Métricas de similaridade
No Milvus, as métricas de semelhança são utilizadas para medir as semelhanças entre vectores. A escolha de uma boa métrica de distância ajuda a melhorar significativamente o desempenho da classificação e do agrupamento.
A tabela seguinte mostra como estas métricas de similaridade amplamente utilizadas se adaptam a várias formas de dados de entrada e índices Milvus. Atualmente, o Milvus suporta vários tipos de dados, incluindo incrustações de vírgula flutuante (frequentemente conhecidas como vectores de vírgula flutuante ou vectores densos), incrustações binárias (também conhecidas como vectores binários) e incrustações esparsas (também conhecidas como vectores esparsos).
| Tipos de métricas | Tipos de índices |
|---|---|
|
|
| Tipos de métricas | Tipos de índices |
|---|---|
|
|
| Tipos métricos | Tipos de índice |
|---|---|
| IP |
|
Distância euclidiana (L2)
Essencialmente, a distância euclidiana mede o comprimento de um segmento que liga 2 pontos.
A fórmula para a distância euclidiana é a seguinte:
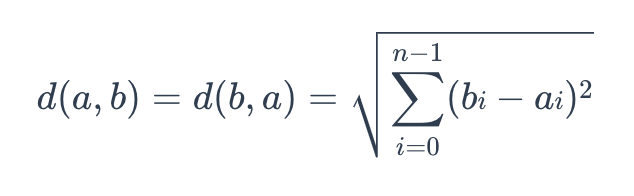 euclidiana
euclidiana
em que a = (a0, a1,...,an-1) e b = (b0, b0,..., bn-1) são dois pontos num espaço euclidiano n-dimensional
É a métrica de distância mais comummente utilizada e é muito útil quando os dados são contínuos.
Produto interno (IP)
A distância IP entre duas incorporações vectoriais é definida da seguinte forma
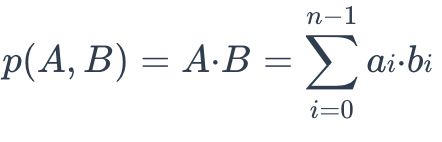 ip
ip
O PI é mais útil se precisar de comparar dados não normalizados ou quando se preocupa com a magnitude e o ângulo.
Se aplicar a métrica de distância IP a incorporações normalizadas, o resultado será equivalente ao cálculo da semelhança de cosseno entre as incorporações.
Suponha que X' é normalizado a partir da incorporação X:
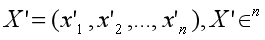 normalizar
normalizar
A correlação entre os dois embeddings é a seguinte:
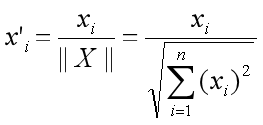 normalização
normalização
Similaridade de cosseno
A semelhança de cosseno utiliza o cosseno do ângulo entre dois conjuntos de vectores para medir a sua semelhança. Pode pensar nos dois conjuntos de vectores como dois segmentos de linha que começam na mesma origem ([0,0,...]) mas apontam em direcções diferentes.
Para calcular a semelhança de cosseno entre dois conjuntos de vectores A = (a0, a1,...,an-1) e B = (b0, b1,..., bn-1), utilize a seguinte fórmula:
 coseno_similaridade
coseno_similaridade
A semelhança de cosseno está sempre no intervalo [-1, 1]. Por exemplo, dois vectores proporcionais têm uma semelhança de cosseno de 1, dois vectores ortogonais têm uma semelhança de 0 e dois vectores opostos têm uma semelhança de -1. Quanto maior for o cosseno, menor é o ângulo entre dois vectores, indicando que esses dois vectores são mais semelhantes entre si.
Ao subtrair a semelhança de cosseno de 1, obtém-se a distância de cosseno entre dois vectores.
Distância de Jaccard
O coeficiente de semelhança de Jaccard mede a semelhança entre dois conjuntos de amostras e é definido como a cardinalidade da intersecção dos conjuntos definidos dividida pela cardinalidade da união dos mesmos. Só pode ser aplicado a conjuntos de amostras finitos.
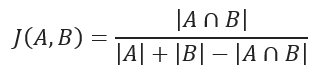 Coeficiente de semelhança de Jaccard
Coeficiente de semelhança de Jaccard
A distância de Jaccard mede a dissemelhança entre conjuntos de dados e é obtida subtraindo o coeficiente de semelhança de Jaccard de 1. Para variáveis binárias, a distância de Jaccard é equivalente ao coeficiente de Tanimoto.
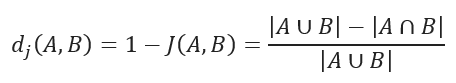 Distância de Jaccard
Distância de Jaccard
Distância de Hamming
A distância de Hamming mede cadeias de dados binárias. A distância entre duas cadeias de dados de igual comprimento é o número de posições de bits em que os bits são diferentes.
Por exemplo, suponha que existem duas cadeias de caracteres, 1101 1001 e 1001 1101.
11011001 ⊕ 10011101 = 01000100. Como isso contém dois 1s, a distância de Hamming, d (11011001, 10011101) = 2.
Similaridade Estrutural
Quando uma estrutura química ocorre como parte de uma estrutura química maior, a primeira é chamada de subestrutura e a segunda é chamada de superestrutura. Por exemplo, o etanol é uma subestrutura do ácido acético, e o ácido acético é uma superestrutura do etanol.
A semelhança estrutural é utilizada para determinar se duas fórmulas químicas são semelhantes entre si no sentido em que uma é a superestrutura ou a subestrutura da outra.
Para determinar se A é uma superestrutura de B, utilize a seguinte fórmula:
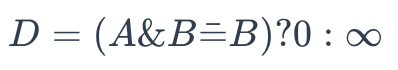 superestrutura
superestrutura
Onde:
- A é a representação binária de uma fórmula química a ser recuperada
- B é a representação binária de uma fórmula química na base de dados
Se o resultado for 0, A não é uma superestrutura de B. Caso contrário, o resultado é o inverso.
Para determinar se A é uma subestrutura de B, utilize a seguinte fórmula:
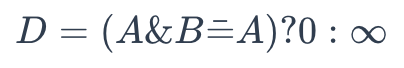 subestrutura
subestrutura
Onde:
- A é a representação binária de uma fórmula química a ser recuperada
- B é a representação binária de uma fórmula química na base de dados
Se o resultado for 0, A não é uma subestrutura de B. Caso contrário, o resultado é o inverso.
PERGUNTAS FREQUENTES
Porque é que o resultado top1 de uma pesquisa vetorial não é o próprio vetor de pesquisa, se o tipo de métrica for o produto interno?
Isto ocorre se não tiver normalizado os vectores ao utilizar o produto interno como métrica de distância.O que é normalização? Porque é que a normalização é necessária?
A normalização refere-se ao processo de conversão de uma incorporação (vetor) para que a sua norma seja igual a 1. Se utilizar o produto interno para calcular as semelhanças das incorporações, tem de normalizar as incorporações. Após a normalização, o produto interno é igual à similaridade de cosseno.
Consulte a Wikipédia para obter mais informações.
Por que obtenho resultados diferentes usando a distância euclidiana (L2) e o produto interno (PI) como métrica de distância?
Verifique se os vetores estão normalizados. Se não estiverem, é necessário normalizar os vectores primeiro. Teoricamente, as semelhanças obtidas por L2 são diferentes das semelhanças obtidas por IP, se os vectores não estiverem normalizados.O que vem a seguir
- Saiba mais sobre os tipos de índices suportados no Milvus.