Recuperación contextual con Milvus
![]()
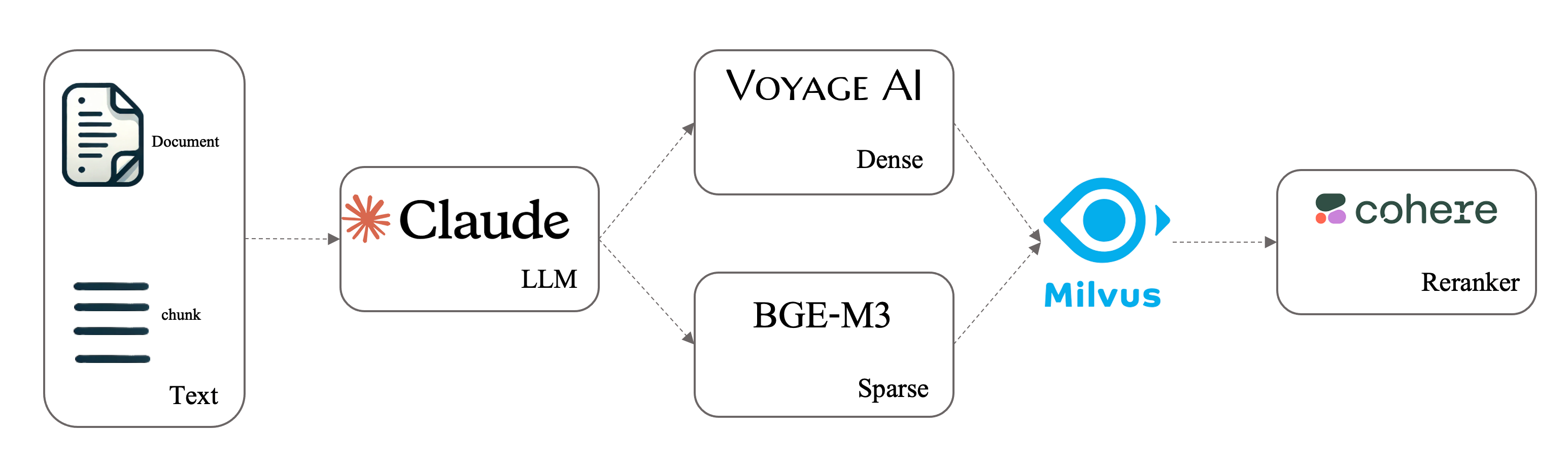 image Contextual Retrieval es un método avanzado de recuperación propuesto por Anthropic para resolver el problema del aislamiento semántico de los trozos, que se plantea en las soluciones actuales de Retrieval-Augmented Generation (RAG). En el paradigma práctico actual de la RAG, los documentos se dividen en varios trozos y se utiliza una base de datos vectorial para buscar la consulta, recuperando los trozos más relevantes. A continuación, un LLM responde a la consulta utilizando estos trozos recuperados. Sin embargo, este proceso de fragmentación puede provocar la pérdida de información contextual, lo que dificulta al recuperador la determinación de la relevancia.
image Contextual Retrieval es un método avanzado de recuperación propuesto por Anthropic para resolver el problema del aislamiento semántico de los trozos, que se plantea en las soluciones actuales de Retrieval-Augmented Generation (RAG). En el paradigma práctico actual de la RAG, los documentos se dividen en varios trozos y se utiliza una base de datos vectorial para buscar la consulta, recuperando los trozos más relevantes. A continuación, un LLM responde a la consulta utilizando estos trozos recuperados. Sin embargo, este proceso de fragmentación puede provocar la pérdida de información contextual, lo que dificulta al recuperador la determinación de la relevancia.
La recuperación contextual mejora los sistemas de recuperación tradicionales añadiendo el contexto pertinente a cada trozo de documento antes de incrustarlo o indexarlo, lo que aumenta la precisión y reduce los errores de recuperación. Combinada con técnicas como la recuperación híbrida y la reordenación, mejora los sistemas de generación mejorada de recuperación (RAG), especialmente en el caso de grandes bases de conocimiento. Además, ofrece una solución rentable cuando se combina con el almacenamiento rápido en caché, lo que reduce significativamente la latencia y los costes operativos, con trozos contextualizados que cuestan aproximadamente 1,02 dólares por millón de tokens de documentos. Esto lo convierte en un enfoque escalable y eficiente para manejar grandes bases de conocimiento. La solución de Anthropic muestra dos aspectos perspicaces:
Document Enhancement: La reescritura de consultas es una técnica crucial en la recuperación de información moderna, que a menudo utiliza información auxiliar para hacer la consulta más informativa. Del mismo modo, para lograr un mejor rendimiento en la RAG, el preprocesamiento de documentos con un LLM (por ejemplo, limpiando la fuente de datos, complementando la información perdida, resumiendo, etc.) antes de la indexación puede mejorar significativamente las posibilidades de recuperar documentos relevantes. En otras palabras, este paso de preprocesamiento ayuda a acercar los documentos a las consultas en términos de relevancia.Low-Cost Processing by Caching Long Context: Una preocupación común cuando se utilizan LLM para procesar documentos es el coste. El KVCache es una solución popular que permite la reutilización de resultados intermedios para el mismo contexto precedente. Mientras que la mayoría de los proveedores de LLM alojados hacen que esta característica sea transparente para el usuario, Anthropic da a los usuarios el control sobre el proceso de caché. Cuando se produce un golpe en la caché, la mayoría de los cálculos pueden ser guardados (esto es común cuando el contexto largo sigue siendo el mismo, pero la instrucción para cada consulta cambia). Para más detalles, haz clic aquí.
En este cuaderno, demostraremos cómo realizar una recuperación contextual utilizando Milvus con un LLM, combinando una recuperación híbrida densa-esparcida y un reranker para crear un sistema de recuperación progresivamente más potente. Los datos y la configuración experimental se basan en la recuperación contextual.
Preparación
Instalación de dependencias
$ pip install "pymilvus[model]"
$ pip install tqdm
$ pip install anthropic
Si utiliza Google Colab, para habilitar las dependencias que acaba de instalar, es posible que tenga que reiniciar el tiempo de ejecución (haga clic en el menú "Tiempo de ejecución" en la parte superior de la pantalla y seleccione "Reiniciar sesión" en el menú desplegable).
Necesitará las claves API de Cohere, Voyage y Anthropic para ejecutar el código.
Descarga de datos
El siguiente comando descargará los datos de ejemplo utilizados en la demo original de Anthropic.
$ wget https://raw.githubusercontent.com/anthropics/anthropic-cookbook/refs/heads/main/skills/contextual-embeddings/data/codebase_chunks.json
$ wget https://raw.githubusercontent.com/anthropics/anthropic-cookbook/refs/heads/main/skills/contextual-embeddings/data/evaluation_set.jsonl
Definir Recuperador
Esta clase está diseñada para ser flexible, lo que le permite elegir entre diferentes modos de recuperación en función de sus necesidades. Especificando opciones en el método de inicialización, puede determinar si desea utilizar la recuperación contextual, la búsqueda híbrida (combinando métodos de recuperación densos y dispersos), o un reranker para mejorar los resultados.
from pymilvus.model.dense import VoyageEmbeddingFunction
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
from pymilvus.model.reranker import CohereRerankFunction
from typing import List, Dict, Any
from typing import Callable
from pymilvus import (
MilvusClient,
DataType,
AnnSearchRequest,
RRFRanker,
)
from tqdm import tqdm
import json
import anthropic
class MilvusContextualRetriever:
def __init__(
self,
uri="milvus.db",
collection_name="contexual_bgem3",
dense_embedding_function=None,
use_sparse=False,
sparse_embedding_function=None,
use_contextualize_embedding=False,
anthropic_client=None,
use_reranker=False,
rerank_function=None,
):
self.collection_name = collection_name
# For Milvus-lite, uri is a local path like "./milvus.db"
# For Milvus standalone service, uri is like "http://localhost:19530"
# For Zilliz Clond, please set `uri` and `token`, which correspond to the [Public Endpoint and API key](https://docs.zilliz.com/docs/on-zilliz-cloud-console#cluster-details) in Zilliz Cloud.
self.client = MilvusClient(uri)
self.embedding_function = dense_embedding_function
self.use_sparse = use_sparse
self.sparse_embedding_function = None
self.use_contextualize_embedding = use_contextualize_embedding
self.anthropic_client = anthropic_client
self.use_reranker = use_reranker
self.rerank_function = rerank_function
if use_sparse is True and sparse_embedding_function:
self.sparse_embedding_function = sparse_embedding_function
elif sparse_embedding_function is False:
raise ValueError(
"Sparse embedding function cannot be None if use_sparse is False"
)
else:
pass
def build_collection(self):
schema = self.client.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(
field_name="dense_vector",
datatype=DataType.FLOAT_VECTOR,
dim=self.embedding_function.dim,
)
if self.use_sparse is True:
schema.add_field(
field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR
)
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="dense_vector", index_type="FLAT", metric_type="IP"
)
if self.use_sparse is True:
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
self.client.create_collection(
collection_name=self.collection_name,
schema=schema,
index_params=index_params,
enable_dynamic_field=True,
)
def insert_data(self, chunk, metadata):
dense_vec = self.embedding_function([chunk])[0]
if self.use_sparse is True:
sparse_result = self.sparse_embedding_function.encode_documents([chunk])
if type(sparse_result) == dict:
sparse_vec = sparse_result["sparse"][[0]]
else:
sparse_vec = sparse_result[[0]]
self.client.insert(
collection_name=self.collection_name,
data={
"dense_vector": dense_vec,
"sparse_vector": sparse_vec,
**metadata,
},
)
else:
self.client.insert(
collection_name=self.collection_name,
data={"dense_vector": dense_vec, **metadata},
)
def insert_contextualized_data(self, doc, chunk, metadata):
contextualized_text, usage = self.situate_context(doc, chunk)
metadata["context"] = contextualized_text
text_to_embed = f"{chunk}\n\n{contextualized_text}"
dense_vec = self.embedding_function([text_to_embed])[0]
if self.use_sparse is True:
sparse_vec = self.sparse_embedding_function.encode_documents(
[text_to_embed]
)["sparse"][[0]]
self.client.insert(
collection_name=self.collection_name,
data={
"dense_vector": dense_vec,
"sparse_vector": sparse_vec,
**metadata,
},
)
else:
self.client.insert(
collection_name=self.collection_name,
data={"dense_vector": dense_vec, **metadata},
)
def situate_context(self, doc: str, chunk: str):
DOCUMENT_CONTEXT_PROMPT = """
<document>
{doc_content}
</document>
"""
CHUNK_CONTEXT_PROMPT = """
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
response = self.anthropic_client.beta.prompt_caching.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1000,
temperature=0.0,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": DOCUMENT_CONTEXT_PROMPT.format(doc_content=doc),
"cache_control": {
"type": "ephemeral"
}, # we will make use of prompt caching for the full documents
},
{
"type": "text",
"text": CHUNK_CONTEXT_PROMPT.format(chunk_content=chunk),
},
],
},
],
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"},
)
return response.content[0].text, response.usage
def search(self, query: str, k: int = 20) -> List[Dict[str, Any]]:
dense_vec = self.embedding_function([query])[0]
if self.use_sparse is True:
sparse_vec = self.sparse_embedding_function.encode_queries([query])[
"sparse"
][[0]]
req_list = []
if self.use_reranker:
k = k * 10
if self.use_sparse is True:
req_list = []
dense_search_param = {
"data": [dense_vec],
"anns_field": "dense_vector",
"param": {"metric_type": "IP"},
"limit": k * 2,
}
dense_req = AnnSearchRequest(**dense_search_param)
req_list.append(dense_req)
sparse_search_param = {
"data": [sparse_vec],
"anns_field": "sparse_vector",
"param": {"metric_type": "IP"},
"limit": k * 2,
}
sparse_req = AnnSearchRequest(**sparse_search_param)
req_list.append(sparse_req)
docs = self.client.hybrid_search(
self.collection_name,
req_list,
RRFRanker(),
k,
output_fields=[
"content",
"original_uuid",
"doc_id",
"chunk_id",
"original_index",
"context",
],
)
else:
docs = self.client.search(
self.collection_name,
data=[dense_vec],
anns_field="dense_vector",
limit=k,
output_fields=[
"content",
"original_uuid",
"doc_id",
"chunk_id",
"original_index",
"context",
],
)
if self.use_reranker and self.use_contextualize_embedding:
reranked_texts = []
reranked_docs = []
for i in range(k):
if self.use_contextualize_embedding:
reranked_texts.append(
f"{docs[0][i]['entity']['content']}\n\n{docs[0][i]['entity']['context']}"
)
else:
reranked_texts.append(f"{docs[0][i]['entity']['content']}")
results = self.rerank_function(query, reranked_texts)
for result in results:
reranked_docs.append(docs[0][result.index])
docs[0] = reranked_docs
return docs
def evaluate_retrieval(
queries: List[Dict[str, Any]], retrieval_function: Callable, db, k: int = 20
) -> Dict[str, float]:
total_score = 0
total_queries = len(queries)
for query_item in tqdm(queries, desc="Evaluating retrieval"):
query = query_item["query"]
golden_chunk_uuids = query_item["golden_chunk_uuids"]
# Find all golden chunk contents
golden_contents = []
for doc_uuid, chunk_index in golden_chunk_uuids:
golden_doc = next(
(
doc
for doc in query_item["golden_documents"]
if doc["uuid"] == doc_uuid
),
None,
)
if not golden_doc:
print(f"Warning: Golden document not found for UUID {doc_uuid}")
continue
golden_chunk = next(
(
chunk
for chunk in golden_doc["chunks"]
if chunk["index"] == chunk_index
),
None,
)
if not golden_chunk:
print(
f"Warning: Golden chunk not found for index {chunk_index} in document {doc_uuid}"
)
continue
golden_contents.append(golden_chunk["content"].strip())
if not golden_contents:
print(f"Warning: No golden contents found for query: {query}")
continue
retrieved_docs = retrieval_function(query, db, k=k)
# Count how many golden chunks are in the top k retrieved documents
chunks_found = 0
for golden_content in golden_contents:
for doc in retrieved_docs[0][:k]:
retrieved_content = doc["entity"]["content"].strip()
if retrieved_content == golden_content:
chunks_found += 1
break
query_score = chunks_found / len(golden_contents)
total_score += query_score
average_score = total_score / total_queries
pass_at_n = average_score * 100
return {
"pass_at_n": pass_at_n,
"average_score": average_score,
"total_queries": total_queries,
}
def retrieve_base(query: str, db, k: int = 20) -> List[Dict[str, Any]]:
return db.search(query, k=k)
def load_jsonl(file_path: str) -> List[Dict[str, Any]]:
"""Load JSONL file and return a list of dictionaries."""
with open(file_path, "r") as file:
return [json.loads(line) for line in file]
def evaluate_db(db, original_jsonl_path: str, k):
# Load the original JSONL data for queries and ground truth
original_data = load_jsonl(original_jsonl_path)
# Evaluate retrieval
results = evaluate_retrieval(original_data, retrieve_base, db, k)
print(f"Pass@{k}: {results['pass_at_n']:.2f}%")
print(f"Total Score: {results['average_score']}")
print(f"Total queries: {results['total_queries']}")
Ahora debe inicializar estos modelos para los siguientes experimentos. Puedes cambiar fácilmente a otros modelos utilizando la biblioteca de modelos PyMilvus.
dense_ef = VoyageEmbeddingFunction(api_key="your-voyage-api-key", model_name="voyage-2")
sparse_ef = BGEM3EmbeddingFunction()
cohere_rf = CohereRerankFunction(api_key="your-cohere-api-key")
Fetching 30 files: 0%| | 0/30 [00:00<?, ?it/s]
path = "codebase_chunks.json"
with open(path, "r") as f:
dataset = json.load(f)
Experimento I: Recuperación estándar
La recuperación estándar sólo utiliza incrustaciones densas para recuperar documentos relacionados. En este experimento, utilizaremos Pass@5 para reproducir los resultados del repositorio original.
standard_retriever = MilvusContextualRetriever(
uri="standard.db", collection_name="standard", dense_embedding_function=dense_ef
)
standard_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
standard_retriever.insert_data(chunk_content, metadata)
evaluate_db(standard_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [01:29<00:00, 2.77it/s]
Pass@5: 80.92%
Total Score: 0.8091877880184332
Total queries: 248
Experimento II: Recuperación híbrida
Ahora que hemos obtenido resultados prometedores con la incrustación Voyage, pasaremos a realizar una recuperación híbrida utilizando el modelo BGE-M3, que genera potentes incrustaciones dispersas. Los resultados de la recuperación densa y la recuperación dispersa se combinarán mediante el método de fusión recíproca de rangos (RRF) para obtener un resultado híbrido.
hybrid_retriever = MilvusContextualRetriever(
uri="hybrid.db",
collection_name="hybrid",
dense_embedding_function=dense_ef,
use_sparse=True,
sparse_embedding_function=sparse_ef,
)
hybrid_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
hybrid_retriever.insert_data(chunk_content, metadata)
evaluate_db(hybrid_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [02:09<00:00, 1.92it/s]
Pass@5: 84.69%
Total Score: 0.8469182027649771
Total queries: 248
Experimento III: Recuperación contextual
La recuperación híbrida muestra una mejora, pero los resultados pueden mejorarse aún más aplicando un método de recuperación contextual. Para ello, utilizaremos el modelo lingüístico de Anthropic para añadir el contexto del documento completo a cada fragmento.
anthropic_client = anthropic.Anthropic(
api_key="your-anthropic-api-key",
)
contextual_retriever = MilvusContextualRetriever(
uri="contextual.db",
collection_name="contextual",
dense_embedding_function=dense_ef,
use_sparse=True,
sparse_embedding_function=sparse_ef,
use_contextualize_embedding=True,
anthropic_client=anthropic_client,
)
contextual_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
contextual_retriever.insert_contextualized_data(
doc_content, chunk_content, metadata
)
evaluate_db(contextual_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [01:55<00:00, 2.15it/s]
Pass@5: 87.14%
Total Score: 0.8713517665130568
Total queries: 248
Experimento IV: Recuperación contextual con Reranker
Los resultados pueden mejorarse aún más añadiendo un reranker Cohere. Sin necesidad de inicializar un nuevo recuperador con reranker por separado, podemos simplemente configurar el recuperador existente para que utilice el reranker para mejorar el rendimiento.
contextual_retriever.use_reranker = True
contextual_retriever.rerank_function = cohere_rf
evaluate_db(contextual_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [02:02<00:00, 2.00it/s]
Pass@5: 90.91%
Total Score: 0.9090821812596005
Total queries: 248
Hemos demostrado varios métodos para mejorar el rendimiento de recuperación. Con un diseño más ad hoc adaptado al escenario, la recuperación contextual muestra un potencial significativo para preprocesar documentos a bajo coste, lo que conduce a un mejor sistema GAR.