性能常见问题
如何为 IVF 索引设置nlist 和nprobe ?
设置nlist 需要根据具体情况而定。根据经验,nlist 的推荐值是4 × sqrt(n) ,其中n 是段中实体的总数。
每个段的大小由datacoord.segment.maxSize 参数决定,默认设置为 512 MB。将datacoord.segment.maxSize 除以每个实体的大小,即可估算出数据段 n 中实体的总数。
nprobe 的设置取决于数据集和场景,需要在准确性和查询性能之间进行权衡。我们建议通过反复试验找到理想值。
下图是在 sift50m 数据集和 IVF_SQ8 索引上运行的测试结果,其中比较了不同nlist/nprobe 对的召回率和查询性能。
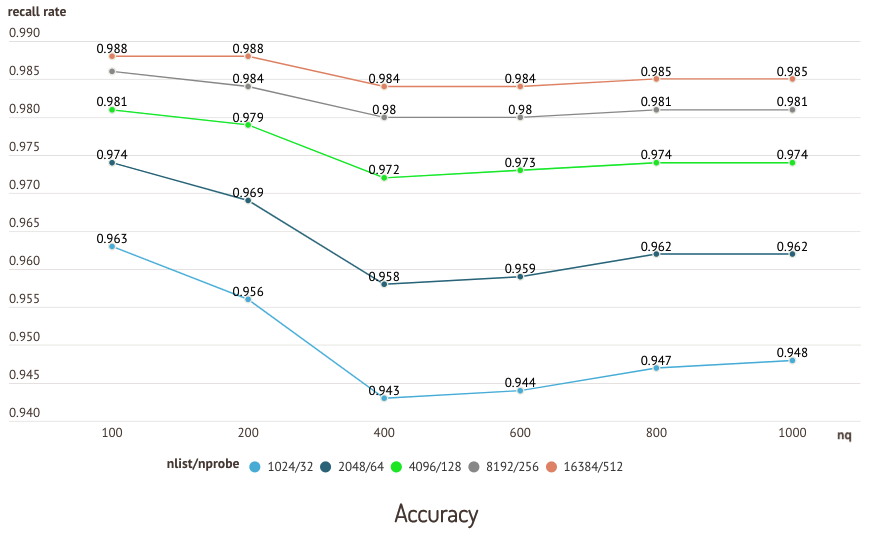 准确性测试
准确性测试 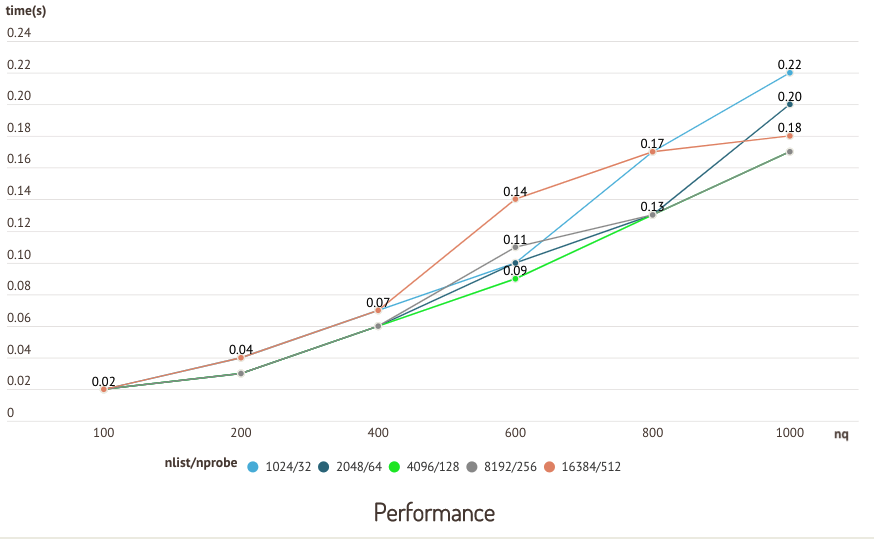 性能测试
性能测试
为什么在较小的数据集上查询有时需要更长的时间?
查询操作是在分段上进行的。索引可减少查询数据段所需的时间。如果一个数据段没有索引,Milvus 就会对原始数据进行暴力搜索,从而大大增加查询时间。
因此,在小数据集(Collection)上查询通常需要更长的时间,因为它没有建立索引。这是因为数据段的大小还没有达到rootCoord.minSegmentSizeToEnableindex 设置的建立索引阈值。调用create_index() 可强制 Milvus 对已达到阈值但尚未自动建立索引的数据段建立索引,从而显著提高查询性能。
哪些因素会影响 CPU 占用率?
当 Milvus 正在建立索引或运行查询时,CPU 使用率会增加。一般来说,除了使用 Annoy(在单线程上运行)外,索引构建都是 CPU 密集型工作。
运行查询时,CPU 使用率受nq 和nprobe 的影响。当nq 和nprobe 较小时,并发量较低,CPU 占用率也较低。
同时插入数据和搜索会影响查询性能吗?
插入操作不占用 CPU。但是,由于新的数据段可能还没有达到建立索引的阈值,Milvus 会采用暴力搜索,这将严重影响查询性能。
rootcoord.minSegmentSizeToEnableIndex 参数决定了段的索引建立阈值,默认设置为 1024 行。更多信息请参阅系统配置。
为 VARCHAR 字段建立索引能否提高删除速度?
为 VARCHAR 字段建立索引可以加快 "按表达式删除 "操作的速度,但仅限于特定条件下:
- 反转索引:该索引有助于非主键 VARCHAR 字段上的
IN或==表达式。 - Trie 索引:该索引有助于对非主键 VARCHAR 字段进行前缀查询(如
LIKE prefix%)。
不过,为 VARCHAR 字段建立索引不会加快速度:
- 按 ID 删除:当 VARCHAR 字段是主键时。
- 不相关的表达式:当 VARCHAR 字段不是删除表达式的一部分时。
还有问题?
你可以
- 在 GitHub 上查看Milvus。随时提问、分享想法并帮助其他用户。
- 加入我们的Discord 频道,寻求支持并与我们的开源社区互动。