Dense Vector
Dense vectors are numerical data representations widely used in machine learning and data analysis. They consist of arrays with real numbers, where most or all elements are non-zero. Compared to sparse vectors, dense vectors contain more information at the same dimensional level, as each dimension holds meaningful values. This representation can effectively capture complex patterns and relationships, making data easier to analyze and process in high-dimensional spaces. Dense vectors typically have a fixed number of dimensions, ranging from a few dozen to several hundred or even thousands, depending on the specific application and requirements.
Dense vectors are mainly used in scenarios that require understanding the semantics of data, such as semantic search and recommendation systems. In semantic search, dense vectors help capture the underlying connections between queries and documents, improving the relevance of search results. In recommendation systems, they aid in identifying similarities between users and items, offering more personalized suggestions.
Overview
Dense vectors are typically represented as arrays of floating-point numbers with a fixed length, such as [0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5]. The dimensionality of these vectors usually ranges from hundreds to thousands, such as 128, 256, 768, or 1024. Each dimension captures specific semantic features of an object, making it applicable to various scenarios through similarity calculations.
 Dense Vector
Dense Vector
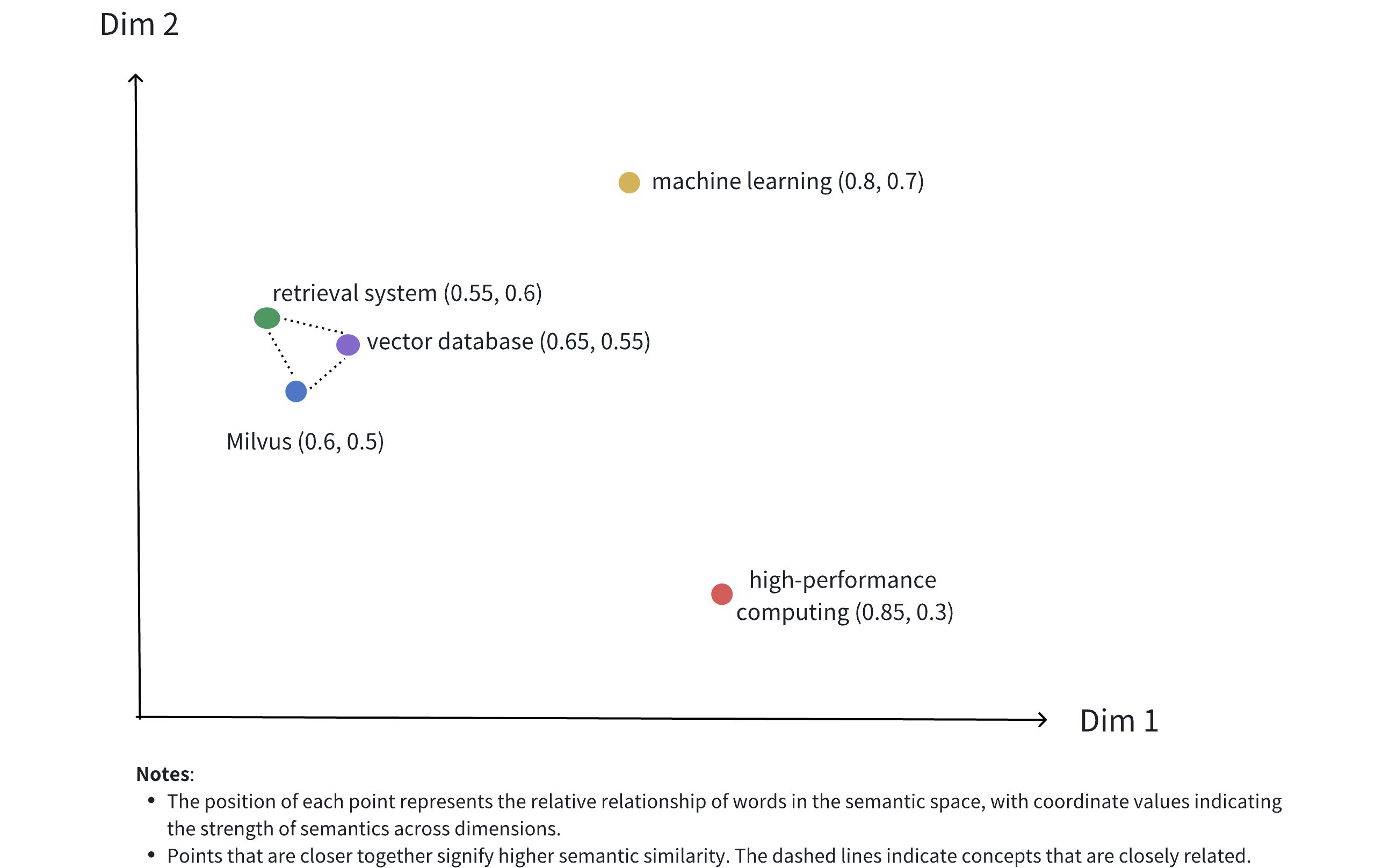
The image above illustrates the representation of dense vectors in a 2D space. Although dense vectors in real-world applications often have much higher dimensions, this 2D illustration effectively conveys several key concepts:
Multidimensional Representation: Each point represents a conceptual object (like Milvus, vector database, retrieval system, etc.), with its position determined by the values of its dimensions.
Semantic Relationships: The distances between points reflect the semantic similarity between concepts. Closer points indicate concepts that are more semantically related.
Clustering Effect: Related concepts (such as Milvus, vector database, and retrieval system) are positioned close to each other in space, forming a semantic cluster.
Below is an example of a real dense vector representing the text "Milvus is an efficient vector database":
[
-0.013052909,
0.020387933,
-0.007869,
-0.11111383,
-0.030188112,
-0.0053388323,
0.0010654867,
0.072027855,
// ... more dimensions
]
Dense vectors can be generated using various embedding models, such as CNN models (like ResNet, VGG) for images and language models (like BERT, Word2Vec) for text. These models transform raw data into points in high-dimensional space, capturing the semantic features of the data. Additionally, Milvus offers convenient methods to help users generate and process dense vectors, as detailed in Embeddings.
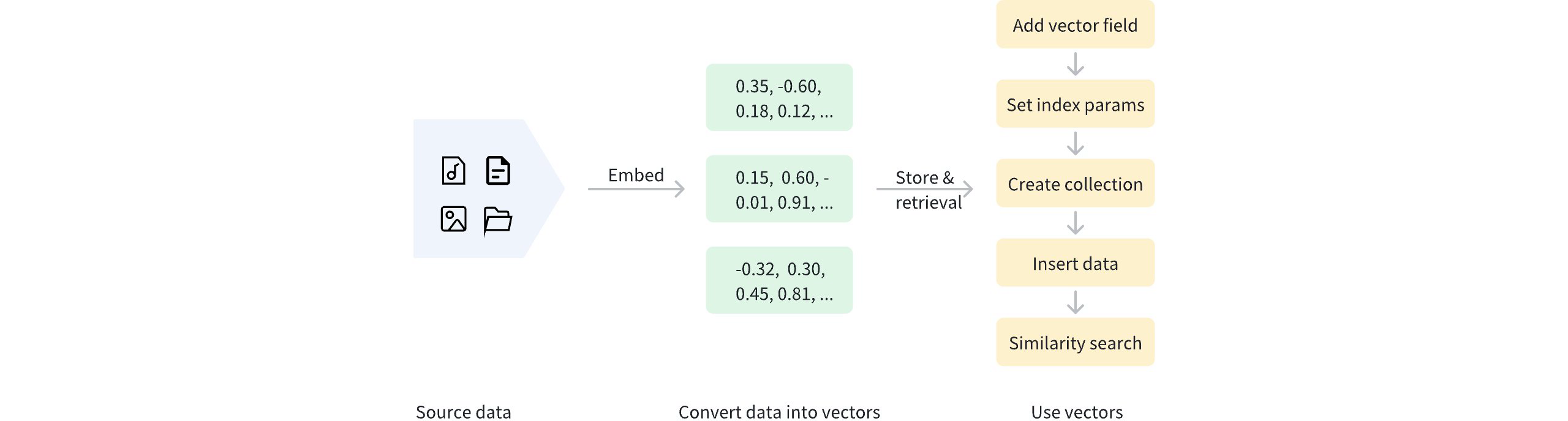
Once data is vectorized, it can be stored in Milvus for management and vector retrieval. The diagram below shows the basic process.
 Use Dense Vector
Use Dense Vector
Besides dense vectors, Milvus also supports sparse vectors and binary vectors. Sparse vectors are suitable for precise matches based on specific terms, such as keyword search and term matching, while binary vectors are commonly used for efficiently handling binarized data, such as image pattern matching and certain hashing applications. For more information, refer to Binary Vector and Sparse Vector.
Use dense vectors
Add vector field
To use dense vectors in Milvus, first define a vector field for storing dense vectors when creating a collection. This process includes:
Setting
datatypeto a supported dense vector data type. For supported dense vector data types, see Data Types.Specifying the dimensions of the dense vector using the
dimparameter.
In the example below, we add a vector field named dense_vector to store dense vectors. The field’s data type is FLOAT_VECTOR, with a dimension of 4.
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=4)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.setEnableDynamicField(true);
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.VarChar)
.isPrimaryKey(true)
.autoID(true)
.maxLength(100)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("dense_vector")
.dataType(DataType.FloatVector)
.dimension(4)
.build());
import { DataType } from "@zilliz/milvus2-sdk-node";
schema.push({
name: "dense_vector",
data_type: DataType.FloatVector,
dim: 4,
});
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("pk").
WithDataType(entity.FieldTypeVarChar).
WithIsPrimaryKey(true).
WithIsAutoID(true).
WithMaxLength(100),
).WithField(entity.NewField().
WithName("dense_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(4),
)
export primaryField='{
"fieldName": "pk",
"dataType": "VarChar",
"isPrimary": true,
"elementTypeParams": {
"max_length": 100
}
}'
export vectorField='{
"fieldName": "dense_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 4
}
}'
export schema="{
\"autoID\": true,
\"fields\": [
$primaryField,
$vectorField
]
}"
Supported data types for dense vector fields:
Data Type |
Description |
|---|---|
|
Stores 32-bit floating-point numbers, commonly used for representing real numbers in scientific computations and machine learning. Ideal for scenarios requiring high precision, such as distinguishing similar vectors. |
|
Stores 16-bit half-precision floating-point numbers, used for deep learning and GPU computations. It saves storage space in scenarios where precision is less critical, such as in the low-precision recall phase of recommendation systems. |
|
Stores 16-bit Brain Floating Point (bfloat16) numbers, offering the same range of exponents as Float32 but with reduced precision. Suitable for scenarios that need to process large volumes of vectors quickly, such as large-scale image retrieval. |
|
Stores vectors whose individual elements in each dimension are 8-bit integers (int8), with each element ranging from –128 to 127. Designed for quantized deep learning models (e.g., ResNet, EfficientNet), INT8_VECTOR reduces model size and speeds up inference with minimal precision loss. |
Set index params for vector field
To accelerate semantic searches, an index must be created for the vector field. Indexing can significantly improve the retrieval efficiency of large-scale vector data.
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense_vector",
index_name="dense_vector_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("dense_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build());
import { MetricType, IndexType } from "@zilliz/milvus2-sdk-node";
const indexParams = {
index_name: 'dense_vector_index',
field_name: 'dense_vector',
metric_type: MetricType.IP,
index_type: IndexType.AUTOINDEX
};
idx := index.NewAutoIndex(index.MetricType(entity.IP))
indexOption := milvusclient.NewCreateIndexOption("my_collection", "dense_vector", idx)
export indexParams='[
{
"fieldName": "dense_vector",
"metricType": "IP",
"indexName": "dense_vector_index",
"indexType": "AUTOINDEX"
}
]'
In the example above, an index named dense_vector_index is created for the dense_vector field using the AUTOINDEX index type. The metric_type is set to IP, indicating that inner product will be used as the distance metric.
Milvus provides various index types for a better vector search experience. AUTOINDEX is a special index type designed to smooth the learning curve of vector search. There are a lot of index types available for you to choose from. For details, refer to xxx.
Milvus supports other metric types. For more information, refer to Metric Types.
Create collection
Once the dense vector and index param settings are complete, you can create a collection containing dense vectors. The example below uses the create_collection method to create a collection named my_collection.
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
import { MilvusClient } from "@zilliz/milvus2-sdk-node";
const client = new MilvusClient({
address: 'http://localhost:19530'
});
await client.createCollection({
collection_name: 'my_collection',
schema: schema,
index_params: indexParams
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Insert data
After creating the collection, use the insert method to add data containing dense vectors. Ensure that the dimensionality of the dense vectors being inserted matches the dim value defined when adding the dense vector field.
data = [
{"dense_vector": [0.1, 0.2, 0.3, 0.7]},
{"dense_vector": [0.2, 0.3, 0.4, 0.8]},
]
client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
rows.add(gson.fromJson("{\"dense_vector\": [0.1, 0.2, 0.3, 0.4]}", JsonObject.class));
rows.add(gson.fromJson("{\"dense_vector\": [0.2, 0.3, 0.4, 0.5]}", JsonObject.class));
InsertResp insertR = client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
const data = [
{ dense_vector: [0.1, 0.2, 0.3, 0.7] },
{ dense_vector: [0.2, 0.3, 0.4, 0.8] },
];
client.insert({
collection_name: "my_collection",
data: data,
});
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithFloatVectorColumn("dense_vector", 4, [][]float32{
{0.1, 0.2, 0.3, 0.7},
{0.2, 0.3, 0.4, 0.8},
}),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{"dense_vector": [0.1, 0.2, 0.3, 0.4]},
{"dense_vector": [0.2, 0.3, 0.4, 0.5]}
],
"collectionName": "my_collection"
}'
## {"code":0,"cost":0,"data":{"insertCount":2,"insertIds":["453577185629572531","453577185629572532"]}}
Perform similarity search
Semantic search based on dense vectors is one of the core features of Milvus, allowing you to quickly find data that is most similar to a query vector based on the distance between vectors. To perform a similarity search, prepare the query vector and search parameters, then call the search method.
search_params = {
"params": {"nprobe": 10}
}
query_vector = [0.1, 0.2, 0.3, 0.7]
res = client.search(
collection_name="my_collection",
data=[query_vector],
anns_field="dense_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
# Output
# data: ["[{'id': '453718927992172271', 'distance': 0.7599999904632568, 'entity': {'pk': '453718927992172271'}}, {'id': '453718927992172270', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172270'}}]"]
import io.milvus.v2.service.vector.request.data.FloatVec;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("nprobe",10);
FloatVec queryVector = new FloatVec(new float[]{0.1f, 0.3f, 0.3f, 0.4f});
SearchResp searchR = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.annsField("dense_vector")
.searchParams(searchParams)
.topK(5)
.outputFields(Collections.singletonList("pk"))
.build());
System.out.println(searchR.getSearchResults());
// Output
//
// [[SearchResp.SearchResult(entity={pk=453444327741536779}, score=0.65, id=453444327741536779), SearchResp.SearchResult(entity={pk=453444327741536778}, score=0.65, id=453444327741536778)]]
query_vector = [0.1, 0.2, 0.3, 0.7];
client.search({
collection_name: 'my_collection',
data: query_vector,
limit: 5,
output_fields: ['pk'],
params: {
nprobe: 10
}
});
queryVector := []float32{0.1, 0.2, 0.3, 0.7}
annParam := index.NewCustomAnnParam()
annParam.WithExtraParam("nprobe", 10)
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("dense_vector").
WithOutputFields("pk").
WithAnnParam(annParam))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("Pks: ", resultSet.GetColumn("pk").FieldData().GetScalars())
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.1, 0.2, 0.3, 0.7]
],
"annsField": "dense_vector",
"limit": 5,
"searchParams":{
"params":{"nprobe":10}
},
"outputFields": ["pk"]
}'
## {"code":0,"cost":0,"data":[{"distance":0.55,"id":"453577185629572532","pk":"453577185629572532"},{"distance":0.42,"id":"453577185629572531","pk":"453577185629572531"}]}
For more information on similarity search parameters, refer to Basic ANN Search.