Milvus를 사용한 그래프 RAG
![]()
대규모 언어 모델이 광범위하게 적용되면서 응답의 정확성과 관련성을 개선하는 것이 중요해졌습니다. 검색 증강 생성(RAG)은 외부 지식 베이스로 모델을 강화하여 더 많은 맥락 정보를 제공하고 환각이나 지식 부족과 같은 문제를 완화합니다. 그러나 단순한 RAG 패러다임에만 의존하는 것은 한계가 있으며, 특히 모델이 정확한 답변을 제공하기 어려운 복잡한 개체 관계와 멀티홉 질문을 다룰 때는 더욱 그렇습니다.
지식 그래프(KG)를 RAG 시스템에 도입하면 새로운 해결책을 찾을 수 있습니다. KG는 엔티티와 그 관계를 구조화된 방식으로 제시하여 보다 정확한 검색 정보를 제공하고 RAG가 복잡한 질문 답변 작업을 더 잘 처리할 수 있도록 도와줍니다. KG-RAG는 아직 초기 단계에 있으며, KG에서 엔티티와 관계를 효과적으로 검색하는 방법이나 벡터 유사도 검색을 그래프 구조와 통합하는 방법에 대한 합의가 아직 이루어지지 않은 상태입니다.
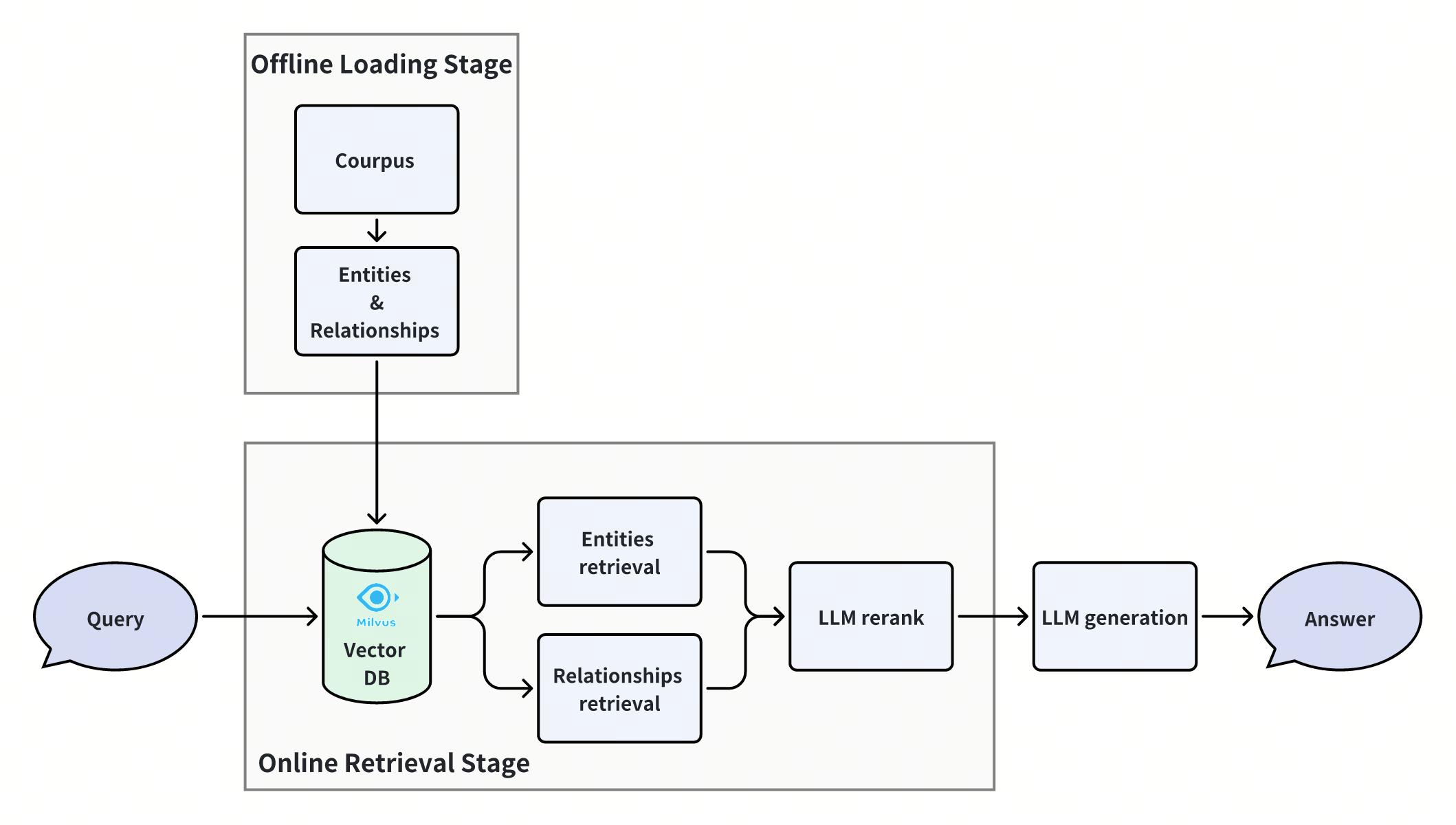
이 노트북에서는 이 시나리오의 성능을 크게 향상시킬 수 있는 간단하면서도 강력한 접근 방식을 소개합니다. 이 방법은 다방향 검색 후 재순위를 매기는 단순한 RAG 패러다임이지만 그래프 RAG를 논리적으로 구현하고 멀티홉 질문을 처리하는 데 있어 최첨단 성능을 달성합니다. 어떻게 구현되는지 살펴보겠습니다.
전제 조건
이 노트북을 실행하기 전에 다음 종속성이 설치되어 있는지 확인하세요:
$ pip install --upgrade --quiet pymilvus numpy scipy langchain langchain-core langchain-openai tqdm
Google Colab을 사용하는 경우 방금 설치한 종속성을 사용하려면 런타임을 다시 시작해야 할 수 있습니다(화면 상단의 '런타임' 메뉴를 클릭하고 드롭다운 메뉴에서 '세션 다시 시작'을 선택).
OpenAI의 모델을 사용합니다. 환경 변수로 OPENAI_API_KEY API 키를 준비해야 합니다.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
필요한 라이브러리와 종속성을 가져옵니다.
import numpy as np
from collections import defaultdict
from scipy.sparse import csr_matrix
from pymilvus import MilvusClient
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from tqdm import tqdm
Milvus 클라이언트, LLM 및 임베딩 모델의 인스턴스를 초기화합니다.
milvus_client = MilvusClient(uri="./milvus.db")
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
MilvusClient의 인수를 사용합니다:
uri를 로컬 파일(예:./milvus.db)로 설정하는 것이 가장 편리한 방법인데, Milvus Lite를 자동으로 활용하여 모든 데이터를 이 파일에 저장하기 때문입니다.- 데이터 규모가 큰 경우, 도커나 쿠버네티스에 더 성능이 좋은 Milvus 서버를 설정할 수 있습니다. 이 설정에서는 서버 URL(예:
http://localhost:19530)을uri으로 사용하세요. - 밀버스의 완전 관리형 클라우드 서비스인 질리즈 클라우드를 사용하려면, 질리즈 클라우드의 퍼블릭 엔드포인트와 API 키에 해당하는
uri와token을 조정하세요.
오프라인 데이터 불러오기
데이터 준비
베르누이 군과 오일러의 관계를 소개하는 나노 데이터셋을 예시로 들어 설명하겠습니다. 나노 데이터 세트에는 4개의 구절과 그에 해당하는 삼중 항 세트가 포함되어 있으며, 각 삼중 항에는 주어, 서술어, 목적어가 포함됩니다. 실제로는 사용자 지정 말뭉치에서 삼중 항을 추출하는 데 어떤 접근 방식을 사용하든 상관없습니다.
nano_dataset = [
{
"passage": "Jakob Bernoulli (1654–1705): Jakob was one of the earliest members of the Bernoulli family to gain prominence in mathematics. He made significant contributions to calculus, particularly in the development of the theory of probability. He is known for the Bernoulli numbers and the Bernoulli theorem, a precursor to the law of large numbers. He was the older brother of Johann Bernoulli, another influential mathematician, and the two had a complex relationship that involved both collaboration and rivalry.",
"triplets": [
["Jakob Bernoulli", "made significant contributions to", "calculus"],
[
"Jakob Bernoulli",
"made significant contributions to",
"the theory of probability",
],
["Jakob Bernoulli", "is known for", "the Bernoulli numbers"],
["Jakob Bernoulli", "is known for", "the Bernoulli theorem"],
["The Bernoulli theorem", "is a precursor to", "the law of large numbers"],
["Jakob Bernoulli", "was the older brother of", "Johann Bernoulli"],
],
},
{
"passage": "Johann Bernoulli (1667–1748): Johann, Jakob’s younger brother, was also a major figure in the development of calculus. He worked on infinitesimal calculus and was instrumental in spreading the ideas of Leibniz across Europe. Johann also contributed to the calculus of variations and was known for his work on the brachistochrone problem, which is the curve of fastest descent between two points.",
"triplets": [
[
"Johann Bernoulli",
"was a major figure of",
"the development of calculus",
],
["Johann Bernoulli", "was", "Jakob's younger brother"],
["Johann Bernoulli", "worked on", "infinitesimal calculus"],
["Johann Bernoulli", "was instrumental in spreading", "Leibniz's ideas"],
["Johann Bernoulli", "contributed to", "the calculus of variations"],
["Johann Bernoulli", "was known for", "the brachistochrone problem"],
],
},
{
"passage": "Daniel Bernoulli (1700–1782): The son of Johann Bernoulli, Daniel made major contributions to fluid dynamics, probability, and statistics. He is most famous for Bernoulli’s principle, which describes the behavior of fluid flow and is fundamental to the understanding of aerodynamics.",
"triplets": [
["Daniel Bernoulli", "was the son of", "Johann Bernoulli"],
["Daniel Bernoulli", "made major contributions to", "fluid dynamics"],
["Daniel Bernoulli", "made major contributions to", "probability"],
["Daniel Bernoulli", "made major contributions to", "statistics"],
["Daniel Bernoulli", "is most famous for", "Bernoulli’s principle"],
[
"Bernoulli’s principle",
"is fundamental to",
"the understanding of aerodynamics",
],
],
},
{
"passage": "Leonhard Euler (1707–1783) was one of the greatest mathematicians of all time, and his relationship with the Bernoulli family was significant. Euler was born in Basel and was a student of Johann Bernoulli, who recognized his exceptional talent and mentored him in mathematics. Johann Bernoulli’s influence on Euler was profound, and Euler later expanded upon many of the ideas and methods he learned from the Bernoullis.",
"triplets": [
[
"Leonhard Euler",
"had a significant relationship with",
"the Bernoulli family",
],
["leonhard Euler", "was born in", "Basel"],
["Leonhard Euler", "was a student of", "Johann Bernoulli"],
["Johann Bernoulli's influence", "was profound on", "Euler"],
],
},
]
엔티티와 관계는 다음과 같이 구성합니다:
- 엔티티는 삼중 항의 주어 또는 목적어이므로 삼중 항에서 직접 추출합니다.
- 여기서 우리는 주어, 서술어, 목적어를 공백을 사이에 두고 직접 연결하여 관계 개념을 구축합니다.
또한 나중에 사용할 수 있도록 엔티티 ID를 관계 ID에 매핑하는 딕셔너리와 관계 ID를 구절 ID에 매핑하는 또 다른 딕셔너리를 준비합니다.
entityid_2_relationids = defaultdict(list)
relationid_2_passageids = defaultdict(list)
entities = []
relations = []
passages = []
for passage_id, dataset_info in enumerate(nano_dataset):
passage, triplets = dataset_info["passage"], dataset_info["triplets"]
passages.append(passage)
for triplet in triplets:
if triplet[0] not in entities:
entities.append(triplet[0])
if triplet[2] not in entities:
entities.append(triplet[2])
relation = " ".join(triplet)
if relation not in relations:
relations.append(relation)
entityid_2_relationids[entities.index(triplet[0])].append(
len(relations) - 1
)
entityid_2_relationids[entities.index(triplet[2])].append(
len(relations) - 1
)
relationid_2_passageids[relations.index(relation)].append(passage_id)
데이터 삽입
엔티티, 관계 및 구절에 대한 Milvus 컬렉션을 만듭니다. 엔티티 컬렉션과 관계 컬렉션은 우리 방식에서 그래프 구성을 위한 주요 컬렉션으로 사용되며, 구절 컬렉션은 네이티브 RAG 검색 비교 또는 보조 목적으로 사용됩니다.
embedding_dim = len(embedding_model.embed_query("foo"))
def create_milvus_collection(collection_name: str):
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
consistency_level="Strong",
)
entity_col_name = "entity_collection"
relation_col_name = "relation_collection"
passage_col_name = "passage_collection"
create_milvus_collection(entity_col_name)
create_milvus_collection(relation_col_name)
create_milvus_collection(passage_col_name)
메타데이터 정보와 함께 데이터를 엔티티, 관계, 구절 컬렉션을 포함한 Milvus 컬렉션에 삽입합니다. 메타데이터 정보에는 통로 ID와 인접 엔티티 또는 관계 ID가 포함됩니다.
def milvus_insert(
collection_name: str,
text_list: list[str],
):
batch_size = 512
for row_id in tqdm(range(0, len(text_list), batch_size), desc="Inserting"):
batch_texts = text_list[row_id : row_id + batch_size]
batch_embeddings = embedding_model.embed_documents(batch_texts)
batch_ids = [row_id + j for j in range(len(batch_texts))]
batch_data = [
{
"id": id_,
"text": text,
"vector": vector,
}
for id_, text, vector in zip(batch_ids, batch_texts, batch_embeddings)
]
milvus_client.insert(
collection_name=collection_name,
data=batch_data,
)
milvus_insert(
collection_name=relation_col_name,
text_list=relations,
)
milvus_insert(
collection_name=entity_col_name,
text_list=entities,
)
milvus_insert(
collection_name=passage_col_name,
text_list=passages,
)
Inserting: 100%|███████████████████████████████████| 1/1 [00:00<00:00, 1.02it/s]
Inserting: 100%|███████████████████████████████████| 1/1 [00:00<00:00, 1.39it/s]
Inserting: 100%|███████████████████████████████████| 1/1 [00:00<00:00, 2.28it/s]
온라인 쿼리
유사성 검색
Milvus의 입력 쿼리를 기반으로 상위 K개의 유사한 개체 및 관계를 검색합니다.
엔티티 검색을 수행할 때는 먼저 NER(Named-entity recognition)과 같은 특정 방법을 사용하여 쿼리 텍스트에서 쿼리 엔티티를 추출해야 합니다. 간단하게 하기 위해 여기에서 NER 결과를 준비합니다. 쿼리를 사용자 지정 질문으로 변경하려면 해당 쿼리 NER 목록을 변경해야 합니다. 실제로는 다른 모델이나 접근 방식을 사용하여 쿼리에서 엔티티를 추출할 수 있습니다.
query = "What contribution did the son of Euler's teacher make?"
query_ner_list = ["Euler"]
# query_ner_list = ner(query) # In practice, replace it with your custom NER approach
query_ner_embeddings = [
embedding_model.embed_query(query_ner) for query_ner in query_ner_list
]
top_k = 3
entity_search_res = milvus_client.search(
collection_name=entity_col_name,
data=query_ner_embeddings,
limit=top_k,
output_fields=["id"],
)
query_embedding = embedding_model.embed_query(query)
relation_search_res = milvus_client.search(
collection_name=relation_col_name,
data=[query_embedding],
limit=top_k,
output_fields=["id"],
)[0]
하위 그래프 확장
검색된 엔티티와 관계를 사용하여 하위 그래프를 확장하고 후보 관계를 얻은 다음 두 가지 방법에서 병합합니다. 다음은 하위 그래프 확장 프로세스의 순서도입니다:
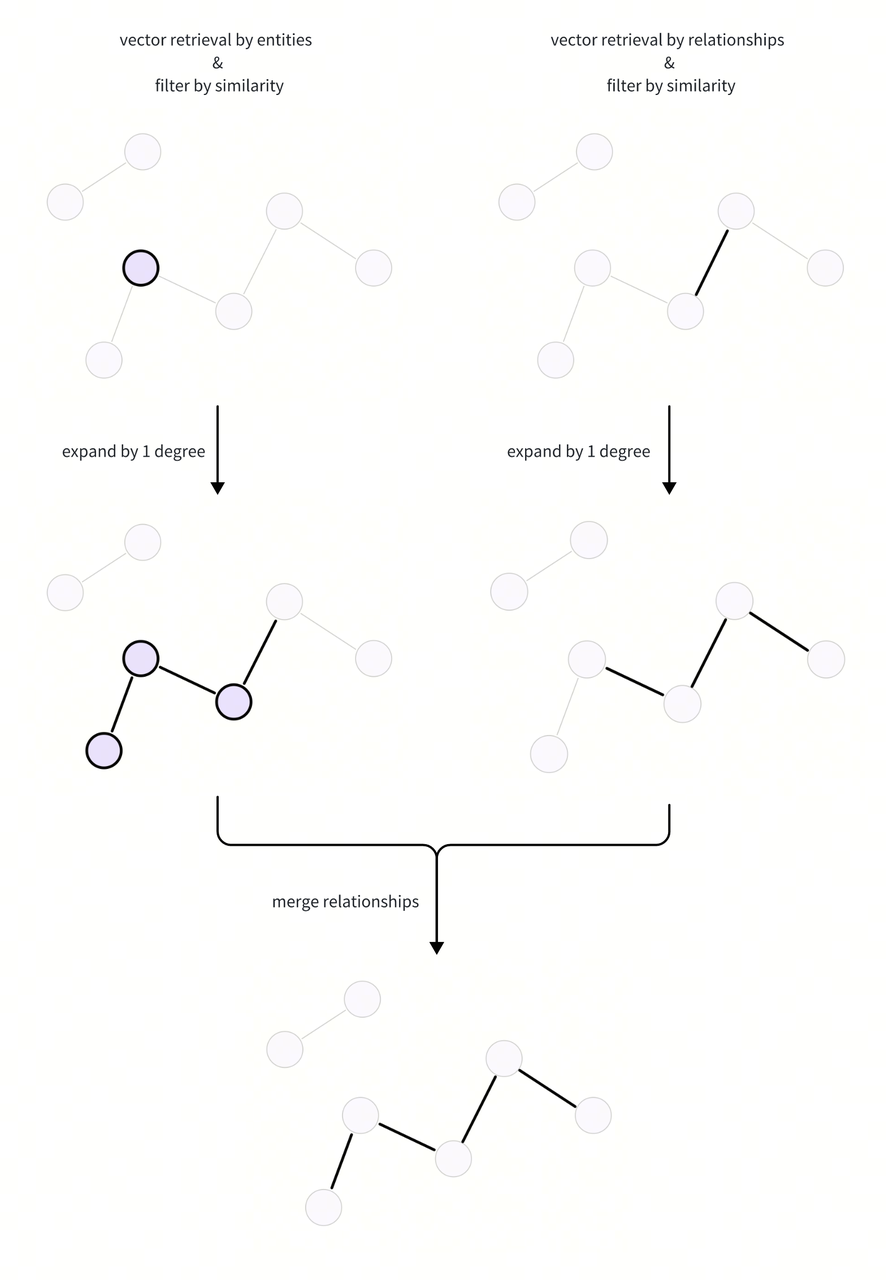
여기서 우리는 인접 행렬을 구성하고 행렬 곱셈을 사용하여 몇 도 이내의 인접 매핑 정보를 계산합니다. 이러한 방식으로 모든 확장 정도에 대한 정보를 빠르게 얻을 수 있습니다.
# Construct the adjacency matrix of entities and relations where the value of the adjacency matrix is 1 if an entity is related to a relation, otherwise 0.
entity_relation_adj = np.zeros((len(entities), len(relations)))
for entity_id, entity in enumerate(entities):
entity_relation_adj[entity_id, entityid_2_relationids[entity_id]] = 1
# Convert the adjacency matrix to a sparse matrix for efficient computation.
entity_relation_adj = csr_matrix(entity_relation_adj)
# Use the entity-relation adjacency matrix to construct 1 degree entity-entity and relation-relation adjacency matrices.
entity_adj_1_degree = entity_relation_adj @ entity_relation_adj.T
relation_adj_1_degree = entity_relation_adj.T @ entity_relation_adj
# Specify the target degree of the subgraph to be expanded.
# 1 or 2 is enough for most cases.
target_degree = 1
# Compute the target degree adjacency matrices using matrix multiplication.
entity_adj_target_degree = entity_adj_1_degree
for _ in range(target_degree - 1):
entity_adj_target_degree = entity_adj_target_degree * entity_adj_1_degree
relation_adj_target_degree = relation_adj_1_degree
for _ in range(target_degree - 1):
relation_adj_target_degree = relation_adj_target_degree * relation_adj_1_degree
entity_relation_adj_target_degree = entity_adj_target_degree @ entity_relation_adj
목표 차수 확장 행렬의 값을 가져와서 검색된 개체와 관계에서 해당 차수를 쉽게 확장하여 하위 그래프의 모든 관계를 얻을 수 있습니다.
expanded_relations_from_relation = set()
expanded_relations_from_entity = set()
# You can set the similarity threshold here to guarantee the quality of the retrieved ones.
# entity_sim_filter_thresh = ...
# relation_sim_filter_thresh = ...
filtered_hit_relation_ids = [
relation_res["entity"]["id"]
for relation_res in relation_search_res
# if relation_res['distance'] > relation_sim_filter_thresh
]
for hit_relation_id in filtered_hit_relation_ids:
expanded_relations_from_relation.update(
relation_adj_target_degree[hit_relation_id].nonzero()[1].tolist()
)
filtered_hit_entity_ids = [
one_entity_res["entity"]["id"]
for one_entity_search_res in entity_search_res
for one_entity_res in one_entity_search_res
# if one_entity_res['distance'] > entity_sim_filter_thresh
]
for filtered_hit_entity_id in filtered_hit_entity_ids:
expanded_relations_from_entity.update(
entity_relation_adj_target_degree[filtered_hit_entity_id].nonzero()[1].tolist()
)
# Merge the expanded relations from the relation and entity retrieval ways.
relation_candidate_ids = list(
expanded_relations_from_relation | expanded_relations_from_entity
)
relation_candidate_texts = [
relations[relation_id] for relation_id in relation_candidate_ids
]
하위 그래프를 확장하여 후보 관계를 얻었으며, 다음 단계에서는 LLM으로 순위를 다시 매깁니다.
LLM 재랭크
이 단계에서는 LLM의 강력한 셀프 어텐션 메커니즘을 배포하여 후보 관계 집합을 더욱 필터링하고 구체화합니다. 쿼리와 후보 관계 집합을 프롬프트에 통합하는 원샷 프롬프트를 사용하여 쿼리에 대한 답변에 도움이 될 수 있는 잠재적 관계를 선택하도록 LLM에 지시합니다. 일부 쿼리가 복잡할 수 있다는 점을 감안하여 연쇄적 사고 접근 방식을 채택하여 LLM이 응답에서 사고 과정을 명확하게 표현할 수 있도록 합니다. 편리한 구문 분석을 위해 LLM의 응답을 json 형식으로 규정하고 있습니다.
query_prompt_one_shot_input = """I will provide you with a list of relationship descriptions. Your task is to select 3 relationships that may be useful to answer the given question. Please return a JSON object containing your thought process and a list of the selected relationships in order of their relevance.
Question:
When was the mother of the leader of the Third Crusade born?
Relationship descriptions:
[1] Eleanor was born in 1122.
[2] Eleanor married King Louis VII of France.
[3] Eleanor was the Duchess of Aquitaine.
[4] Eleanor participated in the Second Crusade.
[5] Eleanor had eight children.
[6] Eleanor was married to Henry II of England.
[7] Eleanor was the mother of Richard the Lionheart.
[8] Richard the Lionheart was the King of England.
[9] Henry II was the father of Richard the Lionheart.
[10] Henry II was the King of England.
[11] Richard the Lionheart led the Third Crusade.
"""
query_prompt_one_shot_output = """{"thought_process": "To answer the question about the birth of the mother of the leader of the Third Crusade, I first need to identify who led the Third Crusade and then determine who his mother was. After identifying his mother, I can look for the relationship that mentions her birth.", "useful_relationships": ["[11] Richard the Lionheart led the Third Crusade", "[7] Eleanor was the mother of Richard the Lionheart", "[1] Eleanor was born in 1122"]}"""
query_prompt_template = """Question:
{question}
Relationship descriptions:
{relation_des_str}
"""
def rerank_relations(
query: str, relation_candidate_texts: list[str], relation_candidate_ids: list[str]
) -> list[int]:
relation_des_str = "\n".join(
map(
lambda item: f"[{item[0]}] {item[1]}",
zip(relation_candidate_ids, relation_candidate_texts),
)
).strip()
rerank_prompts = ChatPromptTemplate.from_messages(
[
HumanMessage(query_prompt_one_shot_input),
AIMessage(query_prompt_one_shot_output),
HumanMessagePromptTemplate.from_template(query_prompt_template),
]
)
rerank_chain = (
rerank_prompts
| llm.bind(response_format={"type": "json_object"})
| JsonOutputParser()
)
rerank_res = rerank_chain.invoke(
{"question": query, "relation_des_str": relation_des_str}
)
rerank_relation_ids = []
rerank_relation_lines = rerank_res["useful_relationships"]
id_2_lines = {}
for line in rerank_relation_lines:
id_ = int(line[line.find("[") + 1 : line.find("]")])
id_2_lines[id_] = line.strip()
rerank_relation_ids.append(id_)
return rerank_relation_ids
rerank_relation_ids = rerank_relations(
query,
relation_candidate_texts=relation_candidate_texts,
relation_candidate_ids=relation_candidate_ids,
)
최종 결과 가져오기
순위가 재지정된 관계에서 최종 검색된 구절을 얻을 수 있습니다.
final_top_k = 2
final_passages = []
final_passage_ids = []
for relation_id in rerank_relation_ids:
for passage_id in relationid_2_passageids[relation_id]:
if passage_id not in final_passage_ids:
final_passage_ids.append(passage_id)
final_passages.append(passages[passage_id])
passages_from_our_method = final_passages[:final_top_k]
구절 컬렉션에서 직접 쿼리 임베딩을 기반으로 상위 K개의 구절을 검색하는 나이브 RAG 메서드와 결과를 비교할 수 있습니다.
naive_passage_res = milvus_client.search(
collection_name=passage_col_name,
data=[query_embedding],
limit=final_top_k,
output_fields=["text"],
)[0]
passages_from_naive_rag = [res["entity"]["text"] for res in naive_passage_res]
print(
f"Passages retrieved from naive RAG: \n{passages_from_naive_rag}\n\n"
f"Passages retrieved from our method: \n{passages_from_our_method}\n\n"
)
prompt = ChatPromptTemplate.from_messages(
[
(
"human",
"""Use the following pieces of retrieved context to answer the question. If there is not enough information in the retrieved context to answer the question, just say that you don't know.
Question: {question}
Context: {context}
Answer:""",
)
]
)
rag_chain = prompt | llm | StrOutputParser()
answer_from_naive_rag = rag_chain.invoke(
{"question": query, "context": "\n".join(passages_from_naive_rag)}
)
answer_from_our_method = rag_chain.invoke(
{"question": query, "context": "\n".join(passages_from_our_method)}
)
print(
f"Answer from naive RAG: {answer_from_naive_rag}\n\nAnswer from our method: {answer_from_our_method}"
)
Passages retrieved from naive RAG:
['Leonhard Euler (1707–1783) was one of the greatest mathematicians of all time, and his relationship with the Bernoulli family was significant. Euler was born in Basel and was a student of Johann Bernoulli, who recognized his exceptional talent and mentored him in mathematics. Johann Bernoulli’s influence on Euler was profound, and Euler later expanded upon many of the ideas and methods he learned from the Bernoullis.', 'Johann Bernoulli (1667–1748): Johann, Jakob’s younger brother, was also a major figure in the development of calculus. He worked on infinitesimal calculus and was instrumental in spreading the ideas of Leibniz across Europe. Johann also contributed to the calculus of variations and was known for his work on the brachistochrone problem, which is the curve of fastest descent between two points.']
Passages retrieved from our method:
['Leonhard Euler (1707–1783) was one of the greatest mathematicians of all time, and his relationship with the Bernoulli family was significant. Euler was born in Basel and was a student of Johann Bernoulli, who recognized his exceptional talent and mentored him in mathematics. Johann Bernoulli’s influence on Euler was profound, and Euler later expanded upon many of the ideas and methods he learned from the Bernoullis.', 'Daniel Bernoulli (1700–1782): The son of Johann Bernoulli, Daniel made major contributions to fluid dynamics, probability, and statistics. He is most famous for Bernoulli’s principle, which describes the behavior of fluid flow and is fundamental to the understanding of aerodynamics.']
Answer from naive RAG: I don't know. The retrieved context does not provide information about the contributions made by the son of Euler's teacher.
Answer from our method: The son of Euler's teacher, Daniel Bernoulli, made major contributions to fluid dynamics, probability, and statistics. He is most famous for Bernoulli’s principle, which describes the behavior of fluid flow and is fundamental to the understanding of aerodynamics.
보시다시피, 나이브 RAG에서 검색된 구절은 사실에 근거한 구절을 놓쳐서 오답으로 이어졌지만, 우리 방식에서 검색된 구절은 정확하며 질문에 대한 정확한 답을 얻는 데 도움이 됩니다.