Raft or not? The Best Solution to Data Consistency in Cloud-native Databases
 Cover image
Cover image
This article was written by Xiaofan Luan and transcreated by Angela Ni.
Consensus-based replication is a widely-adopted strategy in many cloud-native, distributed databases. However, it has certain shortcomings and is definitely not the silver bullet.
This post aims to explain the concepts of replication, consistency, and consensus in a cloud-native and distributed database, then clarify why consensus-based algorithms like Paxos and Raft are not the silver bullet, and finally propose a solution to consensus-based replication.
Jump to:
- Understanding replication, consistency, and consensus
- Consensus-based replication
- A log replication strategy for cloud-native and distributed database
- Summary
Understanding replication, consistency, and consensus
Before going deep into the pros and cons of Paxos and Raft, and proposing a best suited log replication strategy, we need to first demystify concepts of replication, consistency, and consensus.
Note that this article mainly focuses on the synchronization of incremental data/log. Therefore, when talking about data/log replication, only replicating incremental data, not historical data, is referred to.
Replication
Replication is the process of making multiple copies of data and storing them in different disks, processes, machines, clusters, etc, for the purpose of increasing data reliability and accelerating data queries. Since in replication, data are copied and stored at multiple locations, data are more reliable in the face of recovering from disk failures, physical machine failures, or cluster errors. In addition, multiple replicas of data can boost the performance of a distributed database by greatly speeding up queries.
There are various modes of replication, such as synchronous/asynchronous replication, replication with strong/eventual consistency, leader-follower/decentralized replication. The choice of replication mode has an effect on system availability and consistency. Therefore, as proposed in the famous CAP theorem, a system architect needs to trade off between consistency and availability when network partition is inevitable.
Consistency
In short, consistency in a distributed database refers to the property that ensures every node or replica has the same view of data when writing or reading data at a given time. For a full list of consistency levels, read the doc here.
To clarify, here we are talking about consistency as in the CAP theorem, not ACID (atomicity, consistency, isolation, durability). Consistency in CAP theorem refers to each node in the system having the same data while consistency in ACID refers to a single node enforcing the same rules on every potential commit.
Generally, OLTP (online transaction processing) databases require strong consistency or linearizability to ensure that:
- Each read can access the latest inserted data.
- If a new value is returned after a read, all following reads, regardless on the same or different clients, must return the new value.
The essence of linearizability is to guarantee the recency of multiple data replicas - once a new value is written or read, all subsequent reads can view the new value until the value is later overwritten. A distributed system providing linearizability can save users the trouble of keeping an eye on multiple replicas, and can guarantee the atomicity and order or each operation.
Consensus
The concept of consensus is introduced to distributed systems as users are eager to see distributed systems work in the same way as standalone systems.
To put it simple, consensus is a general agreement on value. For instance, Steve and Frank wanted to grab something to eat. Steve suggested having sandwiches. Frank agreed to Steve’s suggestion and both of them are had sandwiches. They reached a consensus. More specifically, a value (sandwiches) proposed by one of them is agreed upon by both, and both of them take actions based on the value. Similarly, consensus in a distributed system means when a process propose a value, all the rest processes in the system agree on and act upon this value.
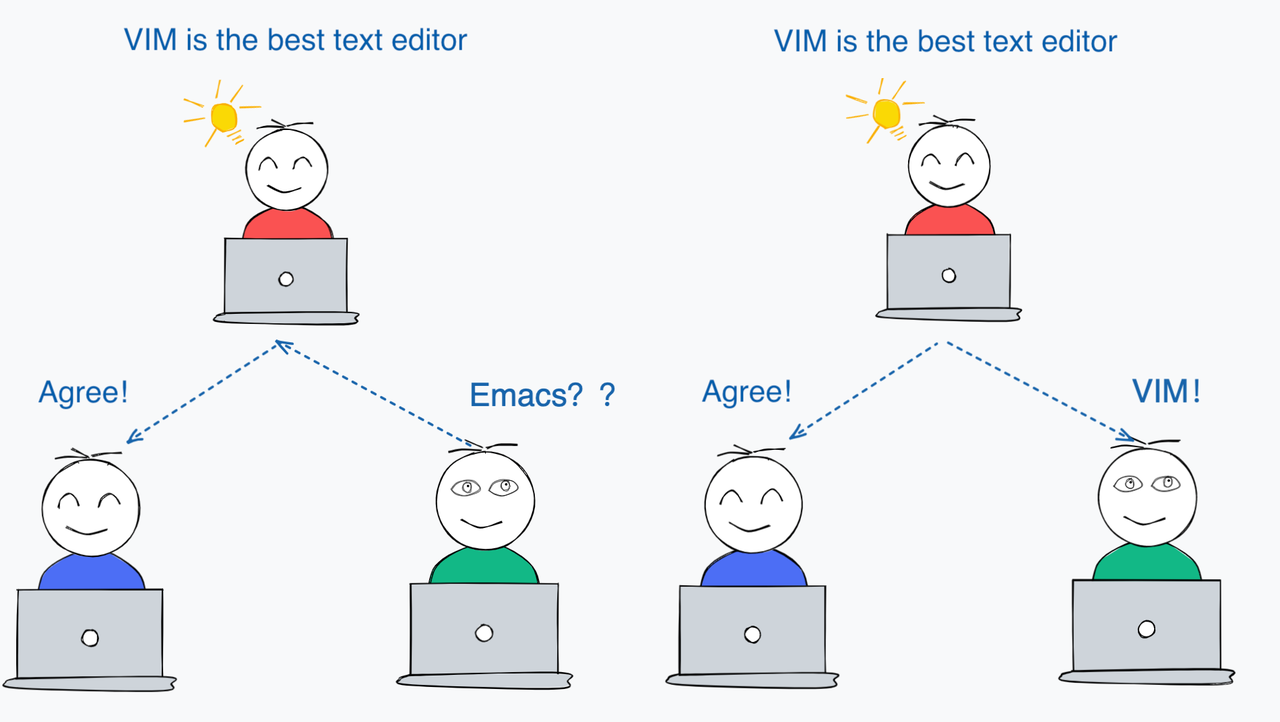 Consensus
Consensus
Consensus-based replication
The earliest consensus-based algorithms were proposed along with viewstamped replication in 1988. In 1989, Leslie Lamport proposed Paxos, a consensus-based algorithm.
In recent years, we witness another prevalent consensus-based algorithm in the industry - Raft. It has been adopted by many mainstream NewSQL databases like CockroachDB, TiDB, OceanBase, etc.
Notably, a distributed system does not necessarily support linearizability even if it adopts consensus-based replication. However, linearizability is the prerequisite for building ACID distributed database.
When designing a database system, the commit order of logs and state machines should be taken into consideration. Extra caution is also needed to maintain the leader lease of Paxos or Raft and prevent a split-brain under network partition.
 Raft replication state machine
Raft replication state machine
Pros and cons
Indeed, Raft, ZAB, and quorum-based log protocol in Aurora are all Paxos variations. Consensus-based replication has the following advantages:
- Though consensus-based replication focus more on consistency and network partition in the CAP theorem, it provides relatively better availability compared to traditional leader-follower replication.
- Raft is a breakthrough that greatly simplified consensus-based algorithms. And there are many open-source Raft libraries on GitHub (Eg. sofa-jraft).
- The performance of consensus-based replication can satisfy most of the applications and businesses. With the coverage of high-performance SSD and gigabyte NICs (network interface card), the burden of synchronizing multiple replicas is relieved, making Paxos and Raft algorithms the mainstream in the industry.
One misconception is that consensus-based replication is the silver bullet to achieving data consistency in a distributed database. However, this is not the truth. The challenges in availability, complexity, and performance faced by consensus-based algorithm blocks it from being the perfect solution.
Compromised availability Optimized Paxos or Raft algorithm has strong dependency on the leader replica, which comes with a weak ability to fight against grey failure. In consensus-based replication, a new election of leader replica will not take place until the leader node does not respond for a long time. Therefore, consensus-based replication is incapable of handling situations where the leader node is slow or a thrashing occurs.
High complexity Though there are already many extended algorithms based on Paxos and Raft, the emergence of Multi-Raft and Parallel Raft requires more considerations and tests on synchronization between logs and state machines.
Compromised performance In a cloud-native era, local storage is replaced by shared storage solutions like EBS and S3 to ensure data reliability and consistency. As a result, consensus-based replication is no longer a must for distributed systems. What’s more, consensus-based replication comes with the problem of data redundancy as both the solution and EBS has multiple replicas.
For multi-datacenter and multi-cloud replication, the pursuit for consistency compromises not only availability but also latency, resulting in a decline in performance. Therefore, linearizability is not a must for multi-datacenter disaster tolerance in most of the applications.
A log replication strategy for cloud-native and distributed database
Undeniably, consensus-based algorithms like Raft and Paxos are still the mainstream algorithms adopted by many OLTP databases. However, by observing the examples of PacificA protocol, Socrates and Rockset, we can see the trend is shifting.
There are two major principles for a solution that can best serve a cloud-native, distributed database.
1. Replication as a service
A separate microservice dedicated to data synchronization is needed. The synchronization module and storage module should no longer be tightly coupled within the same process.
For instance, Socrates decouples storage, log, and computing. There is one dedicated log service (XLog service in the middle of the figure below).
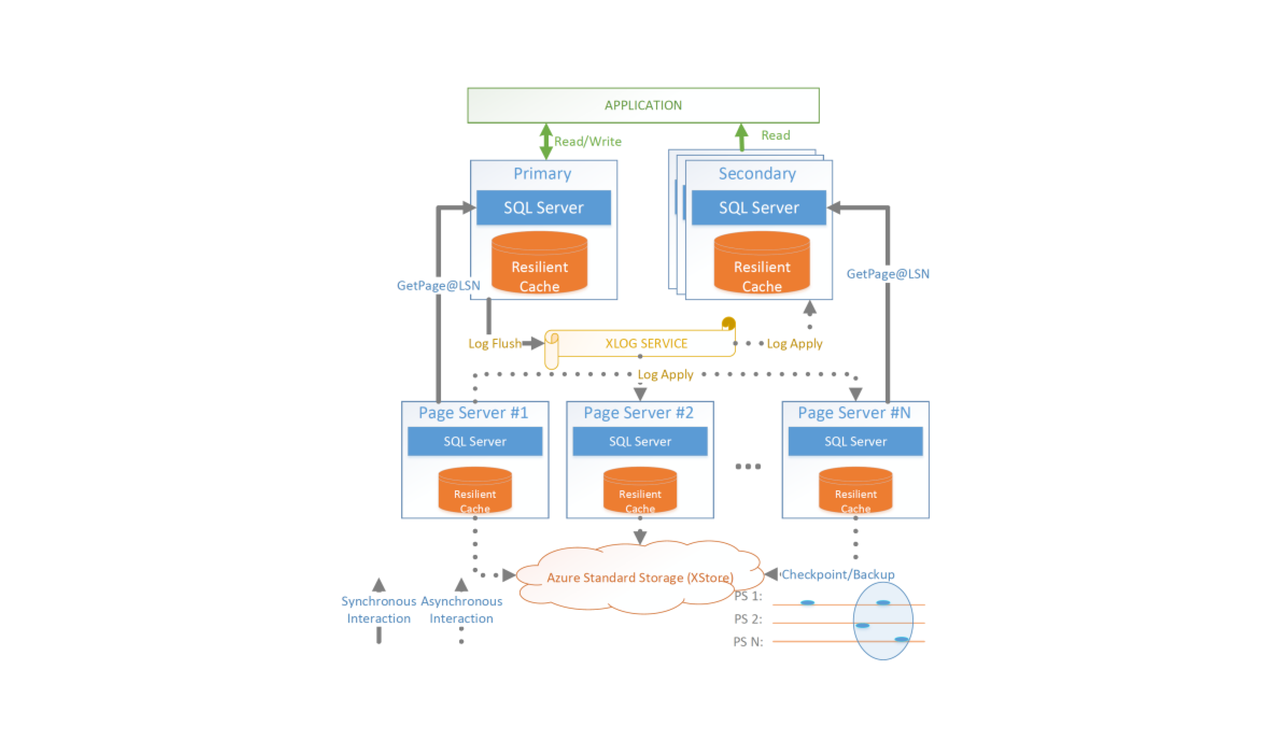 Socrates architecture
Socrates architecture
XLog service is an individual service. Data persistence is achieved with the help of low-latency storage. The landing zone in Socrates is in charge of keeping three replicas at an accelerated speed.
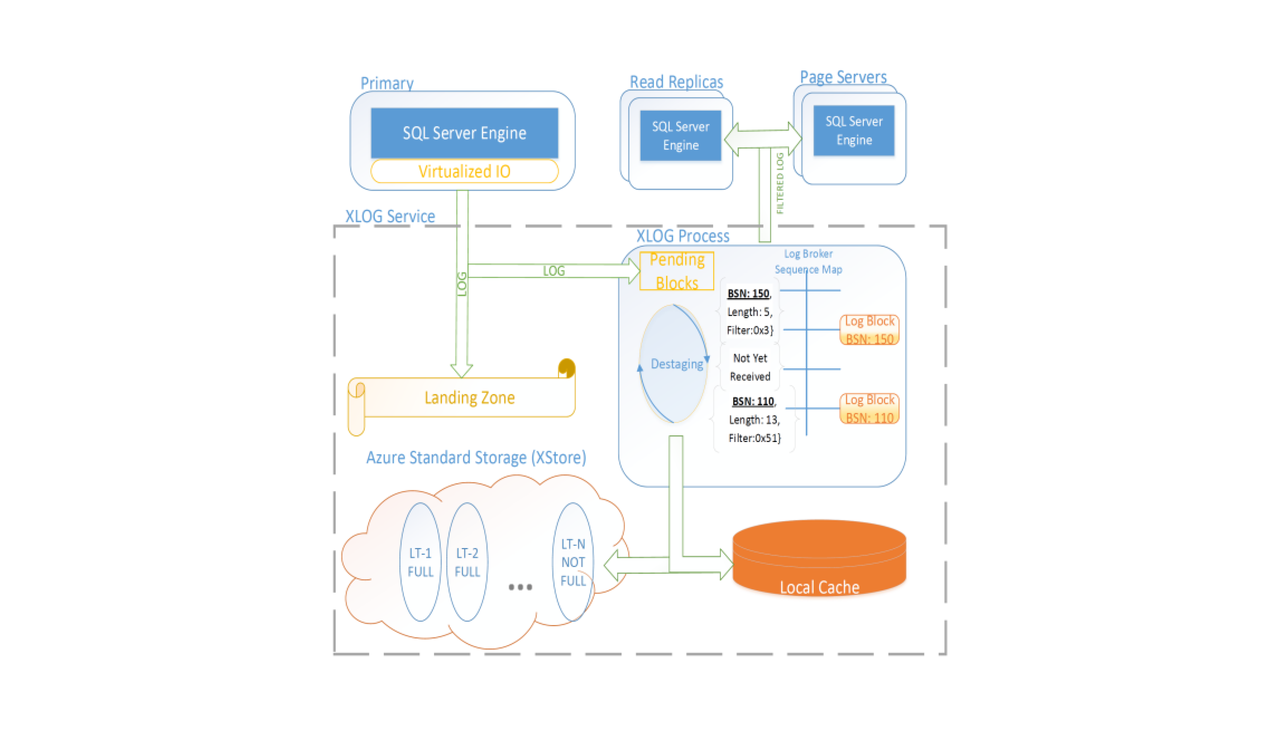 Socrates XLog service
Socrates XLog service
The leader node distributes logs to log broker asynchronously, and flushes data to Xstore. Local SSD cache can accelerate data read. Once data flush is successful, buffers in the landing zone can be cleaned. Obviously, all log data are divided into three layers - landing zone, local SSD, and XStore.
2. Russian doll principle
One way to design a system is to follow the Russian doll principle: each layer is complete and perfectly suited to what the layer does so that other layers may be built on-top or around it.
When designing a cloud-native database, we need to cleverly leverage other third-party services to reduce the complexity of system architecture.
It seems like we cannot get around with Paxos to avoid single point failure. However, we can still greatly simplify log replication by handing leader election over to Raft or Paxos services based on Chubby, Zk, and etcd.
For instance, Rockset architecture follows the Russian doll principle and uses Kafka/Kineses for distributed logs, S3 for storage, and local SSD cache for improving query performance.
 Rockset architecture
Rockset architecture
The Milvus approach
Tunable consistency in Milvus is in fact similar to follower reads in consensus-based replication. Follower read feature refers to using follower replica to undertake data read tasks under the premise of strong consistency. The purpose is to enhance cluster throughput and reduce the load on leader. The mechanism behind follower read feature is inquiring the commit index of the latest log and providing query service until all data in the commit index are applied to state machines.
However, the design of Milvus did not adopt the follower strategy. In other words, Milvus does not inquire commit index every time it receives a query request. Instead, Milvus adopts a mechanism like the watermark in Flink, which notifies query node the location of commit index at a regular interval. The reason for such a mechanism is that Milvus users usually do not have high demand for data consistency, and they can accept a compromise in data visibility for better system performance.
In addition, Milvus also adopts multiple microservices and separates storage from computing. In the Milvus architecture, S3, MinIo, and Azure Blob are used for storage.
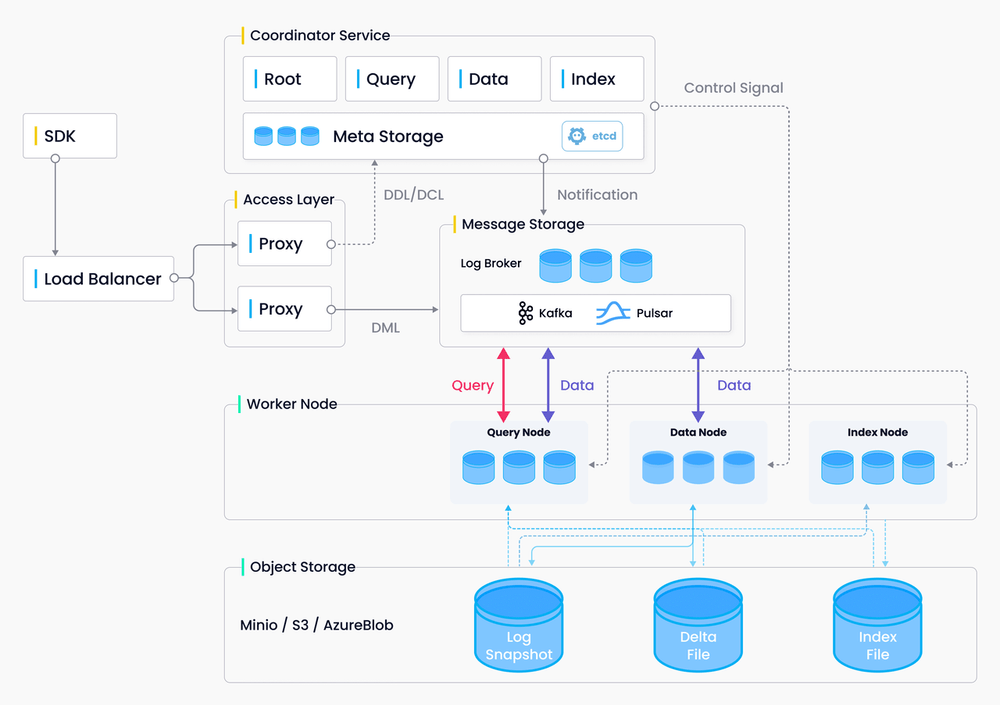 Milvus architecture
Milvus architecture
Summary
Nowadays, an increasing number of cloud-native databases are making log replication an individual service. By doing so, the cost of adding read-only replicas and heterogeneous replication can be reduced. Using multiple microservices enables quick utilization of mature cloud-based infrastructure, which is impossible for traditional databases. An individual log service can rely on consensus-based replication, but it can also follow the Russian doll strategy to adopt various consistency protocols together with Paxos or Raft to achieve linearizability.
References
- Lamport L. Paxos made simple[J]. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001), 2001: 51-58.
- Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//2014 USENIX Annual Technical Conference (Usenix ATC 14). 2014: 305-319.
- Oki B M, Liskov B H. Viewstamped replication: A new primary copy method to support highly-available distributed systems[C]//Proceedings of the seventh annual ACM Symposium on Principles of distributed computing. 1988: 8-17.
- Lin W, Yang M, Zhang L, et al. PacificA: Replication in log-based distributed storage systems[J]. 2008.
- Verbitski A, Gupta A, Saha D, et al. Amazon aurora: On avoiding distributed consensus for i/os, commits, and membership changes[C]//Proceedings of the 2018 International Conference on Management of Data. 2018: 789-796.
- Antonopoulos P, Budovski A, Diaconu C, et al. Socrates: The new sql server in the cloud[C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1743-1756.
- Understanding replication, consistency, and consensus
- Replication
- Consistency
- Consensus
- Consensus-based replication
- Pros and cons
- A log replication strategy for cloud-native and distributed database
- 1. Replication as a service
- 2. Russian doll principle
- The Milvus approach
- Summary
- References
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



