Text to Image Search Engine
This tutorial demonstrates how to use Milvus, the open-source vector database, to build a text-to-image search engine.
You can quickly build a minimum viable text-to-image search engine by following the basic tutorial. Alternatively, you can also read the deep dive tutorial which covers everything from model selection to service deployment. You can build a more advanced text-to-image search engine catering to your own business need by following the instructions in the deep dive tutorial.
The ML model and third-party software used include:
Nowadays, traditional text search engines are losing their charm with more and more people turning to TikTok as their favorite search engine. During a traditional text search, people input keywords and be shown all the texts containing the keyword. However, people complain that they cannot always find what they want in a search like this. What’s more, the results are not intuitive enough. People say they find images and videos much more intuitive and pleasant than having to crawl through lines of text. The cross-modal text-to-image search engine emerged as a result. With such a new type of search engine, people can find relevant images by inputting a chunk of text of some keywords.
In this tutorial, you will learn how to build a text-to-image search engine. This tutorial uses the CLIP model to extract features of images and convert them into vectors. Then these image vectors are stored in the Milvus vector database. When users input query texts, these texts are also converted into embedding vectors using the same ML model CLIP. Subsequently, a vector similarity search is performed in Milvus to retrieve the most similar image vectors to the input text vector.
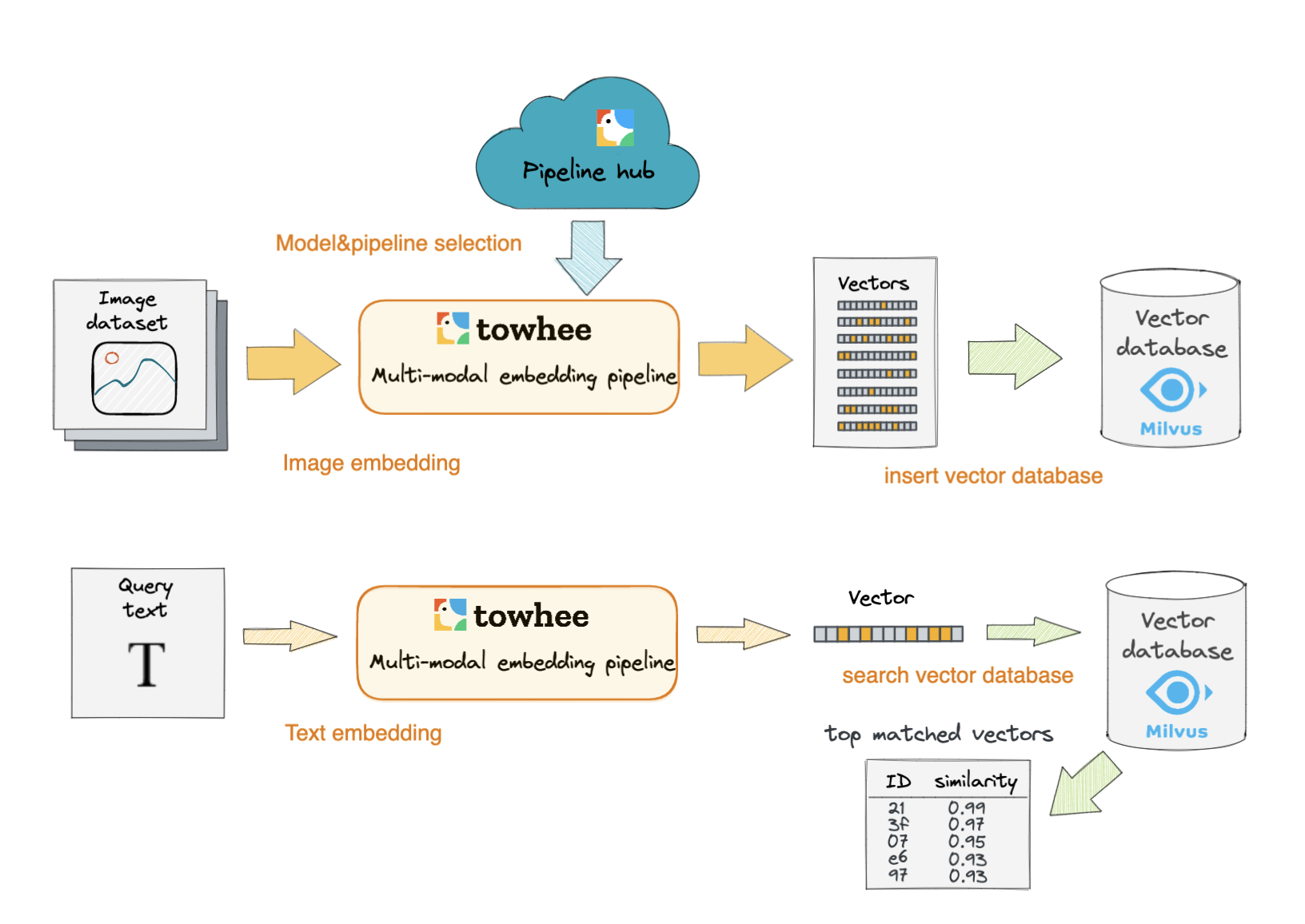 Text_image_search
Text_image_search