Raggruppamento HDBSCAN con Milvus
![]()
I dati possono essere trasformati in embeddings utilizzando modelli di deep learning, che catturano rappresentazioni significative dei dati originali. Applicando un algoritmo di clustering non supervisionato, possiamo raggruppare punti di dati simili in base ai loro modelli intrinseci. HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) è un algoritmo di clustering ampiamente utilizzato che raggruppa in modo efficiente i punti di dati analizzandone la densità e la distanza. È particolarmente utile per scoprire cluster di forme e dimensioni diverse. In questo quaderno utilizzeremo HDBSCAN con Milvus, un database vettoriale ad alte prestazioni, per raggruppare i punti di dati in gruppi distinti in base alle loro incorporazioni.
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) è un algoritmo di clustering che si basa sul calcolo delle distanze tra i punti di dati nello spazio delle incorporazioni. Questi embeddings, creati da modelli di deep learning, rappresentano i dati in forma altamente dimensionale. Per raggruppare punti di dati simili, HDBSCAN ne determina la vicinanza e la densità, ma il calcolo efficiente di queste distanze, soprattutto per i grandi insiemi di dati, può essere impegnativo.
Milvus, un database vettoriale ad alte prestazioni, ottimizza questo processo memorizzando e indicizzando le incorporazioni, consentendo un rapido recupero di vettori simili. Se utilizzati insieme, HDBSCAN e Milvus consentono di raggruppare in modo efficiente insiemi di dati di grandi dimensioni nello spazio delle incorporazioni.
In questo notebook, utilizzeremo il modello di embedding BGE-M3 per estrarre gli embedding da un set di dati di notizie, utilizzeremo Milvus per calcolare in modo efficiente le distanze tra gli embedding per aiutare HDBSCAN nel clustering e quindi visualizzeremo i risultati per l'analisi con il metodo UMAP. Questo quaderno è un adattamento Milvus dell'articolo di Dylan Castillo.
Preparazione
scaricare il set di dati delle notizie da https://www.kaggle.com/datasets/dylanjcastillo/news-headlines-2024/
$ pip install "pymilvus[model]"
$ pip install hdbscan
$ pip install plotly
$ pip install umap-learn
Scaricare i dati
Scaricare il dataset di notizie da https://www.kaggle.com/datasets/dylanjcastillo/news-headlines-2024/, estrarre news_data_dedup.csv e metterlo nella directory corrente.
Estrarre gli embeddings in Milvus
Creeremo una raccolta utilizzando Milvus ed estrarremo le incorporazioni dense utilizzando il modello BGE-M3.
import pandas as pd
from dotenv import load_dotenv
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
from pymilvus import FieldSchema, Collection, connections, CollectionSchema, DataType
load_dotenv()
df = pd.read_csv("news_data_dedup.csv")
docs = [
f"{title}\n{description}" for title, description in zip(df.title, df.description)
]
ef = BGEM3EmbeddingFunction()
embeddings = ef(docs)["dense"]
connections.connect(uri="milvus.db")
- Se si ha bisogno di un database vettoriale locale solo per dati su piccola scala o per la prototipazione, impostare l'uri come file locale, ad esempio
./milvus.db, è il metodo più conveniente, poiché utilizza automaticamente Milvus Lite per memorizzare tutti i dati in questo file. - Se si dispone di una grande quantità di dati, ad esempio più di un milione di vettori, è possibile configurare un server Milvus più performante su Docker o Kubernetes. In questa configurazione, utilizzare l'indirizzo e la porta del server come uri, ad esempio
http://localhost:19530. Se si attiva la funzione di autenticazione su Milvus, utilizzare "<nome_utente>:<password>" come token, altrimenti non impostare il token. - Se si utilizza Zilliz Cloud, il servizio cloud completamente gestito per Milvus, impostare
urietoken, che corrispondono all'endpoint pubblico e alla chiave API di Zilliz Cloud.
fields = [
FieldSchema(
name="id", dtype=DataType.INT64, is_primary=True, auto_id=True
), # Primary ID field
FieldSchema(
name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024
), # Float vector field (embedding)
FieldSchema(
name="text", dtype=DataType.VARCHAR, max_length=65535
), # Float vector field (embedding)
]
schema = CollectionSchema(fields=fields, description="Embedding collection")
collection = Collection(name="news_data", schema=schema)
for doc, embedding in zip(docs, embeddings):
collection.insert({"text": doc, "embedding": embedding})
print(doc)
index_params = {"index_type": "FLAT", "metric_type": "L2", "params": {}}
collection.create_index(field_name="embedding", index_params=index_params)
collection.flush()
Costruire la matrice di distanza per HDBSCAN
HDBSCAN richiede il calcolo delle distanze tra i punti per il clustering, che può essere computazionalmente intenso. Poiché i punti distanti hanno una minore influenza sull'assegnazione dei cluster, è possibile migliorare l'efficienza calcolando i top-k vicini. In questo esempio, utilizziamo l'indice FLAT, ma per i dataset di grandi dimensioni, Milvus supporta metodi di indicizzazione più avanzati per accelerare il processo di ricerca. Per prima cosa, dobbiamo ottenere un iteratore per iterare la collezione Milvus creata in precedenza.
import hdbscan
import numpy as np
import pandas as pd
import plotly.express as px
from umap import UMAP
from pymilvus import Collection
collection = Collection(name="news_data")
collection.load()
iterator = collection.query_iterator(
batch_size=10, expr="id > 0", output_fields=["id", "embedding"]
)
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10},
} # L2 is Euclidean distance
ids = []
dist = {}
embeddings = []
Si itereranno tutte le incorporazioni presenti nella collezione Milvus. Per ogni incorporamento, cercheremo i suoi vicini top-k nella stessa collezione, ottenendo i loro id e le loro distanze. Poi dobbiamo anche costruire un dizionario per mappare l'ID originale a un indice continuo nella matrice delle distanze. Al termine, dobbiamo creare una matrice di distanza inizializzata con tutti gli elementi all'infinito e riempire gli elementi cercati. In questo modo, la distanza tra punti lontani sarà ignorata. Infine, utilizziamo la libreria HDBSCAN per raggruppare i punti utilizzando la matrice di distanza creata. È necessario impostare la metrica su 'precomputed' per indicare che i dati sono matrici di distanza piuttosto che embeddings originali.
while True:
batch = iterator.next()
batch_ids = [data["id"] for data in batch]
ids.extend(batch_ids)
query_vectors = [data["embedding"] for data in batch]
embeddings.extend(query_vectors)
results = collection.search(
data=query_vectors,
limit=50,
anns_field="embedding",
param=search_params,
output_fields=["id"],
)
for i, batch_id in enumerate(batch_ids):
dist[batch_id] = []
for result in results[i]:
dist[batch_id].append((result.id, result.distance))
if len(batch) == 0:
break
ids2index = {}
for id in dist:
ids2index[id] = len(ids2index)
dist_metric = np.full((len(ids), len(ids)), np.inf, dtype=np.float64)
for id in dist:
for result in dist[id]:
dist_metric[ids2index[id]][ids2index[result[0]]] = result[1]
h = hdbscan.HDBSCAN(min_samples=3, min_cluster_size=3, metric="precomputed")
hdb = h.fit(dist_metric)
Al termine di questa operazione, il clustering HDBSCAN è terminato. È possibile ottenere alcuni dati e mostrarne il cluster. Si noti che alcuni dati non saranno assegnati a nessun cluster, il che significa che sono rumore, perché sono situati in una regione rada.
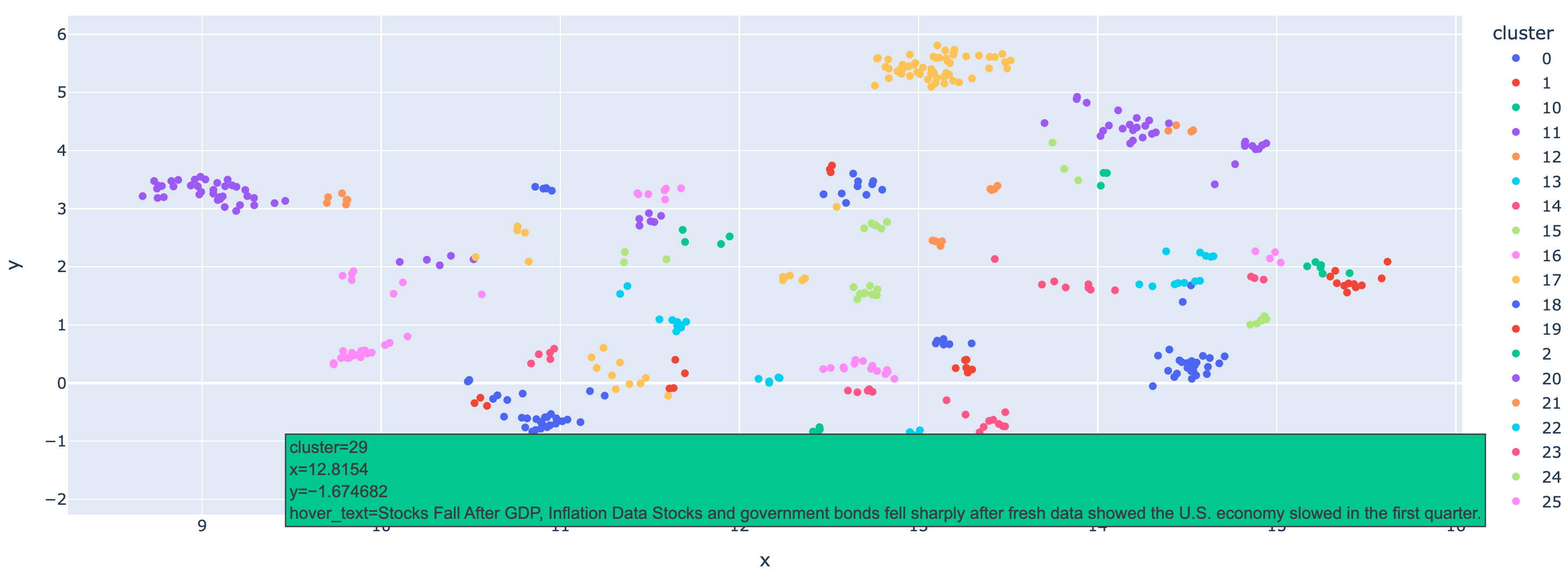
Visualizzazione dei cluster con UMAP
Abbiamo già clusterizzato i dati usando HDBSCAN e possiamo ottenere le etichette per ogni punto dati. Tuttavia, utilizzando alcune tecniche di visualizzazione, possiamo ottenere l'immagine completa dei cluster per un'analisi intuitiva. Ora utilizzeremo UMAP per visualizzare i cluster. UMAP è un metodo efficiente utilizzato per la riduzione della dimensionalità, che preserva la struttura dei dati ad alta densità proiettandoli in uno spazio a bassa densità per la visualizzazione o l'analisi successiva. Anche in questo caso, iteriamo i punti di dati e otteniamo l'id e il testo dei dati originali, quindi usiamo ploty per tracciare i punti di dati con questi metainfo in una figura e usiamo colori diversi per rappresentare i diversi cluster.
import plotly.io as pio
pio.renderers.default = "notebook"
umap = UMAP(n_components=2, random_state=42, n_neighbors=80, min_dist=0.1)
df_umap = (
pd.DataFrame(umap.fit_transform(np.array(embeddings)), columns=["x", "y"])
.assign(cluster=lambda df: hdb.labels_.astype(str))
.query('cluster != "-1"')
.sort_values(by="cluster")
)
iterator = collection.query_iterator(
batch_size=10, expr="id > 0", output_fields=["id", "text"]
)
ids = []
texts = []
while True:
batch = iterator.next()
if len(batch) == 0:
break
batch_ids = [data["id"] for data in batch]
batch_texts = [data["text"] for data in batch]
ids.extend(batch_ids)
texts.extend(batch_texts)
show_texts = [texts[i] for i in df_umap.index]
df_umap["hover_text"] = show_texts
fig = px.scatter(
df_umap, x="x", y="y", color="cluster", hover_data={"hover_text": True}
)
fig.show()
 immagine
immagine
Qui dimostriamo che i dati sono ben raggruppati e che è possibile passare il mouse sui punti per controllare il testo che rappresentano. Con questo quaderno speriamo che impariate a usare HDBSCAN per clusterizzare in modo efficiente gli embeddings con Milvus, che può essere applicato anche ad altri tipi di dati. Combinato con modelli linguistici di grandi dimensioni, questo approccio consente un'analisi più approfondita dei dati su larga scala.