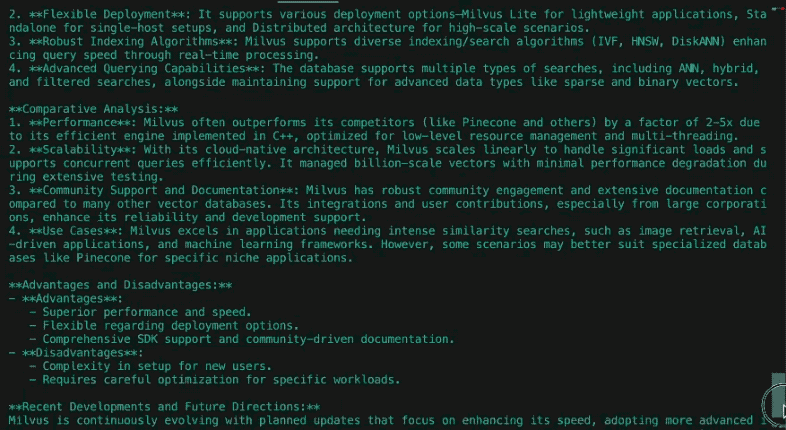
In this post, we build upon our previous post and present Zilliz’s DeepSearcher open-source project. Our agent demonstrates additional concepts: query routing, conditional execution flow, and web crawling as a tool. It is presented as a Python library and command-line tool rather than a Jupyter notebook and is more fully-featured than our previous post. For example, it can input multiple source documents and can set the embedding model and vector database used via a configuration file. While still relatively simple, DeepSearcher is a great showcase of agentic RAG and is a further step towards a state-of-the-art AI applications.
Additionally, we explore the need for faster and more efficient inference services. Reasoning models make use of “inference scaling”, that is, extra computation, to improve their output, and that combined with the fact that a single report may require hundreds or thousands of LLM calls results in inference bandwidth being the primary bottleneck. We use the DeepSeek-R1 reasoning model on SambaNova’s custom-built hardware, which is twice as fast in output tokens-per-second as the nearest competitor (see figure below).
SambaNova Cloud also provides inference-as-a-service for other open-source models including Llama 3.x, Qwen2.5, and QwQ. The inference service runs on SambaNova’s custom chip called the reconfigurable dataflow unit (RDU), which is specially designed for efficient inference on Generative AI models, lowering cost and increasing inference speed. Find out more on their website.
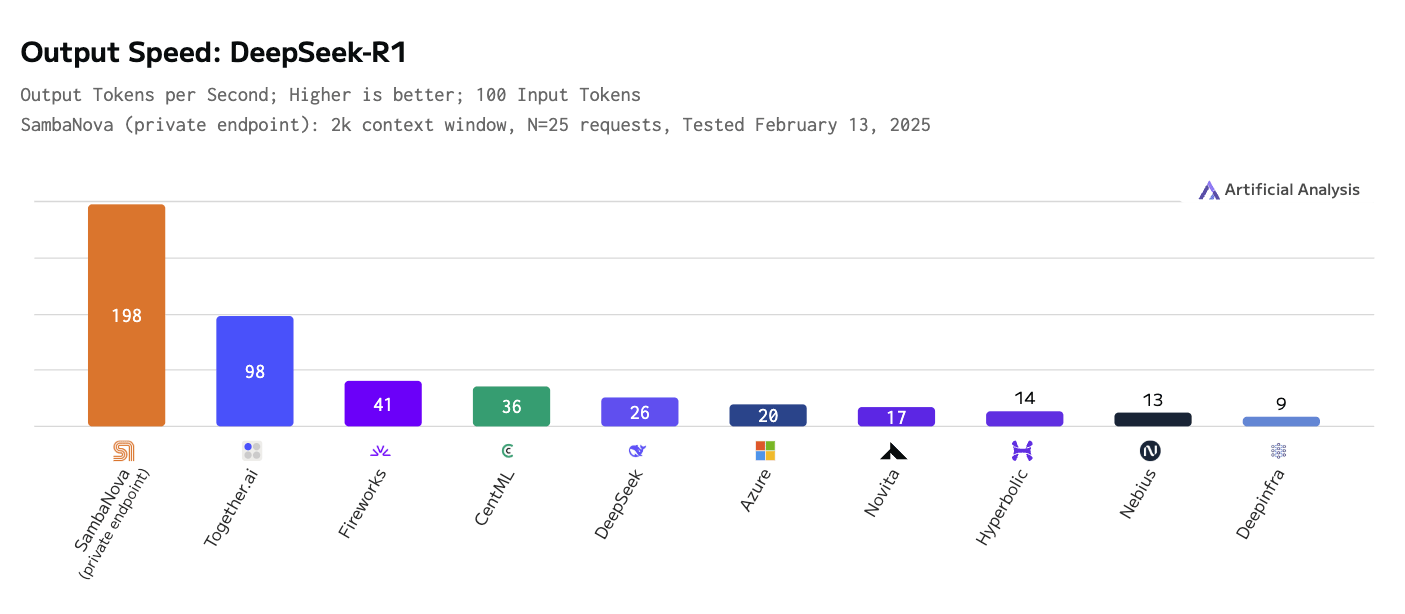 Output Speed- DeepSeek R1
Output Speed- DeepSeek R1
DeepSearcher Architecture
The architecture of DeepSearcher follows our previous post by breaking the problem up into four steps - define/refine the question, research, analyze, synthesize - although this time with some overlap. We go through each step, highlighting DeepSearcher’s improvements.
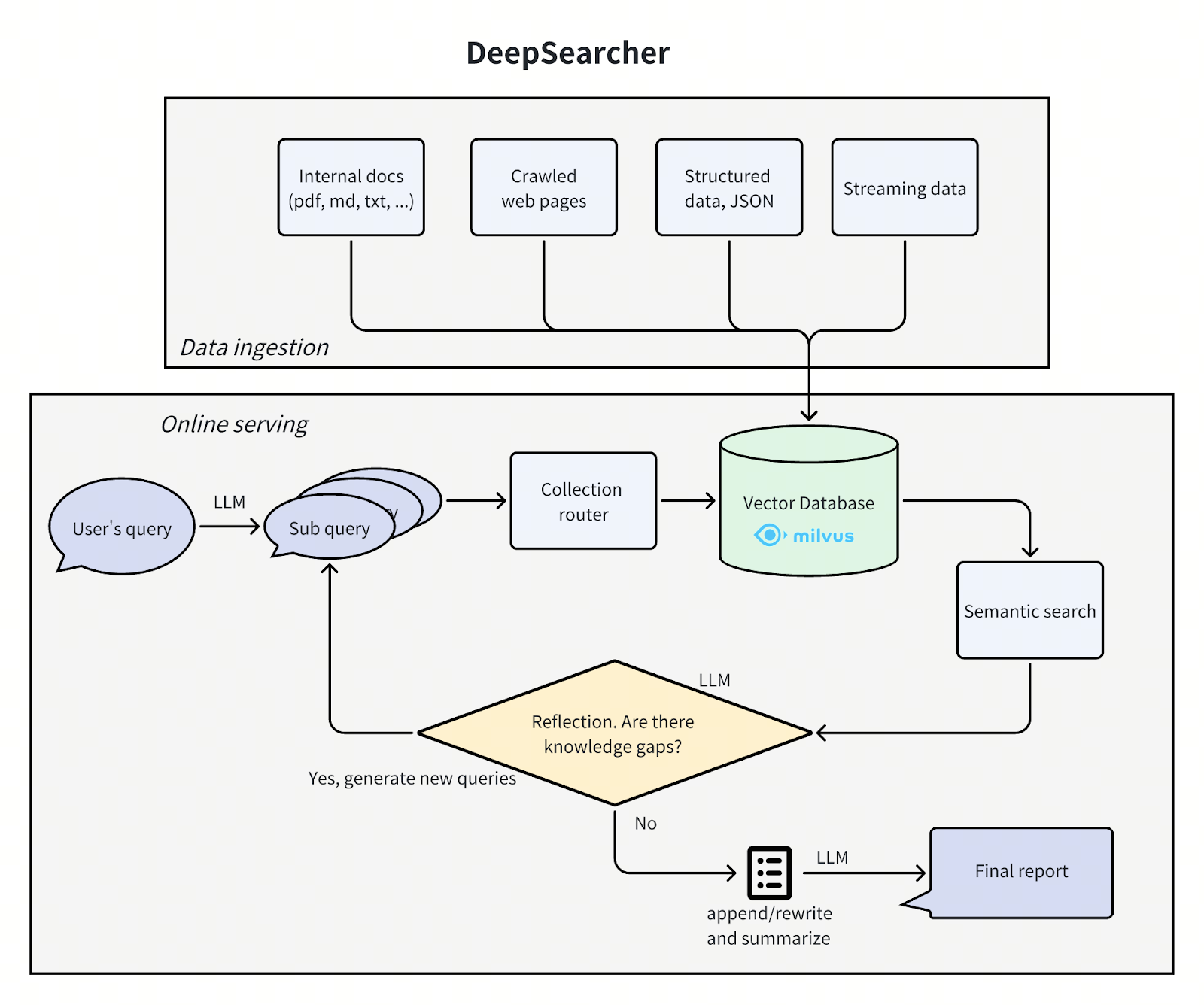 DeepSearcher Architecture
DeepSearcher Architecture
Define and Refine the Question
Break down the original query into new sub queries: [
'How has the cultural impact and societal relevance of The Simpsons evolved from its debut to the present?',
'What changes in character development, humor, and storytelling styles have occurred across different seasons of The Simpsons?',
'How has the animation style and production technology of The Simpsons changed over time?',
'How have audience demographics, reception, and ratings of The Simpsons shifted throughout its run?']
In the design of DeepSearcher, the boundaries between researching and refining the question are blurred. The initial user query is decomposed into sub-queries, much like the previous post. See above for initial subqueries produced from the query “How has The Simpsons changed over time?”. However, the following research step will continue to refine the question as needed.
Research and Analyze
Having broken down the query into sub-queries, the research portion of the agent begins. It has, roughly speaking, four steps: routing, search, reflection, and conditional repeat.
Routing
Our database contains multiple tables or collections from different sources. It would be more efficient if we could restrict our semantic search to only those sources that are relevant to the query at hand. A query router prompts an LLM to decide from which collections information should be retrieved.
Here is the method to form the query routing prompt:
def get_vector_db_search_prompt(
question: str,
collection_names: List[str],
collection_descriptions: List[str],
context: List[str] = None,
):
sections = []
# common prompt
common_prompt = f"""You are an advanced AI problem analyst. Use your reasoning ability and historical conversation information, based on all the existing data sets, to get absolutely accurate answers to the following questions, and generate a suitable question for each data set according to the data set description that may be related to the question.
Question: {question}
"""
sections.append(common_prompt)
# data set prompt
data_set = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{collection_name}: {collection_descriptions[i]}")
data_set_prompt = f"""The following is all the data set information. The format of data set information is data set name: data set description.
Data Sets And Descriptions:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# context prompt
if context:
context_prompt = f"""The following is a condensed version of the historical conversation. This information needs to be combined in this analysis to generate questions that are closer to the answer. You must not generate the same or similar questions for the same data set, nor can you regenerate questions for data sets that have been determined to be unrelated.
Historical Conversation:
"""
sections.append(context_prompt + "\n".join(context))
# response prompt
response_prompt = f"""Based on the above, you can only select a few datasets from the following dataset list to generate appropriate related questions for the selected datasets in order to solve the above problems. The output format is json, where the key is the name of the dataset and the value is the corresponding generated question.
Data Sets:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """Respond exclusively in valid JSON format matching exact JSON schema.
Critical Requirements:
- Include ONLY ONE action type
- Never add unsupported keys
- Exclude all non-JSON text, markdown, or explanations
- Maintain strict JSON syntax"""
sections.append(footer)
return "\n\n".join(sections)
We make the LLM return structured output as JSON in order to easily convert its output to a decision on what to do next.
Search
Having selected various database collections via the previous step, the search step performs a similarity search with Milvus. Much like the previous post, the source data has been specified in advance, chunked, embedded, and stored in the vector database. For DeepSearcher, the data sources, both local and online, must be manually specified. We leave online search for future work.
Reflection
Unlike the previous post, DeepSearcher illustrates a true form of agentic reflection, inputting the prior outputs as context into a prompt that “reflects” on whether the questions asked so far and the relevant retrieved chunks contain any informational gaps. This can be seen as an analysis step.
Here is the method to create the prompt:
def get_reflect_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Determine whether additional search queries are needed based on the original query, previous sub queries, and all retrieved document chunks. If further research is required, provide a Python list of up to 3 search queries. If no further research is required, return an empty list.
If the original query is to write a report, then you prefer to generate some further queries, instead return an empty list.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
footer = """Respond exclusively in valid List of str format without any other text."""
return reflect_prompt + footer
Once more, we make the LLM return structured output, this time as Python-interpretable data.
Here is an example of new sub-queries “discovered” by reflection after answering the initial sub-queries above:
New search queries for next iteration: [
"How have changes in The Simpsons' voice cast and production team influenced the show's evolution over different seasons?",
"What role has The Simpsons' satire and social commentary played in its adaptation to contemporary issues across decades?",
'How has The Simpsons addressed and incorporated shifts in media consumption, such as streaming services, into its distribution and content strategies?']
Conditional Repeat
Unlike our previous post, DeepSearcher illustrates conditional execution flow. After reflecting on whether the questions and answers so far are complete, if there are additional questions to be asked the agent repeats the above steps. Importantly, the execution flow (a while loop) is a function of the LLM output rather than being hard-coded. In this case there is only a binary choice: repeat research or generate a report. In more complex agents there may be several such as: follow hyperlink, retrieve chunks, store in memory, reflect etc. In this way, the question continues to be refined as the agent sees fit until it decides to exit the loop and generate the report. In our Simpsons example, DeepSearcher performs two more rounds of filling the gaps with extra sub-queries.
Synthesize
Finally, the fully decomposed question and retrieved chunks are synthesized into a report with a single prompt. Here is the code to create the prompt:
def get_final_answer_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""You are an AI content analysis expert, good at summarizing content. Please summarize a specific and detailed answer or report based on the previous queries and the retrieved document chunks.
Original Query: {question}
Previous Sub Queries: {mini_questions}
Related Chunks:
{mini_chunk_str}
"""
return summary_prompt
This approach has the advantage over our prototype, which analyzed each question separately and simply concatenated the output, of producing a report where all sections are consistent with each other, i.e., containing no repeated or contradictory information. A more complex system could combine aspects of both, using a conditional execution flow to structure the report, summarize, rewrite, reflect and pivot, and so on, which we leave for future work.
Results
Here is a sample from the report generated by the query “How has The Simpsons changed over time?” with DeepSeek-R1 passing the Wikipedia page on The Simpsons as source material:
Report: The Evolution of The Simpsons (1989–Present)
1. Cultural Impact and Societal Relevance
The Simpsons debuted as a subversive critique of American middle-class life, gaining notoriety for its bold satire in the 1990s. Initially a countercultural phenomenon, it challenged norms with episodes tackling religion, politics, and consumerism. Over time, its cultural dominance waned as competitors like South Park and Family Guy pushed boundaries further. By the 2010s, the show transitioned from trendsetter to nostalgic institution, balancing legacy appeal with attempts to address modern issues like climate change and LGBTQ+ rights, albeit with less societal resonance.
…
Conclusion
The Simpsons evolved from a radical satire to a television institution, navigating shifts in technology, politics, and audience expectations. While its golden-age brilliance remains unmatched, its adaptability—through streaming, updated humor, and global outreach—secures its place as a cultural touchstone. The show’s longevity reflects both nostalgia and a pragmatic embrace of change, even as it grapples with the challenges of relevance in a fragmented media landscape.
Find the full report here, and a report produced by DeepSearcher with GPT-4o mini for comparison.
Discussion
We presented DeepSearcher, an agent for performing research and writing reports. Our system is built upon the idea in our previous article, adding features like conditional execution flow, query routing, and an improved interface. We switched from local inference with a small 4-bit quantized reasoning model to an online inference service for the massive DeepSeek-R1 model, qualitatively improving our output report. DeepSearcher works with most inference services like OpenAI, Gemini, DeepSeek and Grok 3 (coming soon!).
Reasoning models, especially as used in research agents, are inference-heavy, and we were fortunate to be able to use the fastest offering of DeepSeek-R1 from SambaNova running on their custom hardware. For our demonstration query, we made sixty-five calls to SambaNova’s DeepSeek-R1 inference service, inputting around 25k tokens, outputting 22k tokens, and costing $0.30. We were impressed with the speed of inference given that the model contains 671-billion parameters and is 3/4 of a terabyte large. Find out more details here!
We will continue to iterate on this work in future posts, examining additional agentic concepts and the design space of research agents. In the meanwhile, we invite everyone to try out DeepSearcher, star us on GitHub, and share your feedback!
Resources
Background reading: “I Built a Deep Research with Open Source—and So Can You!”
“SambaNova Launches the Fastest DeepSeek-R1 671B with the Highest Efficiency”
DeepSearcher: DeepSeek-R1 report on The Simpsons
DeepSearcher: GPT-4o mini report on The Simpsons
- DeepSearcher Architecture
- Define and Refine the Question
- Research and Analyze
- Synthesize
- Results
- Discussion
- Resources
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



