Schema Explained
A schema defines the data structure of a collection. Before creating a collection, you need to work out a design of its schema. This page helps you understand the collection schema and design an example schema on your own.
Overview
On Milvus, a collection schema assembles a table in a relational database, which defines how Milvus organizes data in the collection.
A well-designed schema is essential as it abstracts the data model and decides if you can achieve the business objectives through a search. Furthermore, since every row of data inserted into the collection must follow the schema, it helps maintain data consistency and long-term quality. From a technical perspective, a well-defined schema leads to well-organized column data storage and a cleaner index structure, boosting search performance.
A collection schema has a primary key, at least one vector field, and several scalar fields. The following diagram illustrates how to map an article to a list of schema fields.
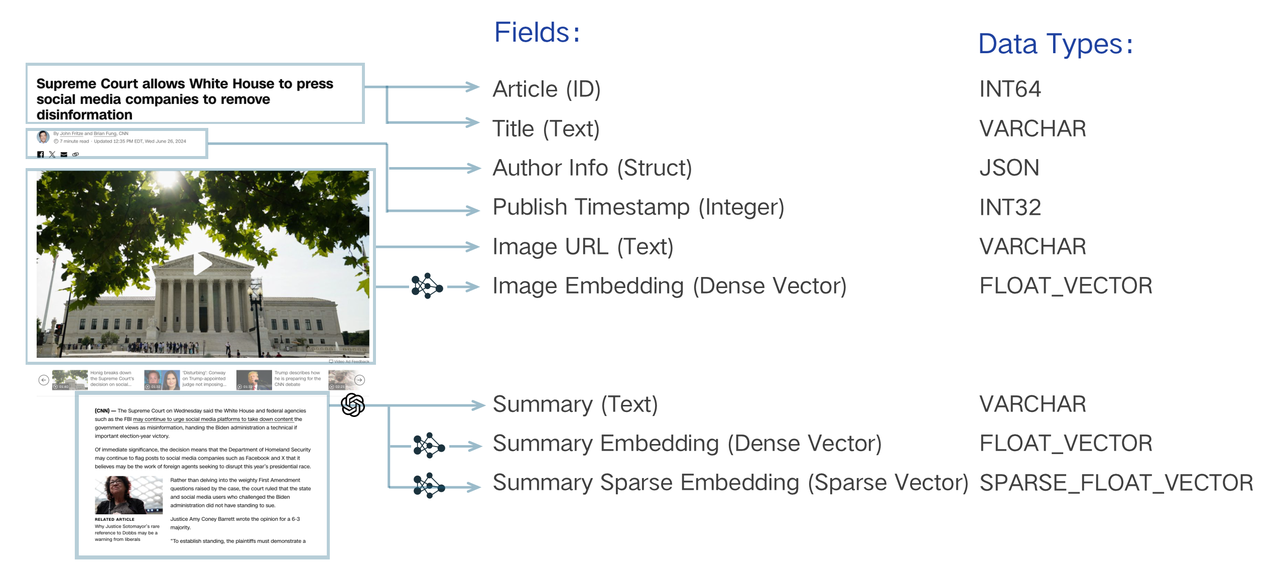 Schema Design Anatomy
Schema Design Anatomy
The data model design of a search system involves analyzing business needs and abstracting information into a schema-expressed data model. For instance, searching a piece of text must be “indexed” by converting the literal string into a vector through “embedding” and enabling vector search. Beyond this essential requirement, storing other properties such as publication timestamp and author may be necessary. This metadata allows for semantic searches to be refined through filtering, returning only texts published after a specific date or by a particular author. You can also retrieve these scalars with the main text to render the search result in the application. Each should be assigned a unique identifier to organize these text pieces, expressed as an integer or string. These elements are essential for achieving sophisticated search logic.
Refer to Schema Design Hands-On to figure out how to make a well-designed schema.
Create Schema
The following code snippet demonstrates how to create a schema.
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const schema = []
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
export schema='{
"fields": []
}'
Add Primary Field
The primary field in a collection uniquely identifies an entity. It only accepts Int64 or VarChar values. The following code snippets demonstrate how to add the primary field.
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("my_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.push({
name: "my_id",
data_type: DataType.Int64,
is_primary_key: true,
autoID: false
});
schema.WithField(entity.NewField().WithName("my_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(false),
)
export primaryField='{
"fieldName": "my_id",
"dataType": "Int64",
"isPrimary": true
}'
export schema='{
\"autoID\": false,
\"fields\": [
$primaryField
]
}'
When adding a field, you can explicitly clarify the field as the primary field by setting its is_primary property to True. A primary field accepts Int64 values by default. In this case, the primary field value should be integers similar to 12345. If you choose to use VarChar values in the primary field, the value should be strings similar to my_entity_1234.
You can also set the autoId properties to True to make Milvus automatically allocate primary field values upon data insertions.
You are advised to rely on autoId in all cases unless manually setting primary keys is beneficial.
For details, refer to Primary Field & AutoId.
Add Vector Fields
Vector fields accept various sparse and dense vector embeddings. On Milvus, you can add four vector fields to a collection. The following code snippets demonstrate how to add a vector field.
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
schema.addField(AddFieldReq.builder()
.fieldName("my_vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.push({
name: "my_vector",
data_type: DataType.FloatVector,
dim: 5
});
schema.WithField(entity.NewField().WithName("my_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
export vectorField='{
"fieldName": "my_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField
]
}"
The dim paramter in the above code snippets indicates the dimensionality of the vector embeddings to be held in the vector field. The FLOAT_VECTOR value indicates that the vector field holds a list of 32-bit floating numbers, which are usually used to represent antilogarithms.In addition to that, Milvus also supports the following types of vector embeddings:
FLOAT16_VECTORA vector field of this type holds a list of 16-bit half-precision floating numbers and usually applies to memory- or bandwidth-restricted deep learning or GPU-based computing scenarios.
BFLOAT16_VECTORA vector field of this type holds a list of 16-bit floating-point numbers that have reduced precision but the same exponent range as Float32. This type of data is commonly used in deep learning scenarios, as it reduces memory usage without significantly impacting accuracy.
INT8_VECTORA vector field of this type stores vectors composed of 8-bit signed integers (int8), with each component ranging from –128 to 127. Tailored for quantized deep learning architectures—such as ResNet and EfficientNet—it substantially shrinks model size and boosts inference speed, all while incurring only minimal precision loss. Note: This vector type is supported only for HNSW indexes.
BINARY_VECTORA vector field of this type holds a list of 0s and 1s. They serve as compact features for representing data in image processing and information retrieval scenarios.
SPARSE_FLOAT_VECTORA vector field of this type holds a list of non-zero numbers and their sequence numbers to represent sparse vector embeddings.
Add Scalar Fields
In common cases, you can use scalar fields to store the metadata of the vector embeddings stored in Milvus, and conduct ANN searches with metadata filtering to improve the correctness of the search results. Milvus supports multiple scalar field types, including VarChar, Boolean, Int, Float, and Double.
Add String Fields
In Milvus, you can use VarChar fields to store strings. For more on the VarChar field, refer to String Field.
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512
)
schema.addField(AddFieldReq.builder()
.fieldName("my_varchar")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
schema.push({
name: "my_varchar",
data_type: DataType.VarChar,
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_varchar").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
export varCharField='{
"fieldName": "my_varchar",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField
]
}"
Add Number Fields
The types of numbers that Milvus supports are Int8, Int16, Int32, Int64, Float, and Double. For more on the number fields, refer to Number Field.
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_int64")
.dataType(DataType.Int64)
.build());
schema.push({
name: "my_int64",
data_type: DataType.Int64,
});
schema.WithField(entity.NewField().WithName("my_int64").
WithDataType(entity.FieldTypeInt64),
)
export int64Field='{
"fieldName": "my_int64",
"dataType": "Int64"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field
]
}"
Add Boolean Fields
Milvus supports boolean fields. The following code snippets demonstrate how to add a boolean field.
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_bool")
.dataType(DataType.Bool)
.build());
schema.push({
name: "my_bool",
data_type: DataType.Boolean,
});
schema.WithField(entity.NewField().WithName("my_bool").
WithDataType(entity.FieldTypeBool),
)
export boolField='{
"fieldName": "my_bool",
"dataType": "Boolean"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField
]
}"
Add Composite Fields
In Milvus, a composite field is a field that can be divided into smaller sub-fields, such as the keys in a JSON field or the indices in an Array field.
Add JSON fields
A JSON field usually stores half-structured JSON data. For more on the JSON fields, refer to JSON Field.
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_json")
.dataType(DataType.JSON)
.build());
schema.push({
name: "my_json",
data_type: DataType.JSON,
});
schema.WithField(entity.NewField().WithName("my_json").
WithDataType(entity.FieldTypeJSON),
)
export jsonField='{
"fieldName": "my_json",
"dataType": "JSON"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField
]
}"
Add Array Fields
An array field stores a list of elements. The data types of all elements in an array field should be the same. For more on the array fields, refer to Array Field.
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_array")
.dataType(DataType.Array)
.elementType(DataType.VarChar)
.maxCapacity(5)
.maxLength(512)
.build());
schema.push({
name: "my_array",
data_type: DataType.Array,
element_type: DataType.VarChar,
max_capacity: 5,
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_array").
WithDataType(entity.FieldTypeArray).
WithElementType(entity.FieldTypeInt64).
WithMaxLength(512).
WithMaxCapacity(5),
)
export arrayField='{
"fieldName": "my_array",
"dataType": "Array",
"elementDataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField,
$arrayField
]
}"