Utilizzare Milvus con SambaNova
SambaNova è una piattaforma tecnologica AI innovativa che accelera l'implementazione di funzionalità avanzate di AI e deep learning. Progettata per l'uso aziendale, consente alle organizzazioni di sfruttare l'AI generativa per migliorare le prestazioni e l'efficienza. Fornendo soluzioni all'avanguardia come SambaNova Suite e DataScale, la piattaforma consente alle aziende di estrarre informazioni preziose dai propri dati, migliorando le operazioni e promuovendo nuove opportunità nel panorama dell'AI.
I SambaNova AI Starter Kit sono una raccolta di risorse open-source progettate per assistere sviluppatori e aziende nell'implementazione di applicazioni AI con SambaNova. Questi kit forniscono esempi pratici e guide che facilitano l'implementazione di vari casi d'uso dell'AI, rendendo più facile per gli utenti sfruttare la tecnologia avanzata di SambaNova.
Questo tutorial sfrutta l'integrazione di Milvus negli Starter Kit AI di SambaNova per costruire un sistema di Enterprise Knowledge Retrieval, simile a RAG (Retrieval-Augmented Generation), per il reperimento e la risposta sulla base dei documenti privati aziendali.
Questo tutorial fa principalmente riferimento alla guida ufficiale di SambaNova AI Starter Kits. Se ritenete che questo tutorial abbia parti obsolete, potete seguire prioritariamente la guida ufficiale e creare un problema con noi.
Prerequisiti
Si consiglia di utilizzare Python >= 3.10 e < 3.12.
Visitare il SambaNova Cloud per ottenere una chiave API SambaNova.
Clonare il repository
$ git clone https://github.com/sambanova/ai-starter-kit.git
$ d ai-starter-kit/enterprise_knowledge_retriever
Cambiare il tipo di archivio vettoriale
Cambiare l'archivio vettoriale impostando db_type='milvus' nelle funzioni create_vector_store() e load_vdb() in src/document_retrieval.py.
...
vectorstore = self.vectordb.create_vector_store(
..., db_type='milvus'
)
...
vectorstore = self.vectordb.load_vdb(..., db_type='milvus', ...)
Installare le dipendenze
Installare le dipendenze necessarie eseguendo il seguente comando:
python3 -m venv enterprise_knowledge_env
source enterprise_knowledge_env/bin/activate
pip install -r requirements.txt
Avviare l'applicazione
Utilizzare il seguente comando per avviare l'applicazione:
$ streamlit run streamlit/app.py --browser.gatherUsageStats false
Successivamente, viene visualizzata l'interfaccia utente nel browser:http://localhost:8501/
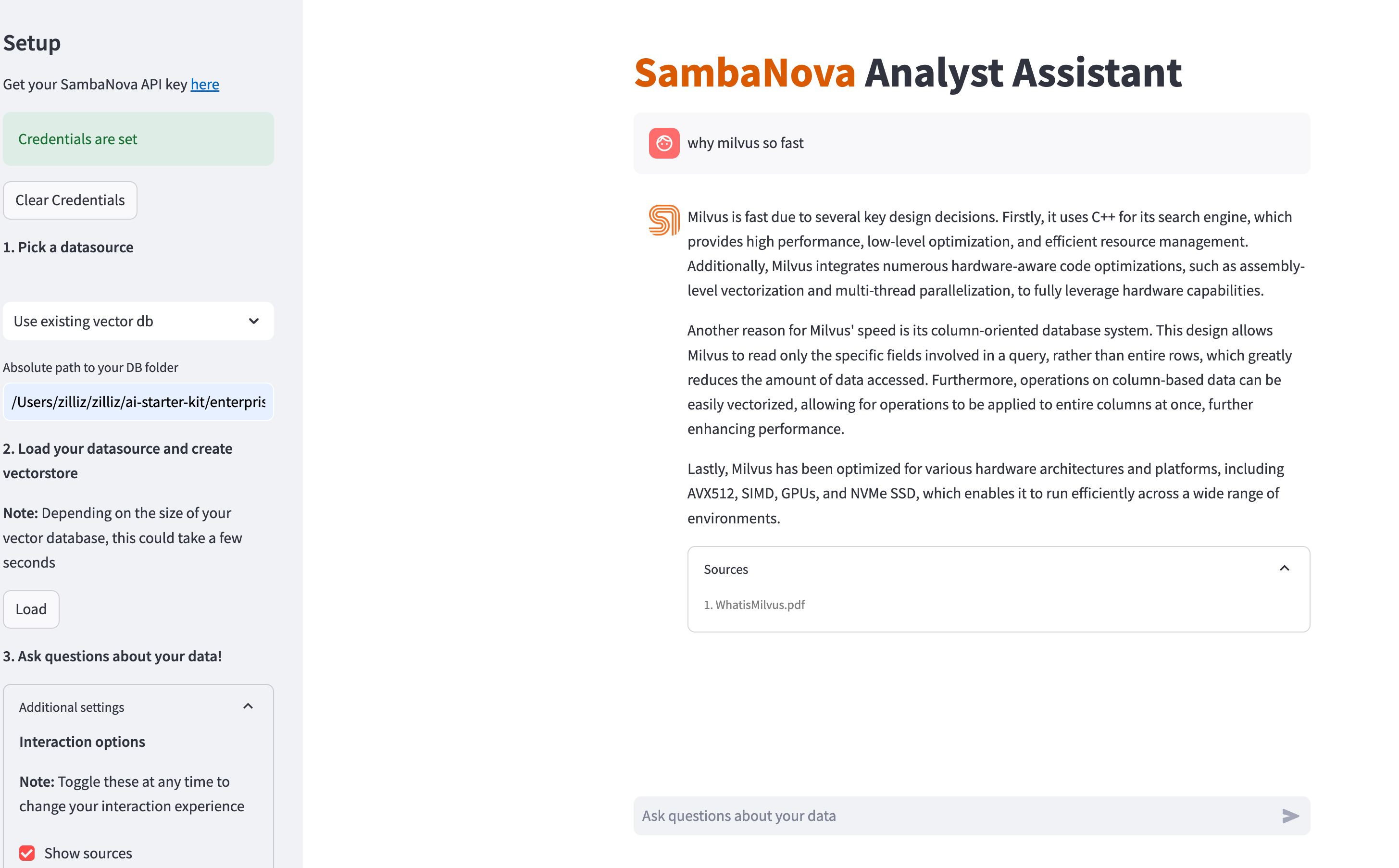
Dopo aver impostato la chiave API SambaNova nell'interfaccia utente, è possibile giocare con l'interfaccia utente e porre domande sui documenti.
Per ulteriori dettagli, consultare la documentazione ufficiale di Enterprise Knowledge Retrieval of SambaNova AI Starter Kits.