LLM Context Pruning: A Developer’s Guide to Better RAG and Agentic AI Results
Context windows in LLMs have gotten huge lately. Some models can take a million tokens or more in a single pass, and every new release seems to push that number higher. It’s exciting, but if you’ve actually built anything that uses long context, you know there’s a gap between what’s possible and what’s useful.
Just because a model can read an entire book in one prompt doesn’t mean you should give it one. Most long inputs are full of stuff the model doesn’t need. Once you start dumping hundreds of thousands of tokens into a prompt, you usually get slower responses, higher compute bills, and sometimes lower-quality answers because the model is trying to pay attention to everything at once.
So even though context windows keep getting bigger, the real question becomes: what should we actually put in there? That’s where Context Pruning comes in. It’s basically the process of trimming away the parts of your retrieved or assembled context that don’t help the model answer the question. Done right, it keeps your system fast, stable, and a lot more predictable.
In this article, we’ll talk about why long context often behaves differently than you’d expect, how pruning helps keep things under control, and how pruning tools like Provence fit into real RAG pipelines without making your setup more complicated.
Four Common Failure Modes in Long-Context Systems
A bigger context window doesn’t magically make the model smarter. If anything, once you start stuffing a ton of information into the prompt, you unlock a whole new set of ways things can go wrong. Here are four issues you’ll see all the time when building long-context or RAG systems.
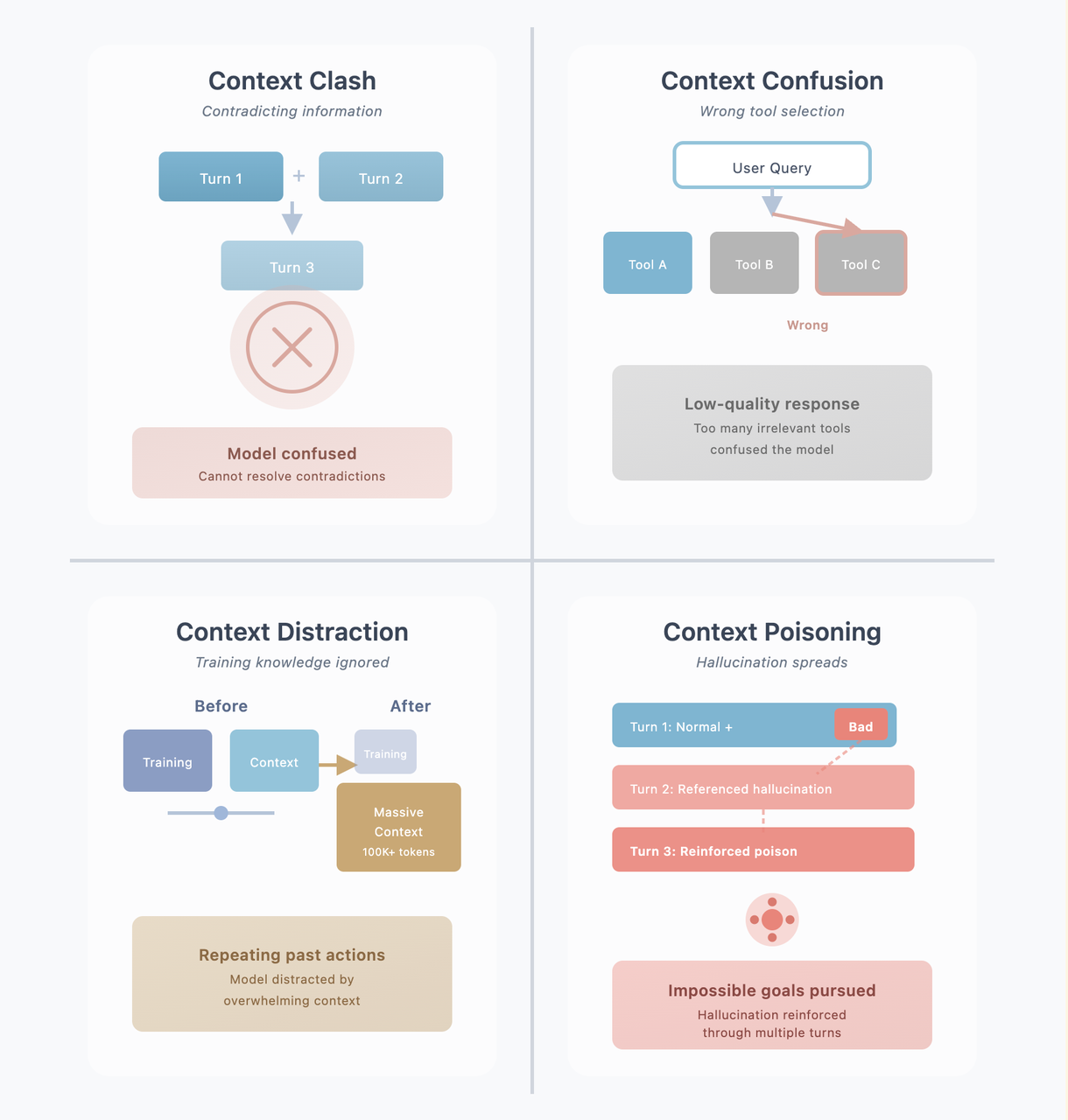
1. Context Clash
Context Clash occurs when information accumulated across multiple turns becomes internally contradictory.
For example, a user might say “I like apples” early in a conversation and later state “I don’t like fruit.” When both statements remain in the context, the model has no reliable way to resolve the conflict, leading to inconsistent or hesitant responses.
2. Context Confusion
Context Confusion arises when the context contains large amounts of irrelevant or weakly related information, making it difficult for the model to select the correct action or tool.
This issue is especially visible in tool-augmented systems. When the context is cluttered with unrelated details, the model may misinterpret user intent and select the wrong tool or action—not because the correct option is missing, but because the signal is buried under noise.
3. Context Distraction
Context Distraction happens when excessive contextual information dominates the model’s attention, reducing its reliance on pretrained knowledge and general reasoning.
Instead of relying on broadly learned patterns, the model overweights recent details in the context, even when they are incomplete or unreliable. This can lead to shallow or brittle reasoning that mirrors the context too closely rather than applying higher-level understanding.
4. Context Poisoning
Context Poisoning occurs when incorrect information enters the context and is repeatedly referenced and reinforced over multiple turns.
A single false statement introduced early in the conversation can become the basis for subsequent reasoning. As the dialogue continues, the model builds on this flawed assumption, compounding the error and drifting further from the correct answer.
What Is Context Pruning and Why It Matters
Once you start dealing with long contexts, you quickly realize you need more than one trick to keep things under control. In real systems, teams usually combine a bunch of tactics—RAG, tool loadout, summarization, quarantining certain messages, offloading old history, and so on. They all help in different ways. But Context Pruning is the one that directly decides what actually gets fed to the model.
Context Pruning, in simple terms, is the process of automatically removing irrelevant, low-value, or conflicting information before it enters the model’s context window. It’s basically a filter that keeps only the text pieces most likely to matter for the current task.
Other strategies might reorganize the context, compress it, or push some parts aside for later. Pruning is more direct: it answers the question, “Should this piece of information go into the prompt at all?”
That’s why pruning ends up being especially important in RAG systems. Vector search is great, but it isn’t perfect. It often returns a big grab bag of candidates—some useful, some loosely related, some completely off-base. If you just dump all of them into the prompt, you’ll hit the failure modes we covered earlier. Pruning sits between retrieval and the model, acting as a gatekeeper that decides which chunks to keep.
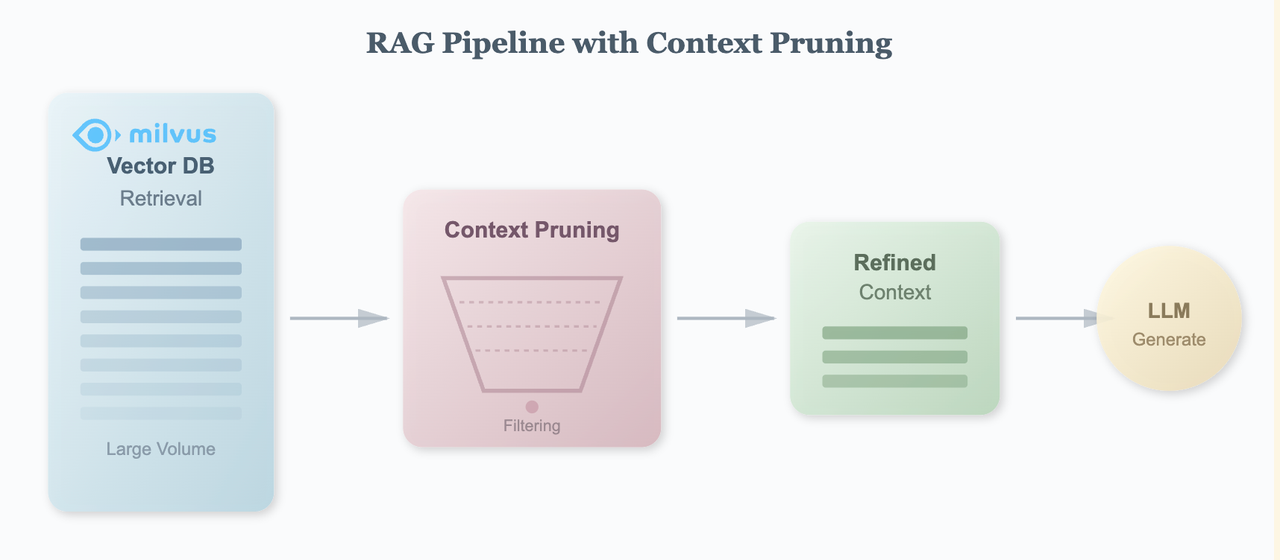
When pruning works well, the benefits show up immediately: cleaner context, more consistent answers, lower token usage, and fewer weird side effects from irrelevant text sneaking in. Even if you don’t change anything about your retrieval setup, adding a solid pruning step can noticeably improve overall system performance.
In practice, pruning is one of the highest-leverage optimizations in a long-context or RAG pipeline—simple idea, big impact.
Provence: A Practical Context Pruning Model
While exploring approaches to context pruning, I came across two compelling open-source models developed at Naver Labs Europe: Provence and its multilingual variant, XProvence.

Provence is a method for training a lightweight context pruning model for retrieval-augmented generation, with a particular focus on question answering. Given a user question and a retrieved passage, it identifies and removes irrelevant sentences, keeping only information that contributes to the final answer.
By pruning low-value content before generation, Provence reduces noise in the model’s input, shortens prompts, and lowers LLM inference latency. It is also plug-and-play, working with any LLM or retrieval system without requiring tight integration or architectural changes.
Provence offers several practical features for real-world RAG pipelines.
1. Document-Level Understanding
Provence reasons about documents as a whole, rather than scoring sentences in isolation. This matters because real-world documents frequently contain references such as “it,” “this,” or “the method above.” In isolation, these sentences can be ambiguous or even meaningless. When viewed in context, their relevance becomes clear. By modeling the document holistically, Provence produces more accurate and coherent pruning decisions.
2. Adaptive Sentence Selection
Provence automatically determines how many sentences to keep from a retrieved document. Instead of relying on fixed rules like “keep the top five sentences,” it adapts to the query and the content.
Some questions can be answered with a single sentence, while others require multiple supporting statements. Provence handles this variation dynamically, using a relevance threshold that works well across domains and can be adjusted when needed—without manual tuning in most cases.
3. High Efficiency with Integrated Reranking
Provence is designed to be efficient. It is a compact, lightweight model, making it significantly faster and cheaper to run than LLM-based pruning approaches.
More importantly, Provence can combine reranking and context pruning into a single step. Since reranking is already a standard stage in modern RAG pipelines, integrating pruning at this point makes the additional cost of context pruning close to zero, while still improving the quality of the context passed to the language model.
4. Multilingual Support via XProvence
Provence also has a variant called XProvence, which uses the same architecture but is trained on multilingual data. This enables it to evaluate queries and documents across languages—such as Chinese, English, and Korean—making it suitable for multilingual and cross-lingual RAG systems.
How Provence Is Trained
Provence uses a clean and effective training design based on a cross-encoder architecture. During training, the query and each retrieved passage are concatenated into a single input and encoded together. This allows the model to observe the full context of both the question and the passage at once and reason directly about their relevance.

This joint encoding enables Provence to learn from fine-grained relevance signals. The model is fine-tuned on DeBERTa as a lightweight encoder and optimized to perform two tasks simultaneously:
Document-level relevance scoring (rerank score): The model predicts a relevance score for the entire document, indicating how well it matches the query. For example, a score of 0.8 represents strong relevance.
Token-level relevance labeling (binary mask): In parallel, the model assigns a binary label to each token, marking whether it is relevant (
1) or irrelevant (0) to the query.
As a result, the trained model can assess a document’s overall relevance and identify which parts should be kept or removed.
At inference time, Provence predicts relevance labels at the token level. These predictions are then aggregated at the sentence level: a sentence is retained if it contains more relevant tokens than irrelevant ones; otherwise, it is pruned. Since the model is trained with sentence-level supervision, token predictions within the same sentence tend to be consistent, making this aggregation strategy reliable in practice. The pruning behavior can also be tuned by adjusting the aggregation threshold to achieve more conservative or more aggressive pruning.
Crucially, Provence reuses the reranking step that most RAG pipelines already include. This means context pruning can be added with little to no additional overhead, making Provence especially practical for real-world RAG systems.
Evaluating Context Pruning Performance Across Models
So far, we’ve focused on Provence’s design and training. The next step is to evaluate how it performs in practice: how well it prunes context, how it compares with other approaches, and how it behaves under real-world conditions.
To answer these questions, we designed a set of quantitative experiments to compare the quality of context pruning across multiple models in realistic evaluation settings.
The experiments focus on two primary goals:
Pruning effectiveness: We measure how accurately each model retains relevant content while removing irrelevant information, using standard metrics such as Precision, Recall, and F1 score.
Out-of-domain generalization: We evaluate how well each model performs on data distributions that differ from its training data, assessing robustness in out-of-domain scenarios.
Models Compared
OpenSearch Semantic Highlighter (A pruning model based on a BERT architecture, designed specifically for semantic highlighting tasks)
Dataset
We use WikiText-2 as the evaluation dataset. WikiText-2 is derived from Wikipedia articles and contains diverse document structures, where relevant information is often spread across multiple sentences and semantic relationships can be non-trivial.
Importantly, WikiText-2 differs substantially from the data typically used to train context pruning models, while still resembling real-world, knowledge-heavy content. This makes it well suited for out-of-domain evaluation, which is a key focus of our experiments.
Query Generation and Annotation
To construct an out-of-domain pruning task, we automatically generate question–answer pairs from the raw WikiText-2 corpus using GPT-4o-mini. Each evaluation sample consists of three components:
Query: A natural language question generated from the document.
Context: The complete, unmodified document.
Ground Truth: Sentence-level annotations indicating which sentences contain the answer (to be retained) and which are irrelevant (to be pruned).
This setup naturally defines a context pruning task: given a query and a full document, the model must identify the sentences that actually matter. Sentences that contain the answer are labeled as relevant and should be retained, while all other sentences are treated as irrelevant and should be pruned. This formulation allows pruning quality to be measured quantitatively using Precision, Recall, and F1 score.
Crucially, the generated questions do not appear in the training data of any evaluated model. As a result, performance reflects true generalization rather than memorization. In total, we generate 300 samples, spanning simple fact-based questions, multi-hop reasoning tasks, and more complex analytical prompts, in order to better reflect real-world usage patterns.
Evaluation Pipeline
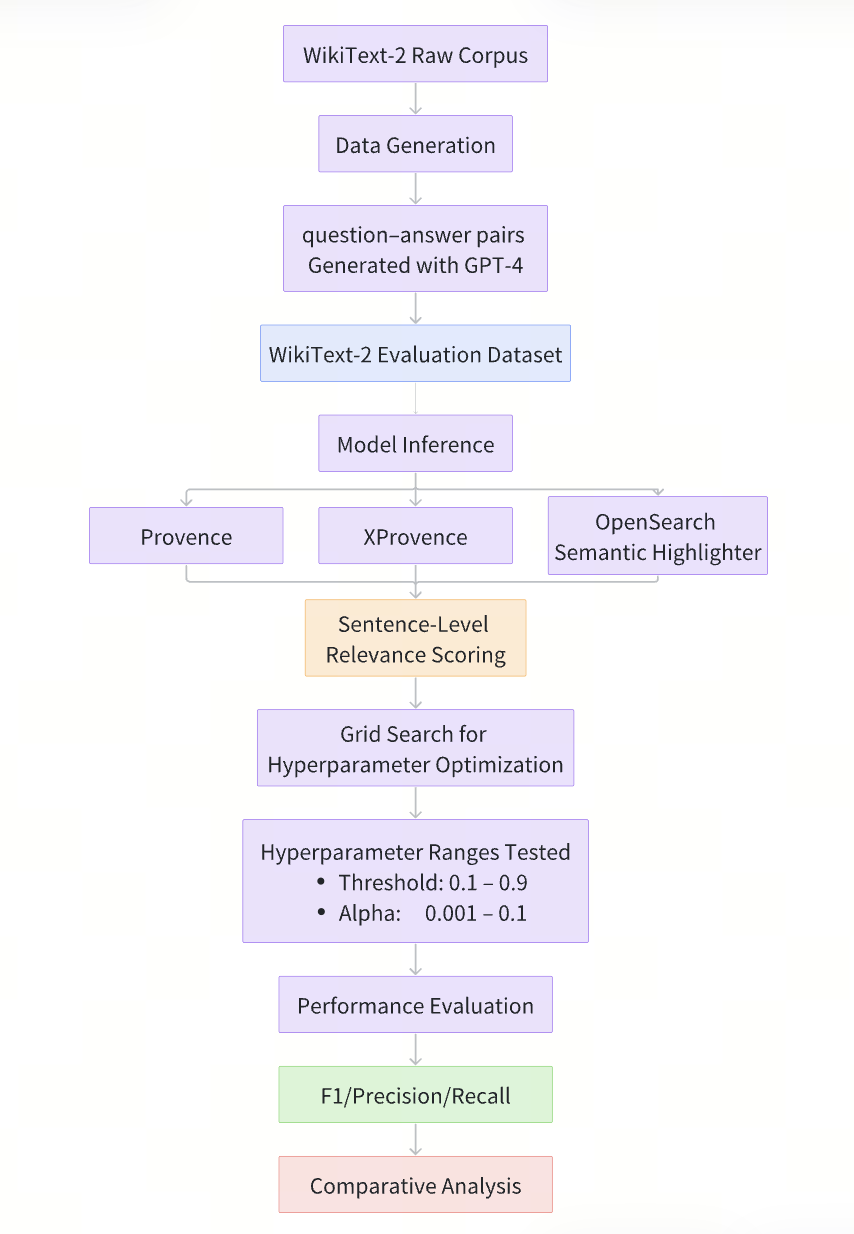
Hyperparameter Optimization: For each model, we perform grid search over a predefined hyperparameter space and select the configuration that maximizes the F1 score.
Results and Analysis
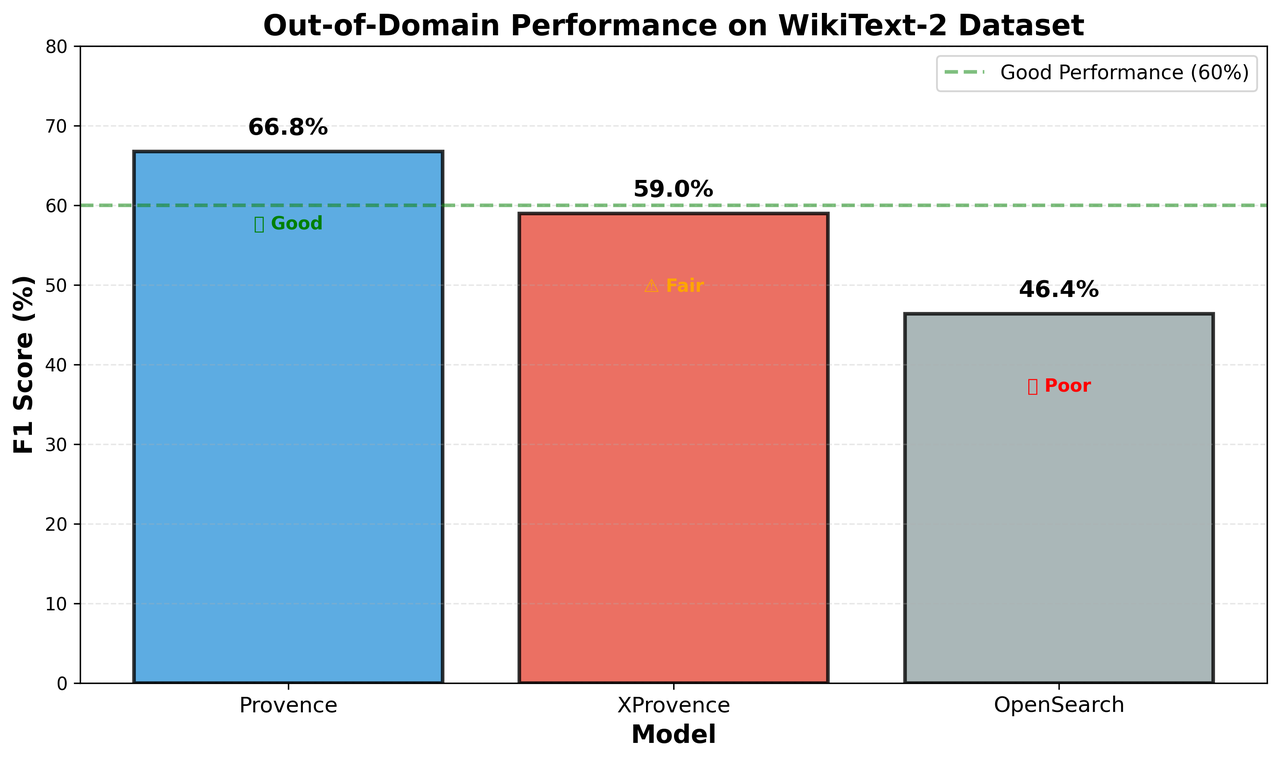
The results reveal clear performance differences across the three models.
Provence achieves the strongest overall performance, with an F1 score of 66.76%. Its Precision (69.53%) and Recall (64.19%) are well balanced, indicating robust out-of-domain generalization. The optimal configuration uses a pruning threshold of 0.6 and α = 0.051, suggesting that the model’s relevance scores are well calibrated and that the pruning behavior is intuitive and easy to tune in practice.
XProvence reaches an F1 score of 58.97%, characterized by high recall (75.52%) and lower precision (48.37%). This reflects a more conservative pruning strategy that prioritizes retaining potentially relevant information over aggressively removing noise. Such behavior can be desirable in domains where false negatives are costly—such as healthcare or legal applications—but it also increases false positives, which lowers precision. Despite this trade-off, XProvence’s multilingual capability makes it a strong option for non-English or cross-lingual settings.
In contrast, OpenSearch Semantic Highlighter performs substantially worse, with an F1 score of 46.37% (Precision 62.35%, Recall 36.98%). The gap relative to Provence and XProvence points to limitations in both score calibration and out-of-domain generalization, especially under out-of-domain conditions.
Semantic Highlighting: Another Way to Find What Actually Matters in Text
Now that we’ve talked about context pruning, it’s worth looking at a related piece of the puzzle: semantic highlighting. Technically, both features are doing almost the same underlying job—they score pieces of text based on how relevant they are to a query. The difference is how the result is used in the pipeline.
Most people hear “highlighting” and think of the classic keyword highlighters you see in Elasticsearch or Solr. These tools basically look for literal keyword matches and wrap them in something like <em>. They’re cheap and predictable, but they only work when the text uses the exact same words as the query. If the document paraphrases, uses synonyms, or phrases the idea differently, traditional highlighters miss it completely.
Semantic highlighting takes a different route. Instead of checking for exact string matches, it uses a model to estimate semantic similarity between the query and different text spans. This lets it highlight relevant content even when the wording is totally different. For RAG pipelines, agent workflows, or any AI search system where meaning matters more than tokens, semantic highlighting gives you a far clearer picture of why a document was retrieved.
The problem is that most existing semantic highlighting solutions aren’t built for production AI workloads. We tested everything available, and none of them delivered the level of precision, latency, or multilingual reliability we needed for real RAG and agent systems. So we ended up training and open-sourcing our own model instead: zilliz/semantic-highlight-bilingual-v1
At a high level, context pruning and semantic highlighting solve the same core task: given a query and a chunk of text, figure out which parts actually matter. The only difference is what happens next.
Context pruning drops the irrelevant parts before generation.
Semantic highlighting keeps the full text but visually surfaces the important spans.
Because the underlying operation is so similar, the same model can often power both features. That makes it easier to reuse components across the stack and keeps your RAG system simpler and more efficient overall.
Semantic Highlighting in Milvus and Zilliz Cloud
Semantic highlighting is now fully supported in Milvus and Zilliz Cloud (the fully managed service of Milvus), and it’s already proving useful for anyone working with RAG or AI-driven search. The feature solves a very simple but painful problem: when vector search returns a ton of chunks, how do you quickly figure out which sentences inside those chunks actually matter?
Without highlighting, users end up reading entire documents just to understand why something was retrieved. With semantic highlighting built in, Milvus and Zilliz Cloud automatically marks the specific spans that are semantically related to your query — even if the wording is different. No more hunting for keyword matches or guessing why a chunk showed up.
This makes retrieval far more transparent. Instead of just returning “relevant documents,” Milvus shows where the relevance lives. For RAG pipelines, this is especially helpful because you can instantly see what the model is supposed to attend to, making debugging and prompt construction much easier.
We built this support directly into Milvus and Zilliz Cloud, so you don’t have to bolt on external models or run another service just to get usable attribution. Everything runs inside the retrieval path: vector search → relevance scoring → highlighted spans. It works out of the box at scale and supports multilingual workloads with our zilliz/semantic-highlight-bilingual-v1 model.
Looking Ahead
Context engineering is still pretty new, and there’s plenty left to figure out. Even with pruning and semantic highlighting working well inside Milvus and Zilliz Cloud, we’re nowhere near the end of the story. There are a bunch of areas that still need real engineering work — making pruning models more accurate without slowing things down, getting better at handling weird or out-of-domain queries, and wiring all the pieces together so retrieval → rerank → prune → highlight feels like one clean pipeline instead of a set of hacks glued together.
As context windows keep growing, these decisions only get more important. Good context management isn’t a “nice bonus” anymore; it’s becoming a core part of making long-context and RAG systems behave reliably.
We’re going to keep experimenting, benchmarking, and shipping the pieces that actually make a difference for developers. The goal is straightforward: make it easier to build systems that don’t break under messy data, unpredictable queries, or large-scale workloads.
If you want to talk through any of this — or just need help debugging something — you can hop into our Discord channel or book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
Always happy to chat and trade notes with other builders.
- Four Common Failure Modes in Long-Context Systems
- 1. Context Clash
- 2. Context Confusion
- 3. Context Distraction
- 4. Context Poisoning
- What Is Context Pruning and Why It Matters
- Provence: A Practical Context Pruning Model
- How Provence Is Trained
- Evaluating Context Pruning Performance Across Models
- Models Compared
- Dataset
- Query Generation and Annotation
- Evaluation Pipeline
- Results and Analysis
- Semantic Highlighting: Another Way to Find What Actually Matters in Text
- Semantic Highlighting in Milvus and Zilliz Cloud
- Looking Ahead
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



