Reranking
Milvus enables hybrid search capabilities using the hybrid_search() API, incorporating sophisticated reranking strategies to refine search results from multiple AnnSearchRequest instances. This topic covers the reranking process, explaining its significance and implementation of different reranking strategies in Milvus.
Overview
The following figure illustrates the execution of a hybrid search in Milvus and highlights the role of reranking in the process.
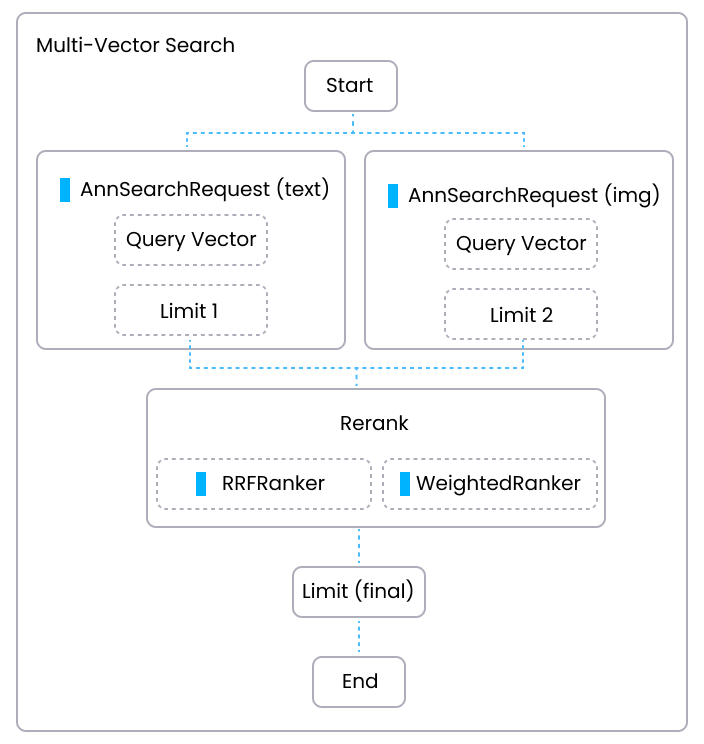
Reranking in hybrid search is a crucial step that consolidates results from several vector fields, ensuring the final output is relevant and accurately prioritized. Currently, Milvus offers these reranking strategies:
WeightedRanker: This approach merges results by calculating a weighted average of scores (or vector distances) from different vector searches. It assigns weights based on the significance of each vector field.RRFRanker: This strategy combines results based on their ranks across different vector columns.
Weighted Scoring (WeightedRanker)
The WeightedRanker strategy assigns different weights to results from each vector retrieval route based on the significance of each vector field. This reranking strategy is applied when the significance of each vector field varies, allowing you to emphasize certain vector fields over others by assigning them higher weights. For example, in a multimodal search, the text description might be considered more important than the color distribution in images.
WeightedRanker’s basic process is as follows:
Collect Scores During Retrieval: Gather results and their scores from different vector retrieval routes.
Score Normalization: Normalize the scores from each route to a [0,1] range, where values closer to 1 indicate higher relevance. This normalization is crucial due to score distributions varying with different metric types. For instance, the distance for IP ranges from [-∞,+∞], while the distance for L2 ranges from [0,+∞]. Milvus employs the
arctanfunction, transforming values to the [0,1] range to provide a standardized basis for different metric types.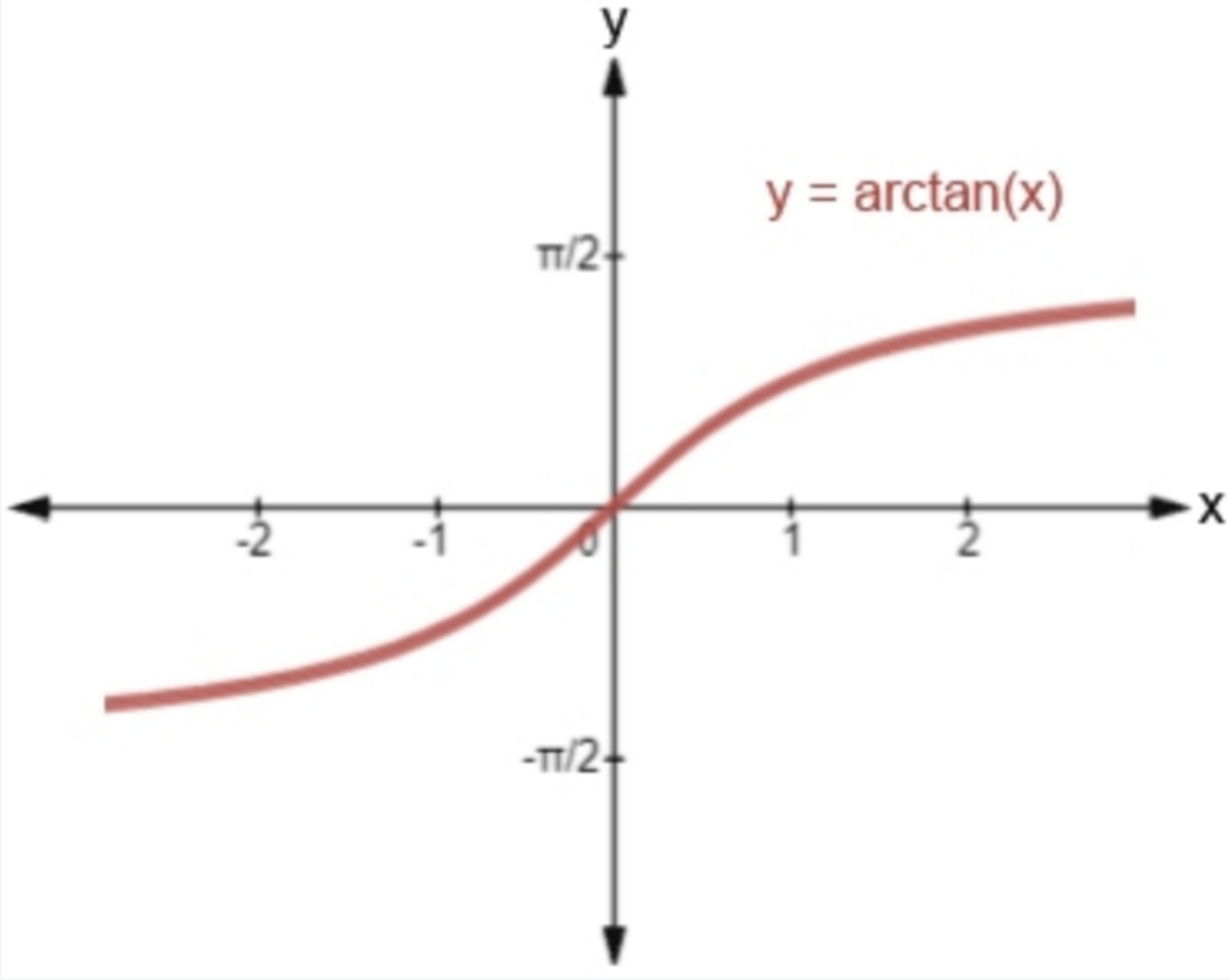
Weight Allocation: Assign a weight
w𝑖to each vector retrieval route. Users specify the weights, which reflect the data source’s reliability, accuracy, or other pertinent metrics. Each weight ranges from [0,1].Score Fusion: Calculate a weighted average of the normalized scores to derive the final score. The results are then ranked based on these highest to lowest scores to generate the final sorted results.
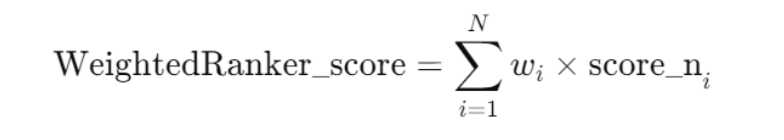 weighted-reranker
weighted-reranker
To use this strategy, apply a WeightedRanker instance and set weight values by passing in a variable number of numeric arguments.
from pymilvus import WeightedRanker
# Use WeightedRanker to combine results with specified weights
rerank = WeightedRanker(0.8, 0.8, 0.7)
Note that:
Each weight value ranges from 0 (least important) to 1 (most important), influencing the final aggregated score.
The total number of weight values provided in
WeightedRankershould equal the number ofAnnSearchRequestinstances you have created earlier.It is worth noting that due to the different measurements of the different metric types, we normalize the distances of the recall results so that they lie in the interval [0,1], where 0 means different and 1 means similar. The final score will be the sum of the weight values and distances.
Reciprocal Rank Fusion (RRFRanker)
RRF is a data fusion method that combines ranking lists based on the reciprocal of their ranks. It is an effective way to balance the influence of each vector field, especially when there is no clear precedence of importance. This strategy is typically used when you want to give equal consideration to all vector fields or when there is uncertainty about the relative importance of each field.
RRF’s basic process is as follows:
Collect Rankings During Retrieval: Retrievers across multiple vector fields retrieve and sort results.
Rank Fusion: The RRF algorithm weighs and combines the ranks from each retriever. The formula is as follows:
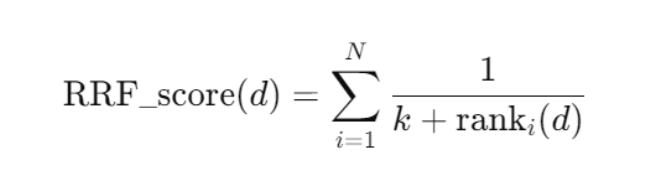 rrf-ranker
rrf-ranker
Here, 𝑁 represents the number of different retrieval routes, rank𝑖(𝑑) is the rank position of retrieved document 𝑑 by the 𝑖th retriever, and 𝑘 is a smoothing parameter, typically set to 60.
Comprehensive Ranking: Re-rank the retrieved results based on the combined scores to produce the final results.
To use this strategy, apply an RRFRanker instance.
from pymilvus import RRFRanker
# Default k value is 60
ranker = RRFRanker()
# Or specify k value
ranker = RRFRanker(k=100)
RRF allows balancing influence across fields without specifying explicit weights. The top matches agreed upon by multiple fields will be prioritized in the final ranking.