FAQ sulle prestazioni
Come impostare nlist e nprobe per gli indici FIV?
L'impostazione di nlist è specifica dello scenario. Come regola generale, il valore consigliato di nlist è 4 × sqrt(n), dove n è il numero totale di entità in un segmento.
La dimensione di ogni segmento è determinata dal parametro datacoord.segment.maxSize, che per impostazione predefinita è di 512 MB. Il numero totale di entità in un segmento n può essere stimato dividendo datacoord.segment.maxSize per la dimensione di ciascuna entità.
L'impostazione di nprobe è specifica per il set di dati e lo scenario e comporta un compromesso tra accuratezza e prestazioni della query. Si consiglia di trovare il valore ideale attraverso ripetute sperimentazioni.
I grafici seguenti sono i risultati di un test eseguito sul dataset sift50m e sull'indice IVF_SQ8, che mette a confronto il richiamo e le prestazioni delle query di diverse coppie nlist/nprobe.
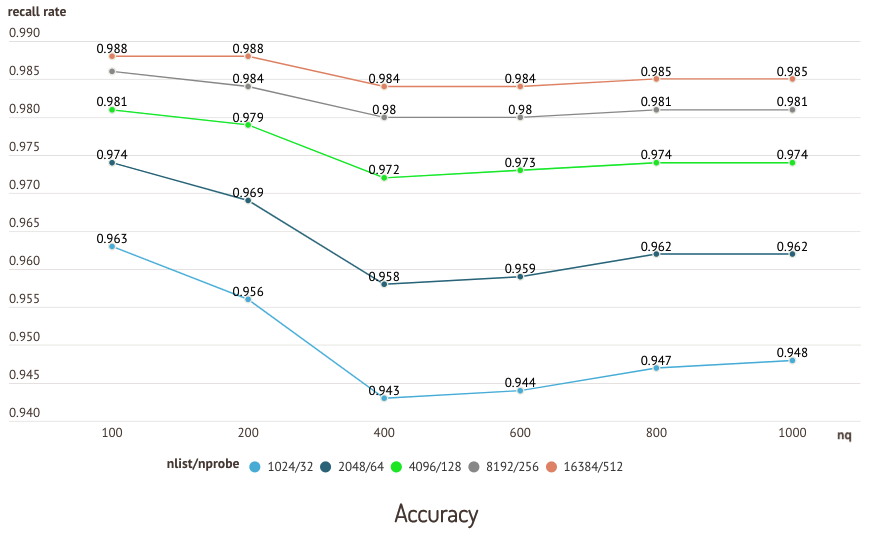 Test di accuratezza
Test di accuratezza 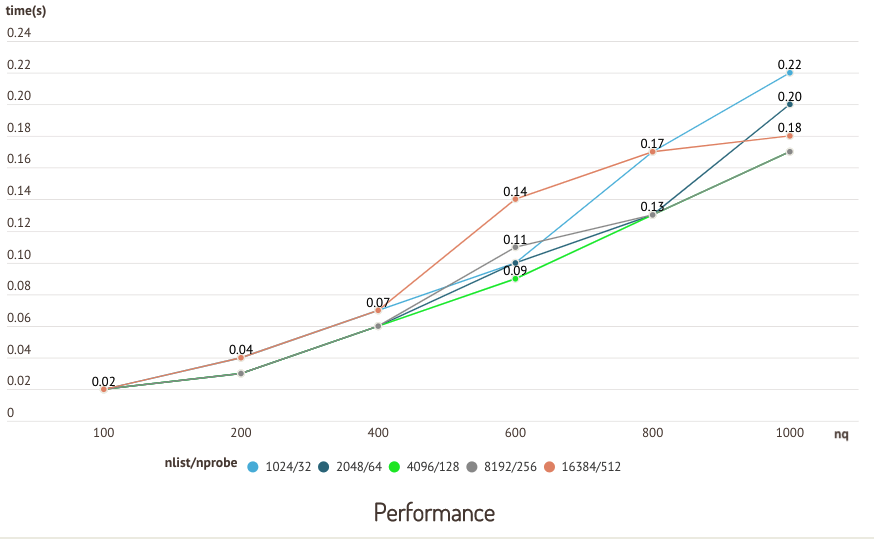 Test di performance
Test di performance
Perché le query a volte richiedono più tempo su dataset più piccoli?
Le operazioni di query vengono eseguite su segmenti. Gli indici riducono il tempo necessario per interrogare un segmento. Se un segmento non è stato indicizzato, Milvus ricorre alla ricerca bruta sui dati grezzi, aumentando drasticamente il tempo di interrogazione.
Di conseguenza, di solito ci vuole più tempo per interrogare un piccolo insieme di dati (collezione) perché non è stato costruito un indice. Questo perché le dimensioni dei segmenti non hanno raggiunto la soglia di costruzione dell'indice impostata da rootCoord.minSegmentSizeToEnableindex. Chiamare create_index() per forzare Milvus a indicizzare i segmenti che hanno raggiunto la soglia ma non sono ancora stati indicizzati automaticamente, migliorando significativamente le prestazioni delle query.
Quali fattori influiscono sull'utilizzo della CPU?
L'uso della CPU aumenta quando Milvus costruisce indici o esegue query. In generale, la creazione di indici è intensiva per la CPU, tranne quando si utilizza Annoy, che viene eseguito su un singolo thread.
Durante l'esecuzione delle query, l'utilizzo della CPU è influenzato da nq e nprobe. Quando nq e nprobe sono piccoli, la concorrenza è bassa e l'uso della CPU rimane basso.
L'inserimento simultaneo di dati e la ricerca hanno un impatto sulle prestazioni delle query?
Le operazioni di inserimento non sono intensive per la CPU. Tuttavia, poiché i nuovi segmenti potrebbero non aver raggiunto la soglia per la creazione dell'indice, Milvus ricorre alla ricerca bruta, con un impatto significativo sulle prestazioni della query.
Il parametro rootcoord.minSegmentSizeToEnableIndex determina la soglia di costruzione dell'indice per un segmento ed è impostato su 1024 righe per impostazione predefinita. Per ulteriori informazioni, vedere Configurazione del sistema.
L'indicizzazione di un campo VARCHAR può migliorare la velocità di cancellazione?
L'indicizzazione di un campo VARCHAR può accelerare le operazioni di "Elimina per espressione", ma solo a determinate condizioni:
- Indice INVERTITO: Questo indice è utile per le espressioni
INo==sui campi VARCHAR a chiave non primaria. - Indice Trie: Questo indice è utile per le query con prefisso (ad esempio,
LIKE prefix%) su campi VARCHAR non primari.
Tuttavia, l'indicizzazione di un campo VARCHAR non è più veloce:
- Eliminazione per ID: Quando il campo VARCHAR è la chiave primaria.
- Espressioni non correlate: Quando il campo VARCHAR non fa parte dell'espressione di eliminazione.
Avete ancora domande?
È possibile:
- Consultare Milvus su GitHub. Sentitevi liberi di fare domande, condividere idee e aiutare gli altri.
- Unitevi al nostro canale Discord per trovare supporto e partecipare alla nostra comunità open-source.