Visão geral da arquitetura do Milvus
O Milvus é um banco de dados vetorial de código aberto e nativo da nuvem projetado para pesquisa de similaridade de alto desempenho em conjuntos de dados vetoriais maciços. Criado com base em bibliotecas populares de pesquisa vetorial, incluindo Faiss, HNSW, DiskANN e SCANN, ele capacita aplicativos de IA e cenários de recuperação de dados não estruturados. Antes de prosseguir, familiarize-se com os princípios básicos da recuperação de incorporação.
Diagrama de arquitetura
O diagrama a seguir ilustra a arquitetura de alto nível do Milvus, mostrando seu design modular, escalável e nativo da nuvem com camadas de armazenamento e computação totalmente desagregadas.
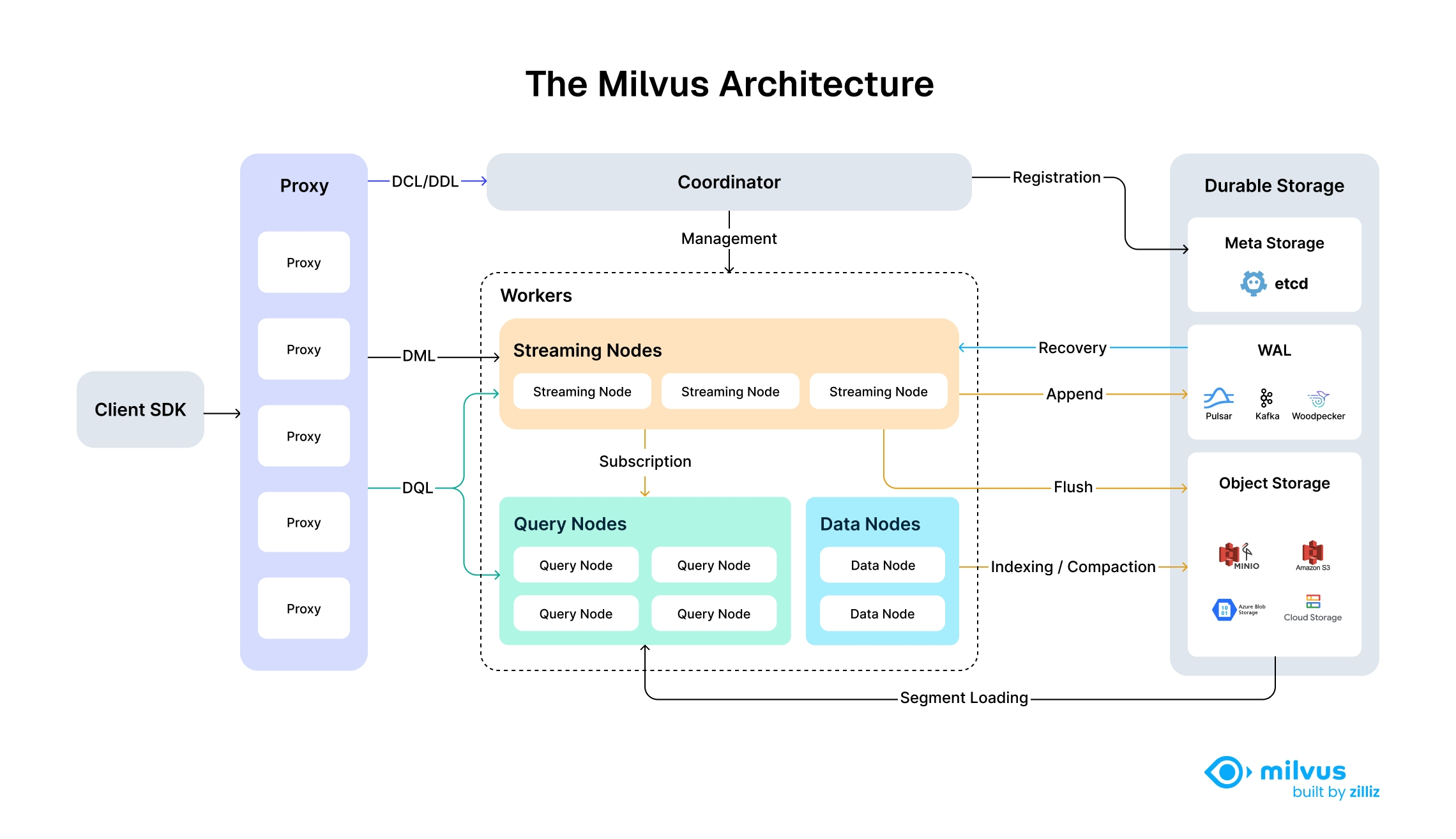 Diagrama de arquitetura
Diagrama de arquitetura
Princípios da arquitetura
O Milvus segue o princípio da desagregação do plano de dados e do plano de controlo, compreendendo quatro camadas principais que são mutuamente independentes em termos de escalabilidade e recuperação de desastres. Esta arquitetura de armazenamento partilhado com camadas de armazenamento e de computação totalmente desagregadas permite o escalonamento horizontal dos nós de computação, ao mesmo tempo que implementa o Woodpecker como uma camada WAL de disco zero para uma maior elasticidade e uma menor sobrecarga operacional.
Ao separar o processamento de streaming no Streaming Node e o processamento em lote no Query Node e no Data Node, o Milvus atinge um elevado desempenho, satisfazendo simultaneamente os requisitos de processamento em tempo real.
Arquitetura detalhada das camadas
Camada 1: Camada de acesso
Composta por um grupo de proxies sem estado, a camada de acesso é a camada frontal do sistema e o ponto final para os utilizadores. Valida os pedidos dos clientes e reduz os resultados devolvidos:
- O proxy é, por si só, apátrida. Fornece um endereço de serviço unificado utilizando componentes de balanceamento de carga como o Nginx, o Kubernetes Ingress, o NodePort e o LVS.
- Como o Milvus utiliza uma arquitetura de processamento massivamente paralelo (MPP), o proxy agrega e pós-processa os resultados intermédios antes de devolver os resultados finais ao cliente.
Camada 2: Coordenador
O Coordinator funciona como o cérebro do Milvus. Em qualquer momento, está ativo exatamente um Coordenador em todo o cluster, responsável pela manutenção da topologia do cluster, pelo agendamento de todos os tipos de tarefas e pela garantia de consistência ao nível do cluster.
A seguir estão algumas das tarefas tratadas pelo Coordenador:
- Gerenciamento de DDL/DCL/TSO: Trata os pedidos de linguagem de definição de dados (DDL) e de linguagem de controlo de dados (DCL), tais como a criação ou eliminação de colecções, partições ou índices, bem como a gestão do timestamp Oracle (TSO) e a emissão de time ticker.
- Gestão do serviço de streaming: Vincula o Write-Ahead Log (WAL) aos nós de streaming e fornece descoberta de serviço para o serviço de streaming.
- Gestão de consultas: Gere a topologia e o equilíbrio de carga para os nós de consulta, e fornece e gere as vistas de consulta de serviço para orientar o encaminhamento da consulta.
- Gestão de dados históricos: Distribui tarefas offline, como compactação e construção de índices para nós de dados, e gerencia a topologia de segmentos e visualizações de dados.
Camada 3: Nós de trabalho
Os braços e as pernas. Os nós de trabalho são executores burros que seguem as instruções do coordenador. Os nós de trabalho não têm estado graças à separação do armazenamento e da computação, e podem facilitar a expansão do sistema e a recuperação de desastres quando implantados no Kubernetes. Existem três tipos de nós de trabalho:
Nó de streaming
O Streaming Node funciona como o "mini-cérebro" ao nível do shard, fornecendo garantias de consistência ao nível do shard e recuperação de falhas com base no armazenamento WAL subjacente. Entretanto, o Streaming Node também é responsável pela consulta de dados crescentes e pela geração de planos de consulta. Além disso, também lida com a conversão de dados crescentes em dados selados (históricos).
Nó de consulta
O nó de consulta carrega os dados históricos do armazenamento de objectos e fornece a consulta de dados históricos.
Nó de dados
O nó de dados é responsável pelo processamento offline dos dados históricos, como a compactação e a criação de índices.
Camada 4: Armazenamento
O armazenamento é o osso do sistema, responsável pela persistência dos dados. Inclui meta-armazenamento, corretor de registos e armazenamento de objectos.
Meta-armazenamento
O meta-armazenamento armazena instantâneos de metadados, como o esquema de coleção e os pontos de controlo do consumo de mensagens. O armazenamento de metadados exige uma disponibilidade extremamente elevada, uma forte consistência e suporte de transacções, pelo que a Milvus escolheu o etcd para o meta storage. A Milvus também utiliza o etcd para registo de serviços e verificação da sua integridade.
Armazenamento de objectos
O armazenamento de objectos armazena ficheiros de instantâneos de registos, ficheiros de índice para dados escalares e vectoriais e resultados de consultas intermédias. O Milvus utiliza o MinIO como armazenamento de objectos e pode ser facilmente implementado no AWS S3 e no Azure Blob, dois dos serviços de armazenamento mais populares e económicos do mundo. No entanto, o armazenamento de objectos tem uma latência de acesso elevada e cobra pelo número de consultas. Para melhorar o seu desempenho e reduzir os custos, a Milvus planeia implementar a separação de dados cold-hot num conjunto de cache baseado em memória ou SSD.
Armazenamento WAL
O armazenamento WAL (Write-Ahead Log) é a base da durabilidade e consistência dos dados em sistemas distribuídos. Antes de qualquer alteração ser confirmada, é primeiro registada num registo - garantindo que, em caso de falha, pode recuperar exatamente onde parou.
As implementações comuns de WAL incluem Kafka, Pulsar e Woodpecker. Ao contrário das soluções tradicionais baseadas em disco, o Woodpecker adota um design nativo da nuvem, sem disco, que grava diretamente no armazenamento de objetos. Essa abordagem é dimensionada sem esforço de acordo com suas necessidades e simplifica as operações ao remover a sobrecarga de gerenciamento de discos locais.
Ao registar antecipadamente cada operação de escrita, a camada WAL garante um mecanismo fiável de recuperação e consistência em todo o sistema, independentemente da complexidade do seu ambiente distribuído.
Fluxo de Dados e Categorias de API
As APIs do Milvus são categorizadas por sua função e seguem caminhos específicos através da arquitetura:
| Categoria da API | Operações | Exemplo de APIs | Fluxo da arquitetura |
|---|---|---|---|
| DDL/DCL | Esquema e controlo de acesso | createCollection, dropCollection, hasCollection, createPartition | Camada de acesso → Coordenador |
| DML | Manipulação de dados | insert, delete, upsert | Camada de acesso → Nó de trabalho de fluxo contínuo |
| DQL | Consulta de dados | search, query | Camada de acesso → Nó de trabalho em lote (nós de consulta) |
Exemplo de fluxo de dados: operação de pesquisa
- O cliente envia um pedido de pesquisa através do SDK/API RESTful
- O balanceador de carga encaminha o pedido para o proxy disponível na camada de acesso
- O proxy utiliza a cache de encaminhamento para determinar os nós de destino; contacta o coordenador apenas se a cache não estiver disponível
- O proxy encaminha o pedido para os nós de streaming adequados, que depois coordenam com os nós de consulta para a pesquisa de dados selados enquanto executam localmente a pesquisa de dados crescentes
- Os nós de consulta carregam segmentos selados do Object Storage conforme necessário e efectuam a pesquisa ao nível do segmento
- Os resultados da pesquisa são submetidos a uma redução multinível: Os nós de consulta reduzem os resultados em vários segmentos, os nós de streaming reduzem os resultados dos nós de consulta e o proxy reduz os resultados de todos os nós de streaming antes de retornar ao cliente
Exemplo de fluxo de dados: inserção de dados
- O cliente envia um pedido de inserção com dados vectoriais
- A camada de acesso valida e encaminha o pedido para o nó de fluxo contínuo
- O nó de fluxo contínuo regista a operação no armazenamento WAL para durabilidade
- Os dados são processados em tempo real e disponibilizados para consultas
- Quando os segmentos atingem a capacidade, o nó de streaming acciona a conversão para segmentos selados
- O Data Node trata da compactação e constrói índices em cima dos segmentos selados, armazenando os resultados no Object Storage
- Os nós de consulta carregam os índices recém-construídos e substituem os dados crescentes correspondentes
O que vem a seguir
- Explore os componentes principais para obter detalhes específicos de implementação
- Saiba mais sobre fluxos de trabalho de processamento de dados e estratégias de otimização
- Compreender o Modelo de Consistência e as garantias de transação em Milvus