FAQ sur les performances
Comment définir nlist et nprobe pour les index FIV ?
La définition de nlist dépend du scénario. En règle générale, la valeur recommandée pour nlist est 4 × sqrt(n), où n est le nombre total d'entités dans un segment.
La taille de chaque segment est déterminée par le paramètre datacoord.segment.maxSize, qui est fixé par défaut à 512 Mo. Le nombre total d'entités dans un segment n peut être estimé en divisant datacoord.segment.maxSize par la taille de chaque entité.
Le réglage de nprobe est spécifique à l'ensemble de données et au scénario, et implique un compromis entre la précision et les performances de la requête. Nous recommandons de trouver la valeur idéale par le biais d'expériences répétées.
Les graphiques suivants sont les résultats d'un test effectué sur l'ensemble de données sift50m et l'index IVF_SQ8, qui compare les performances de rappel et de requête de différentes paires nlist/nprobe.
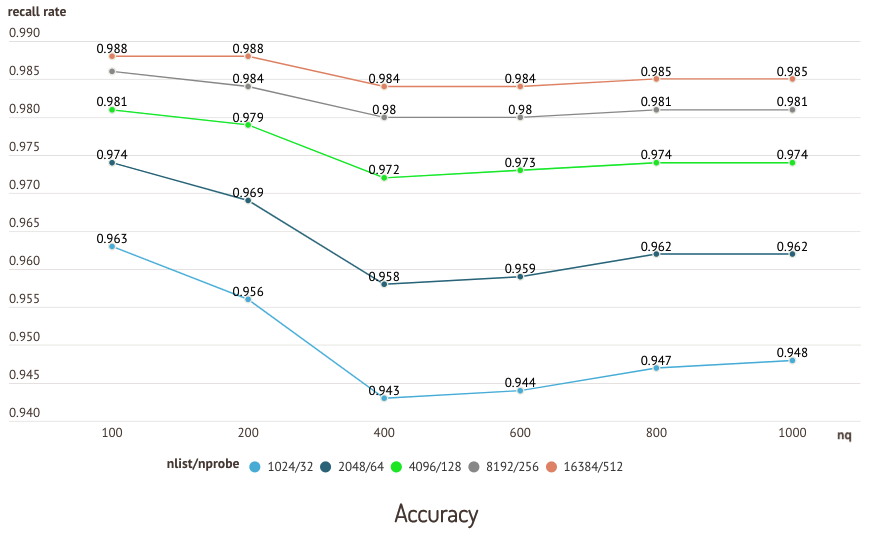 Test de précision
Test de précision 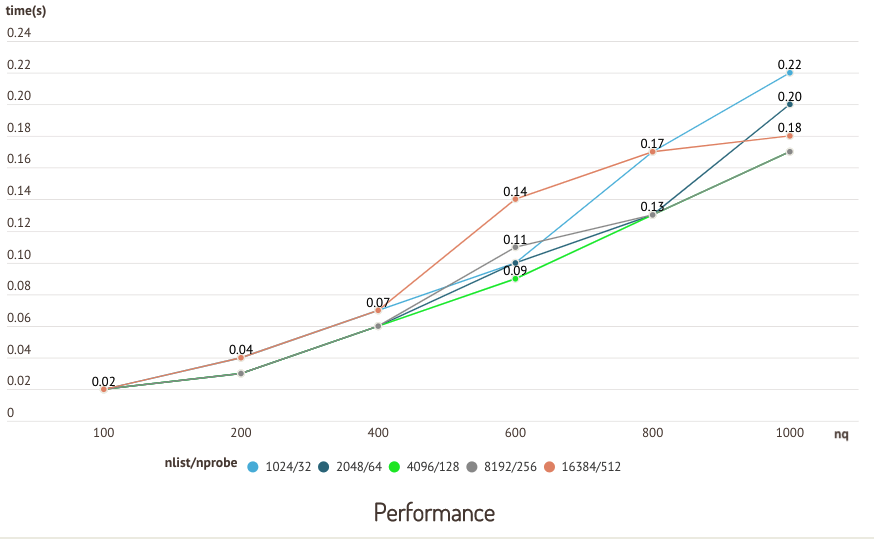 Test de performance
Test de performance
Pourquoi les requêtes prennent-elles parfois plus de temps sur les petits ensembles de données ?
Les opérations d'interrogation sont effectuées sur des segments. Les index réduisent le temps nécessaire à l'interrogation d'un segment. Si un segment n'a pas été indexé, Milvus a recours à une recherche brute sur les données brutes, ce qui augmente considérablement le temps d'interrogation.
Par conséquent, l'interrogation d'un petit ensemble de données (collection) prend généralement plus de temps parce qu'il n'a pas été indexé. En effet, la taille de ses segments n'a pas atteint le seuil de construction d'index fixé par rootCoord.minSegmentSizeToEnableindex. Appelez create_index() pour forcer Milvus à indexer les segments qui ont atteint le seuil mais qui n'ont pas encore été indexés automatiquement, ce qui améliore considérablement les performances de la requête.
Quels sont les facteurs qui influencent l'utilisation de l'unité centrale ?
L'utilisation de l'UC augmente lorsque Milvus construit des index ou exécute des requêtes. En général, la construction d'index est gourmande en CPU, sauf lors de l'utilisation d'Annoy, qui s'exécute sur un seul thread.
Lors de l'exécution des requêtes, l'utilisation de l'unité centrale est affectée par nq et nprobe. Lorsque nq et nprobe sont petits, la concurrence est faible et l'utilisation de l'unité centrale reste basse.
L'insertion de données et la recherche simultanées ont-elles un impact sur les performances des requêtes ?
Les opérations d'insertion ne sont pas très gourmandes en ressources humaines. Toutefois, comme les nouveaux segments peuvent ne pas avoir atteint le seuil de construction de l'index, Milvus a recours à la recherche par force brute, ce qui a un impact significatif sur les performances de la requête.
Le paramètre rootcoord.minSegmentSizeToEnableIndex détermine le seuil de construction d'index pour un segment et est défini par défaut à 1024 lignes. Voir Configuration du système pour plus d'informations.
L'indexation d'un champ VARCHAR peut-elle améliorer la vitesse de suppression ?
L'indexation d'un champ VARCHAR peut accélérer les opérations de suppression par expression, mais uniquement sous certaines conditions :
- Index INVERTED: Cet index est utile pour les expressions
INou==sur les champs VARCHAR à clé non primaire. - Index Trie: Cet index est utile pour les requêtes de préfixe (par exemple,
LIKE prefix%) sur des champs VARCHAR non primaires.
Toutefois, l'indexation d'un champ VARCHAR n'accélère pas le processus :
- Suppression par ID: lorsque le champ VARCHAR est la clé primaire.
- Les expressions non liées: Lorsque le champ VARCHAR ne fait pas partie de l'expression de suppression.
Vous avez encore des questions ?
Vous pouvez le faire :
- Consulter Milvus sur GitHub. N'hésitez pas à poser des questions, à partager des idées et à aider les autres.
- Rejoignez notre canal Discord pour trouver de l'aide et vous engager avec notre communauté open-source.