使用 Mistral AI、Milvus 和 Llama-agents 的多代理系统
本手册的目标
在本笔记本中,我们将探索不同的想法:
1️⃣将数据存储到Milvus中:学习将数据存储到Milvus中,Milvus是一个高效的向量数据库,专为高速相似性搜索和人工智能应用而设计。
2️⃣結合Mistral模型使用llama-index進行數據查詢:探索如何結合Mistral模型使用llama-index查詢儲存於Milvus的數據。
3️⃣创建自动数据搜索和读取代理:建立能够根据用户查询自动搜索和读取数据的代理。这些自动代理将通过提供快速、准确的响应,减少人工搜索的工作量,从而提升用户体验。
4️⃣开发基于用户查询的元数据过滤代理:实施能够根据用户查询自动生成元数据过滤器的代理,细化搜索结果并将其与上下文联系起来,避免混淆并提高检索信息的准确性,即使对于复杂的查询也是如此。
🔍 小结 在本手册结束时,您将全面了解如何使用 Milvus、带有 llama-agents 的 llama-index 和 Mistral 模型来构建健壮高效的数据检索系统。
Milvus
Milvus 是一个开源向量数据库,通过向量嵌入和相似性搜索为人工智能应用提供动力。
在本笔记本中,我们使用 Milvus Lite,它是 Milvus 的轻量级版本。
有了 Milvus Lite,你可以在几分钟内开始用向量相似性搜索构建人工智能应用!Milvus Lite 适合在以下环境中运行:
- Jupyter Notebook / Google Colab
- 笔记本电脑
- 边缘设备
 图像.png
图像.png
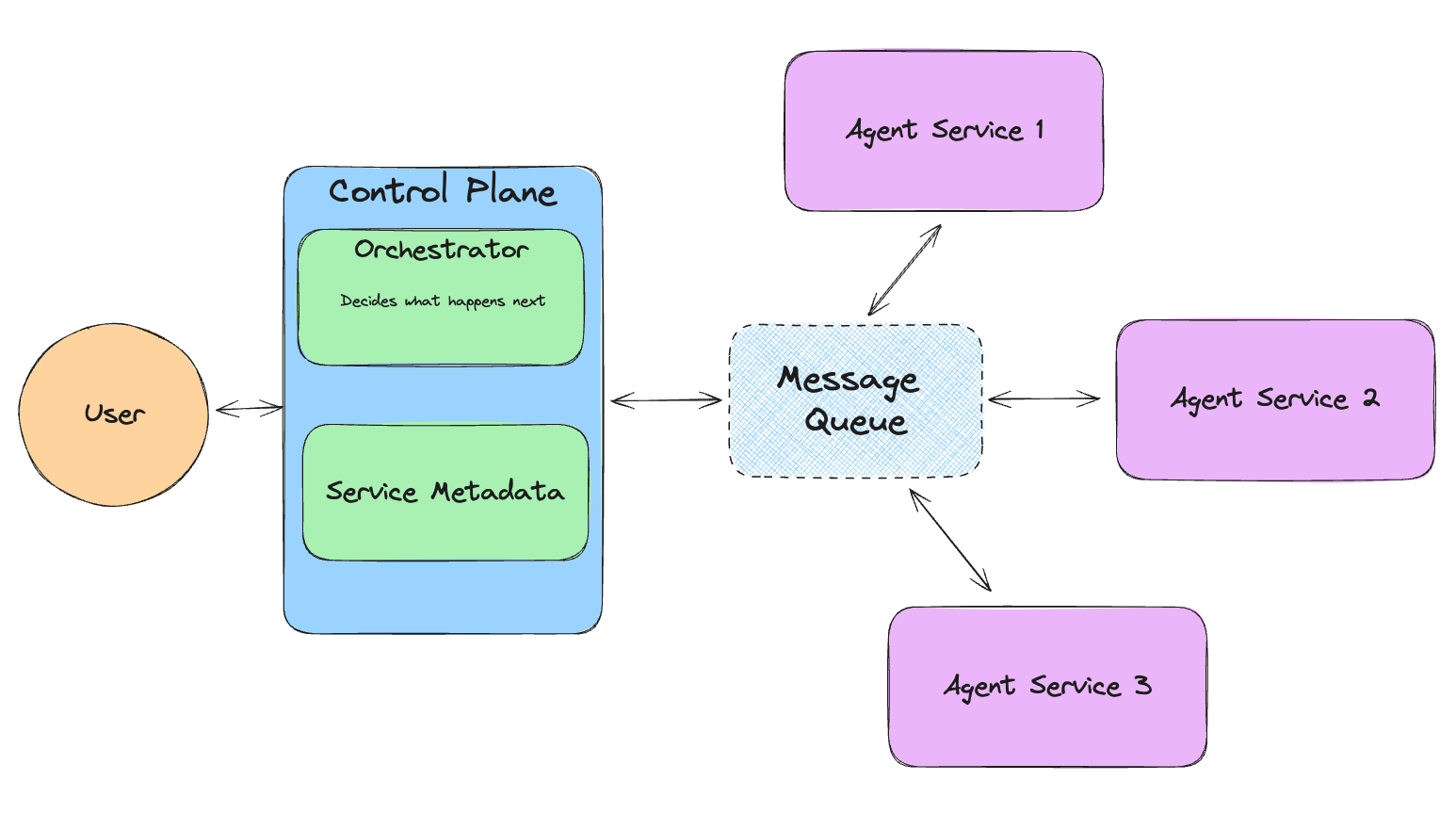
llama-agents
llama-agents 可以将 Agents 作为微服务运行。这样就可以上下扩展服务。
llama-index
LlamaIndex 是 LLM 应用程序的数据框架。它提供的工具包括
- 数据连接器可从本地来源和格式摄取现有数据。
- 数据索引将您的数据结构化为便于 LLMs 使用且性能良好的中间表示形式。
- 引擎提供对数据的自然语言访问。
- Agents 是由 LLM 驱动的知识工作者,通过工具(从简单的辅助功能到 API 集成等)进行增强。
 图片.png
图片.png
Mistral AI
Mistral AI 是一家构建 LLMs 和 Embeddings 模型的研究实验室,他们最近发布了新版本的模型 Mistral Nemo 和 Mistral Large,这两个模型在 RAG 和函数调用方面表现尤为出色。因此,我们将在本笔记本中使用它们。
安装依赖项
$ pip install llama-agents pymilvus milvus-lite openai python-dotenv
$ pip install llama-index-vector-stores-milvus llama-index-readers-file llama-index-llms-ollama llama-index-llms-mistralai llama-index-embeddings-mistralai
# NOTE: This is ONLY necessary in jupyter notebook.
# Details: Jupyter runs an event-loop behind the scenes.
# This results in nested event-loops when we start an event-loop to make async queries.
# This is normally not allowed, we use nest_asyncio to allow it for convenience.
import nest_asyncio
nest_asyncio.apply()
获取 Mistral 的 API 密钥
您可以从Mistral 云控制台获取 Mistral API 密钥。
"""
load_dotenv reads key-value pairs from a .env file and can set them as environment variables.
This is useful to avoid leaking your API key for example :D
"""
from dotenv import load_dotenv
import os
load_dotenv()
True
下载数据
$ mkdir -p 'data/10k/'
$ wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
$ wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'
准备嵌入模型
我们定义了将在本笔记本中使用的 Embedding 模型。我们使用mistral-embed ,它是 Mistral 开发的 Embedding 模型,在训练时考虑了检索问题,因此非常适合我们的 Agentsic RAG 系统。详情请参阅 Mistral 文档中的Embeddings页面。
from llama_index.core import Settings
from llama_index.embeddings.mistralai import MistralAIEmbedding
# Define the default Embedding model used in this Notebook.
# We are using Mistral Models, so we are also using Mistral Embeddings
Settings.embed_model = MistralAIEmbedding(model_name="mistral-embed")
定义 LLM 模型
Llama Index 使用 LLMs 来响应提示和查询,并负责编写自然语言响应。 我们将 Mistral Nemo 定义为默认的一个。Nemo 可提供高达 128k 个词组的大型上下文窗口。它的推理能力、世界知识和编码准确性在同类产品中都是最先进的。
from llama_index.llms.ollama import Ollama
Settings.llm = Ollama("mistral-nemo")
安装 Milvus 并加载数据
Milvus是一个流行的开源向量数据库,它通过高性能、可扩展的向量相似性搜索为人工智能应用提供动力。
- 将 uri 设置为本地文件(如
./milvus.db)是最方便的方法,因为它会自动利用Milvus Lite将所有数据存储到该文件中。 - 如果你有大规模数据,比如超过一百万个向量,你可以在Docker 或 Kubernetes 上设置性能更强的 Milvus 服务器。在此设置中,请使用服务器 uri,例如
http://localhost:19530作为您的 uri。 - 如果你想使用Zilliz Cloud(Milvus 的全托管云服务),请调整 uri 和令牌,它们与 Zilliz Cloud 中的公共端点和 API 密钥相对应。
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
load_index_from_storage,
)
from llama_index.core.tools import QueryEngineTool, ToolMetadata
input_files = ["./data/10k/lyft_2021.pdf", "./data/10k/uber_2021.pdf"]
# Create a single Milvus vector store
vector_store = MilvusVectorStore(
uri="./milvus_demo.db", dim=1024, overwrite=False, collection_name="companies_docs"
)
# Create a storage context with the Milvus vector store
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Load data
docs = SimpleDirectoryReader(input_files=input_files).load_data()
# Build index
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
# Define the query engine
company_engine = index.as_query_engine(similarity_top_k=3)
定义工具
构建有效 Agents 的关键步骤之一是定义它可以用来执行任务的工具。这些工具本质上是 Agents 可以用来检索信息或执行操作的功能或服务。
下面,我们将定义两个工具,让我们的 Agents 可以用来查询 2021 年 Lyft 和 Uber 的财务信息。这些工具将集成到我们的 Agents 中,使其能够用精确的相关信息响应自然语言查询。
如果你看一下我们顶部的图,这就是 "Agent 服务"。
# Define the different tools that can be used by our Agent.
query_engine_tools = [
QueryEngineTool(
query_engine=company_engine,
metadata=ToolMetadata(
name="lyft_10k",
description=(
"Provides information about Lyft financials for year 2021. "
"Use a detailed plain text question as input to the tool."
"Do not attempt to interpret or summarize the data."
),
),
),
QueryEngineTool(
query_engine=company_engine,
metadata=ToolMetadata(
name="uber_10k",
description=(
"Provides information about Uber financials for year 2021. "
"Use a detailed plain text question as input to the tool."
"Do not attempt to interpret or summarize the data."
),
),
),
]
from llama_index.llms.ollama import Ollama
from llama_index.llms.mistralai import MistralAI
# Set up the agent
llm = Ollama(model="mistral-nemo")
response = llm.predict_and_call(
query_engine_tools,
user_msg="Could you please provide a comparison between Lyft and Uber's total revenues in 2021?",
allow_parallel_tool_calls=True,
)
# Example usage without metadata filtering
print("Response without metadata filtering:")
print(response)
Response without metadata filtering:
The revenue for Lyft in 2021 was $3.84 billion.
Uber's total revenue for the year ended December 31, 2021 was $17,455 million.
元数据过滤
Milvus支持元数据过滤,这是一种可以根据与数据相关的特定属性或标签来完善和缩小搜索结果的技术。这在拥有大量数据、只需检索符合特定条件的相关数据子集的情况下特别有用。
元数据过滤使用案例
精确搜索结果:通过应用元数据过滤器,可以确保搜索结果与用户的查询高度相关。例如,如果您有一个财务文档 Collections,您可以根据公司名称、年份或任何其他相关元数据对其进行过滤。
效率:元数据过滤有助于减少需要处理的数据量,提高搜索操作的效率。这在处理大型数据集时尤其有益。
定制:不同的用户或应用程序可能有不同的要求。元数据过滤功能可让您自定义搜索结果,以满足特定需求,例如检索特定年份或公司的文档。
使用示例
在下面的代码块中,元数据过滤用于创建一个过滤查询引擎,根据特定的元数据键值对检索文档:file_name :lyft_2021.pdf
下面定义的QueryEngineTool 比上面定义的更通用,在上面的工具中,我们为每家公司(Uber 和 Lyft)提供了一个工具,而在这个工具中,它更通用。通过添加元数据过滤,我们可以只从特定文档中获取数据。
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
# Example usage with metadata filtering
filters = MetadataFilters(
filters=[ExactMatchFilter(key="file_name", value="lyft_2021.pdf")]
)
print(f"filters: {filters}")
filtered_query_engine = index.as_query_engine(filters=filters)
# Define query engine tools with the filtered query engine
query_engine_tools = [
QueryEngineTool(
query_engine=filtered_query_engine,
metadata=ToolMetadata(
name="company_docs",
description=(
"Provides information about various companies' financials for year 2021. "
"Use a detailed plain text question as input to the tool."
"Use this tool to retrieve specific data points about a company. "
"Do not attempt to interpret or summarize the data."
),
),
),
]
filters: filters=[MetadataFilter(key='file_name', value='lyft_2021.pdf', operator=<FilterOperator.EQ: '=='>)] condition=<FilterCondition.AND: 'and'>
函数调用
Mistral Nemo 和 Large 支持本地函数调用。通过 LLM 上的predict_and_call 函数,可与 LlamaIndex 工具实现无缝集成。这允许用户附加任何工具,并让 LLM 决定调用哪些工具(如果有的话)。
您可以在 llama-index 网站上了解有关Agents的更多信息。
# Set up the LLM we will use for Function Calling
llm = Ollama(model="mistral-nemo")
与 Agents 交互
现在我们可以看到元数据过滤的实际效果:
- 在第一张图中,Agent 应该找不到任何与用户查询相关的信息,因为它是关于 Uber 的,而我们只过滤了关于 Lyft 的文档。
- 在第二个例子中,Agent 应该能找到关于 Lyft 的信息,因为我们只搜索关于 Lyft 的文档。
response = llm.predict_and_call(
query_engine_tools,
user_msg="How many employees does Uber have?",
allow_parallel_tool_calls=True,
)
print(response)
I'm unable to provide information about Uber's employee count as it's outside the given Lyft context.
response = llm.predict_and_call(
query_engine_tools,
user_msg="What are the risk factors for Lyft?",
allow_parallel_tool_calls=True,
)
print(response)
Investing in Lyft carries significant risks. These include general economic factors like impacts from pandemics or crises, operational factors such as competition, pricing changes, and driver/ride growth unpredictability, insurance coverage issues, autonomous vehicle technology uncertainties, reputational concerns, potential security breaches, reliance on third-party services, and challenges in expanding platform offerings. Lyft's business operations are subject to numerous other risks not explicitly mentioned here, which could also harm its financial condition and prospects.
没有元数据过滤的混乱示例
> Question: What are the risk factors for Uber?
> Response without metadata filtering:
Based on the provided context, which pertains to Lyft's Risk Factors section in their Annual Report, some of the potential risk factors applicable to a company like Uber might include:
- General economic factors such as the impact of global pandemics or other crises on ride-sharing demand.
- Operational factors like competition in ride-hailing services, unpredictability in results of operations, and uncertainty about market growth for ridesharing and related services.
- Risks related to attracting and retaining qualified drivers and riders.
在这个例子中,系统错误地提供了关于 Lyft 而不是 Uber 的信息,导致了误导性的回复。系统一开始说它没有相关信息,然后就继续说下去。
使用 Agents 提取元数据过滤器
为了解决这个问题,我们可以使用 Agents 自动从用户的问题中提取元数据过滤器,并在问题解答过程中应用它们。这样就能确保系统检索到正确的相关信息。
代码示例
下面是一个代码示例,演示如何使用代理从用户问题中提取元数据过滤器来创建过滤查询引擎:
说明
提示模板:PromptTemplate 类用于定义从用户问题中提取元数据过滤器的模板。该模板指示语言模型考虑公司名称、年份和其他相关属性。
LLM: Mistral Nemo 用于根据用户的问题生成元数据过滤器。模型根据问题和模板提示提取相关过滤器。
元数据过滤器:对来自 LLM 的响应进行解析,以创建
MetadataFilters对象。如果没有提及特定的筛选器,则会返回一个空的MetadataFilters对象。过滤查询引擎:
index.as_query_engine(filters=metadata_filters)方法会创建一个查询引擎,将提取的元数据过滤器应用到索引中。这可确保只检索符合筛选条件的文档。
from llama_index.core.prompts.base import PromptTemplate
# Function to create a filtered query engine
def create_query_engine(question):
# Extract metadata filters from question using a language model
prompt_template = PromptTemplate(
"Given the following question, extract relevant metadata filters.\n"
"Consider company names, years, and any other relevant attributes.\n"
"Don't write any other text, just the MetadataFilters object"
"Format it by creating a MetadataFilters like shown in the following\n"
"MetadataFilters(filters=[ExactMatchFilter(key='file_name', value='lyft_2021.pdf')])\n"
"If no specific filters are mentioned, returns an empty MetadataFilters()\n"
"Question: {question}\n"
"Metadata Filters:\n"
)
prompt = prompt_template.format(question=question)
llm = Ollama(model="mistral-nemo")
response = llm.complete(prompt)
metadata_filters_str = response.text.strip()
if metadata_filters_str:
metadata_filters = eval(metadata_filters_str)
print(f"eval: {metadata_filters}")
return index.as_query_engine(filters=metadata_filters)
return index.as_query_engine()
response = create_query_engine(
"What is Uber revenue? This should be in the file_name: uber_2021.pdf"
)
eval: filters=[MetadataFilter(key='file_name', value='uber_2021.pdf', operator=<FilterOperator.EQ: '=='>)] condition=<FilterCondition.AND: 'and'>
## Example usage with metadata filtering
question = "What is Uber revenue? This should be in the file_name: uber_2021.pdf"
filtered_query_engine = create_query_engine(question)
# Define query engine tools with the filtered query engine
query_engine_tools = [
QueryEngineTool(
query_engine=filtered_query_engine,
metadata=ToolMetadata(
name="company_docs_filtering",
description=(
"Provides information about various companies' financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]
# Set up the agent with the updated query engine tools
response = llm.predict_and_call(
query_engine_tools,
user_msg=question,
allow_parallel_tool_calls=True,
)
print("Response with metadata filtering:")
print(response)
eval: filters=[MetadataFilter(key='file_name', value='uber_2021.pdf', operator=<FilterOperator.EQ: '=='>)] condition=<FilterCondition.AND: 'and'>
Response with metadata filtering:
Uber's total revenue for the year ended December 31, 2021, is $17.455 billion.
使用 Mistral Large 协调不同服务
Mistral Large 是 Mistral 的旗舰模型,具有非常出色的推理、知识和编码能力。它是需要大型推理能力或高度专业化的复杂任务的理想选择。它具有高级函数调用能力,这正是我们协调不同 Agents 所需要的。
为什么我们需要更智能的模型?
下面要回答的问题特别具有挑战性,因为它需要协调多个服务和代理,以提供一致而准确的响应。这涉及到协调各种工具和 Agents,以检索和处理来自不同来源的信息,例如来自不同公司的财务数据。
这有什么难的?
- 复杂性:这个问题涉及多个 Agents 和服务,每个都有自己的功能和数据源。协调这些 Agents 实现无缝协作是一项复杂的任务。
数据整合:由于数据格式、结构和元数据存在差异,要整合来自不同来源的数据具有挑战性。
语境理解:问题可能需要理解不同信息片段之间的上下文和关系,这是一项要求认知能力的任务。
在这种情况下,Mistral Large 为什么能提供帮助?
Mistral Large 具有高级推理和函数调用功能,非常适合这项任务。以下是它的帮助方式:
高级推理:Mistral Large 可以处理复杂的推理任务,是协调多个 Agents 和服务的理想选择。它可以理解不同信息之间的关系,并做出明智的决策。
函数调用功能:Mistral Large 具有先进的函数调用功能,这对于协调不同 Agents 的行动至关重要。这可以实现各种服务的无缝集成和协调。
专业知识:Mistral Large 专为高度专业化的任务而设计,因此非常适合处理需要深厚领域知识的复杂查询。
鉴于上述原因,我决定在这里使用 Mistral Large 而不是 Mistral Nemo 更为合适。
from llama_agents import (
AgentService,
ToolService,
LocalLauncher,
MetaServiceTool,
ControlPlaneServer,
SimpleMessageQueue,
AgentOrchestrator,
)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.llms.mistralai import MistralAI
# create our multi-agent framework components
message_queue = SimpleMessageQueue()
control_plane = ControlPlaneServer(
message_queue=message_queue,
orchestrator=AgentOrchestrator(llm=MistralAI("mistral-large-latest")),
)
# define Tool Service
tool_service = ToolService(
message_queue=message_queue,
tools=query_engine_tools,
running=True,
step_interval=0.5,
)
# define meta-tools here
meta_tools = [
await MetaServiceTool.from_tool_service(
t.metadata.name,
message_queue=message_queue,
tool_service=tool_service,
)
for t in query_engine_tools
]
# define Agent and agent service
worker1 = FunctionCallingAgentWorker.from_tools(
meta_tools, llm=MistralAI("mistral-large-latest")
)
agent1 = worker1.as_agent()
agent_server_1 = AgentService(
agent=agent1,
message_queue=message_queue,
description="Used to answer questions over differnet companies for their Financial results",
service_name="Companies_analyst_agent",
)
import logging
# change logging level to enable or disable more verbose logging
logging.getLogger("llama_agents").setLevel(logging.INFO)
## Define Launcher
launcher = LocalLauncher(
[agent_server_1, tool_service],
control_plane,
message_queue,
)
query_str = "What are the risk factors for Uber?"
result = launcher.launch_single(query_str)
INFO:llama_agents.message_queues.simple - Consumer AgentService-27cde4ed-5163-4005-90fc-13c158eda7e3: Companies_analyst_agent has been registered.
INFO:llama_agents.message_queues.simple - Consumer ToolService-b73c500a-5fbe-4f57-95c7-db74e173bd1b: default_tool_service has been registered.
INFO:llama_agents.message_queues.simple - Consumer 62465ab8-32ff-436e-95fa-74e828745150: human has been registered.
INFO:llama_agents.message_queues.simple - Consumer ControlPlaneServer-f4c27d43-5474-43ca-93ca-a9aeed4534d7: control_plane has been registered.
INFO:llama_agents.services.agent - Companies_analyst_agent launch_local
INFO:llama_agents.message_queues.base - Publishing message to 'control_plane' with action 'ActionTypes.NEW_TASK'
INFO:llama_agents.message_queues.simple - Launching message queue locally
INFO:llama_agents.services.agent - Processing initiated.
INFO:llama_agents.services.tool - Processing initiated.
INFO:llama_agents.message_queues.base - Publishing message to 'Companies_analyst_agent' with action 'ActionTypes.NEW_TASK'
INFO:llama_agents.message_queues.simple - Successfully published message 'control_plane' to consumer.
INFO:llama_agents.services.agent - Created new task: 0720da2f-1751-4766-a814-ba720bc8a467
INFO:llama_agents.message_queues.simple - Successfully published message 'Companies_analyst_agent' to consumer.
INFO:llama_agents.message_queues.simple - Consumer MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41: MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41 has been registered.
INFO:llama_agents.message_queues.base - Publishing message to 'default_tool_service' with action 'ActionTypes.NEW_TOOL_CALL'
INFO:llama_agents.message_queues.simple - Successfully published message 'default_tool_service' to consumer.
INFO:llama_agents.services.tool - Processing tool call id f4c270a4-bc47-4bbf-92fe-e2cc80757943 with company_docs
INFO:llama_agents.message_queues.base - Publishing message to 'control_plane' with action 'ActionTypes.COMPLETED_TASK'
INFO:llama_agents.message_queues.base - Publishing message to 'MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41' with action 'ActionTypes.COMPLETED_TOOL_CALL'
INFO:llama_agents.message_queues.base - Publishing message to 'Companies_analyst_agent' with action 'ActionTypes.NEW_TASK'
INFO:llama_agents.message_queues.simple - Successfully published message 'control_plane' to consumer.
INFO:llama_agents.message_queues.simple - Successfully published message 'MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41' to consumer.
INFO:llama_agents.services.agent - Created new task: 0720da2f-1751-4766-a814-ba720bc8a467
INFO:llama_agents.message_queues.simple - Successfully published message 'Companies_analyst_agent' to consumer.
INFO:llama_agents.message_queues.base - Publishing message to 'default_tool_service' with action 'ActionTypes.NEW_TOOL_CALL'
INFO:llama_agents.message_queues.simple - Successfully published message 'default_tool_service' to consumer.
INFO:llama_agents.services.tool - Processing tool call id f888f9a8-e716-4505-bfe2-577452e9b6e6 with company_docs
INFO:llama_agents.message_queues.base - Publishing message to 'MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41' with action 'ActionTypes.COMPLETED_TOOL_CALL'
INFO:llama_agents.message_queues.simple - Successfully published message 'MetaServiceTool-5671c175-7b03-4bc8-b60d-bd7101d0fc41' to consumer.
INFO:llama_agents.message_queues.base - Publishing message to 'control_plane' with action 'ActionTypes.COMPLETED_TASK'
INFO:llama_agents.message_queues.base - Publishing message to 'human' with action 'ActionTypes.COMPLETED_TASK'
INFO:llama_agents.message_queues.simple - Successfully published message 'control_plane' to consumer.
INFO:llama_agents.message_queues.simple - Successfully published message 'human' to consumer.
print(result)
[{"name": "finalize", "arguments": {"input": "Uber faces several risk factors, including general economic impacts such as pandemics or downturns, operational challenges like competition, market growth uncertainty, attracting and retaining drivers and riders, insurance adequacy, autonomous vehicle technology development, maintaining its reputation and brand, and managing growth. Additionally, reliance on third-party providers for various services can introduce further risks to its operations."}}]
结论
在本笔记本中,你已经看到了如何使用 llama-agents 通过调用适当的工具来执行不同的操作。通过将 Mistral Large 与 Mistral Nemo 结合使用,我们展示了如何利用不同 LLMs 的优势,有效地协调智能、资源节约型系统。我们看到,Agent 可以挑选包含用户请求的数据的 Collections。