Vektor-Visualisierung
![]()
In diesem Beispiel wird gezeigt, wie die Einbettungen (Vektoren) in Milvus mit t-SNE visualisiert werden können.
Techniken zur Dimensionalitätsreduktion, wie t-SNE, sind von unschätzbarem Wert für die Visualisierung komplexer, hochdimensionaler Daten in einem 2D- oder 3D-Raum, wobei die lokale Struktur erhalten bleibt. Dies ermöglicht die Mustererkennung, verbessert das Verständnis von Merkmalsbeziehungen und erleichtert die Interpretation der Ergebnisse von Modellen des maschinellen Lernens. Darüber hinaus hilft es bei der Bewertung von Algorithmen durch den visuellen Vergleich von Clustering-Ergebnissen, vereinfacht die Datenpräsentation für ein nicht spezialisiertes Publikum und kann durch die Arbeit mit niedrigdimensionalen Darstellungen die Rechenkosten senken. Durch diese Anwendungen hilft t-SNE nicht nur dabei, tiefere Einblicke in Datensätze zu gewinnen, sondern unterstützt auch fundiertere Entscheidungsprozesse.
Vorbereitung
Abhängigkeiten und Umgebung
$ pip install --upgrade pymilvus openai requests tqdm matplotlib seaborn
Wir werden in diesem Beispiel das Einbettungsmodell von OpenAI verwenden. Sie sollten den Api-Schlüssel OPENAI_API_KEY als Umgebungsvariable vorbereiten.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
Bereiten Sie die Daten vor
Wir verwenden die FAQ-Seiten aus der Milvus-Dokumentation 2.4.x als privates Wissen in unserem RAG, was eine gute Datenquelle für eine einfache RAG-Pipeline ist.
Laden Sie die Zip-Datei herunter und entpacken Sie die Dokumente in den Ordner milvus_docs.
$ wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
$ unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
Wir laden alle Markdown-Dateien aus dem Ordner milvus_docs/en/faq. Für jedes Dokument verwenden wir einfach "# ", um den Inhalt in der Datei zu trennen, wodurch der Inhalt jedes Hauptteils der Markdown-Datei grob getrennt werden kann.
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
Vorbereiten des Einbettungsmodells
Wir initialisieren den OpenAI-Client, um das Einbettungsmodell vorzubereiten.
from openai import OpenAI
openai_client = OpenAI()
Definieren Sie eine Funktion zur Erzeugung von Texteinbettungen mit dem OpenAI-Client. Wir verwenden das Modell text-embedding-3-large als Beispiel.
def emb_text(text):
return (
openai_client.embeddings.create(input=text, model="text-embedding-3-large")
.data[0]
.embedding
)
Erzeugen Sie eine Testeinbettung und geben Sie deren Dimension und die ersten Elemente aus.
test_embedding = emb_text("This is a test")
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
3072
[-0.015370666049420834, 0.00234124343842268, -0.01011690590530634, 0.044725317507982254, -0.017235849052667618, -0.02880779094994068, -0.026678944006562233, 0.06816216558218002, -0.011376636102795601, 0.021659553050994873]
Laden der Daten in Milvus
Erstellen Sie die Sammlung
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
Wie für das Argument von MilvusClient:
- Die Einstellung von
urials lokale Datei, z. B../milvus.db, ist die bequemste Methode, da Milvus Lite automatisch alle Daten in dieser Datei speichert. - Wenn Sie große Datenmengen haben, können Sie einen leistungsfähigeren Milvus-Server auf Docker oder Kubernetes einrichten. Bei dieser Einrichtung verwenden Sie bitte die Server-Uri, z. B.
http://localhost:19530, alsuri. - Wenn Sie Zilliz Cloud, den vollständig verwalteten Cloud-Service für Milvus, verwenden möchten, passen Sie
uriundtokenan, die dem öffentlichen Endpunkt und dem Api-Schlüssel in Zilliz Cloud entsprechen.
Prüfen Sie, ob die Sammlung bereits existiert und löschen Sie sie, wenn dies der Fall ist.
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
Erstellen Sie eine neue Sammlung mit den angegebenen Parametern.
Wenn wir keine Feldinformationen angeben, erstellt Milvus automatisch ein Standardfeld id für den Primärschlüssel und ein Feld vector zum Speichern der Vektordaten. Ein reserviertes JSON-Feld wird verwendet, um nicht schema-definierte Felder und ihre Werte zu speichern.
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Strong", # Strong consistency level
)
Daten einfügen
Iterieren Sie durch die Textzeilen, erstellen Sie Einbettungen und fügen Sie dann die Daten in Milvus ein.
Hier ist ein neues Feld text, das ein nicht definiertes Feld im Sammelschema ist. Es wird automatisch dem reservierten dynamischen JSON-Feld hinzugefügt, das auf hoher Ebene wie ein normales Feld behandelt werden kann.
from tqdm import tqdm
data = []
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": emb_text(line), "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Creating embeddings: 100%|██████████| 72/72 [00:20<00:00, 3.60it/s]
{'insert_count': 72, 'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71], 'cost': 0}
Visualisierung von Einbettungen bei der Vektorsuche
In diesem Abschnitt führen wir eine Milvus-Suche durch und visualisieren dann den Abfragevektor und den abgerufenen Vektor zusammen in reduzierter Dimension.
Abrufen von Daten für eine Abfrage
Lassen Sie uns eine Frage für die Suche vorbereiten.
# Modify the question to test it with your own query!
question = "How is data stored in Milvus?"
Suchen Sie nach der Frage in der Sammlung und rufen Sie die semantischen Top-10-Treffer ab.
search_res = milvus_client.search(
collection_name=collection_name,
data=[
emb_text(question)
], # Use the `emb_text` function to convert the question to an embedding vector
limit=10, # Return top 10 results
search_params={"metric_type": "IP", "params": {}}, # Inner product distance
output_fields=["text"], # Return the text field
)
Werfen wir einen Blick auf die Suchergebnisse der Abfrage
import json
retrieved_lines_with_distances = [
(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
0.7675539255142212
],
[
"How does Milvus handle vector data types and precision?\n\nMilvus supports Binary, Float32, Float16, and BFloat16 vector types.\n\n- Binary vectors: Store binary data as sequences of 0s and 1s, used in image processing and information retrieval.\n- Float32 vectors: Default storage with a precision of about 7 decimal digits. Even Float64 values are stored with Float32 precision, leading to potential precision loss upon retrieval.\n- Float16 and BFloat16 vectors: Offer reduced precision and memory usage. Float16 is suitable for applications with limited bandwidth and storage, while BFloat16 balances range and efficiency, commonly used in deep learning to reduce computational requirements without significantly impacting accuracy.\n\n###",
0.6210848689079285
],
[
"Does the query perform in memory? What are incremental data and historical data?\n\nYes. When a query request comes, Milvus searches both incremental data and historical data by loading them into memory. Incremental data are in the growing segments, which are buffered in memory before they reach the threshold to be persisted in storage engine, while historical data are from the sealed segments that are stored in the object storage. Incremental data and historical data together constitute the whole dataset to search.\n\n###",
0.585393488407135
],
[
"Why is there no vector data in etcd?\n\netcd stores Milvus module metadata; MinIO stores entities.\n\n###",
0.579704999923706
],
[
"How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",
0.5777501463890076
],
[
"What is the maximum dataset size Milvus can handle?\n\n \nTheoretically, the maximum dataset size Milvus can handle is determined by the hardware it is run on, specifically system memory and storage:\n\n- Milvus loads all specified collections and partitions into memory before running queries. Therefore, memory size determines the maximum amount of data Milvus can query.\n- When new entities and and collection-related schema (currently only MinIO is supported for data persistence) are added to Milvus, system storage determines the maximum allowable size of inserted data.\n\n###",
0.5655910968780518
],
[
"Does Milvus support inserting and searching data simultaneously?\n\nYes. Insert operations and query operations are handled by two separate modules that are mutually independent. From the client\u2019s perspective, an insert operation is complete when the inserted data enters the message queue. However, inserted data are unsearchable until they are loaded to the query node. If the segment size does not reach the index-building threshold (512 MB by default), Milvus resorts to brute-force search and query performance may be diminished.\n\n###",
0.5618637204170227
],
[
"What data types does Milvus support on the primary key field?\n\nIn current release, Milvus supports both INT64 and string.\n\n###",
0.5561620593070984
],
[
"Is Milvus available for concurrent search?\n\nYes. For queries on the same collection, Milvus concurrently searches the incremental and historical data. However, queries on different collections are conducted in series. Whereas the historical data can be an extremely huge dataset, searches on the historical data are relatively more time-consuming and essentially performed in series.\n\n###",
0.529681921005249
],
[
"Can vectors with duplicate primary keys be inserted into Milvus?\n\nYes. Milvus does not check if vector primary keys are duplicates.\n\n###",
0.528809666633606
]
]
Dimensionalitätsreduktion auf 2-d durch t-SNE
Reduzieren wir die Dimension der Einbettungen mit t-SNE auf 2-d. Wir verwenden die Bibliothek sklearn, um die t-SNE-Transformation durchzuführen.
import pandas as pd
import numpy as np
from sklearn.manifold import TSNE
data.append({"id": len(data), "vector": emb_text(question), "text": question})
embeddings = []
for gp in data:
embeddings.append(gp["vector"])
X = np.array(embeddings, dtype=np.float32)
tsne = TSNE(random_state=0, max_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=["TSNE1", "TSNE2"])
df_tsne
| TSNE1 | TSNE2 | |
|---|---|---|
| 0 | -3.877362 | 0.866726 |
| 1 | -5.923084 | 0.671701 |
| 2 | -0.645954 | 0.240083 |
| 3 | 0.444582 | 1.222875 |
| 4 | 6.503896 | -4.984684 |
| ... | ... | ... |
| 69 | 6.354055 | 1.264959 |
| 70 | 6.055961 | 1.266211 |
| 71 | -1.516003 | 1.328765 |
| 72 | 3.971772 | -0.681780 |
| 73 | 3.971772 | -0.681780 |
74 Zeilen × 2 Spalten
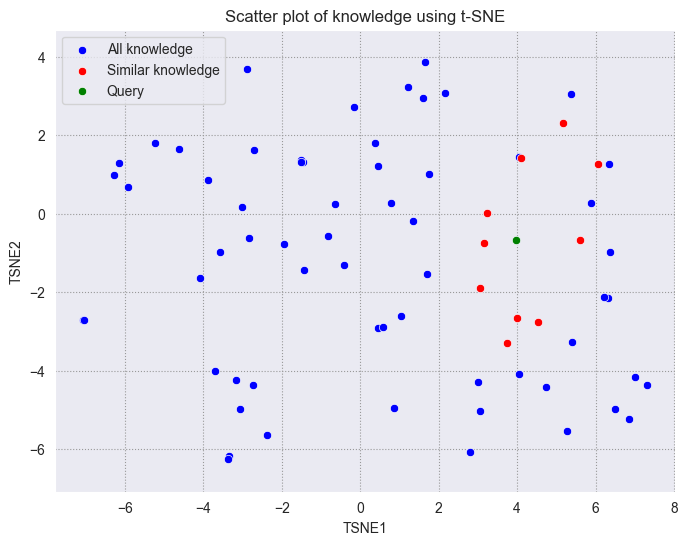
Visualisierung der Milvus-Suchergebnisse auf einer 2d-Ebene
Wir stellen den Abfragevektor in grün, die gefundenen Vektoren in rot und die übrigen Vektoren in blau dar.
import matplotlib.pyplot as plt
import seaborn as sns
# Extract similar ids from search results
similar_ids = [gp["id"] for gp in search_res[0]]
df_norm = df_tsne[:-1]
df_query = pd.DataFrame(df_tsne.iloc[-1]).T
# Filter points based on similar ids
similar_points = df_tsne[df_tsne.index.isin(similar_ids)]
# Create the plot
fig, ax = plt.subplots(figsize=(8, 6)) # Set figsize
# Set the style of the plot
sns.set_style("darkgrid", {"grid.color": ".6", "grid.linestyle": ":"})
# Plot all points in blue
sns.scatterplot(
data=df_tsne, x="TSNE1", y="TSNE2", color="blue", label="All knowledge", ax=ax
)
# Overlay similar points in red
sns.scatterplot(
data=similar_points,
x="TSNE1",
y="TSNE2",
color="red",
label="Similar knowledge",
ax=ax,
)
sns.scatterplot(
data=df_query, x="TSNE1", y="TSNE2", color="green", label="Query", ax=ax
)
# Set plot titles and labels
plt.title("Scatter plot of knowledge using t-SNE")
plt.xlabel("TSNE1")
plt.ylabel("TSNE2")
# Set axis to be equal
plt.axis("equal")
# Display the legend
plt.legend()
# Show the plot
plt.show()
 png
png
Wie wir sehen können, liegt der Abfragevektor nahe bei den gefundenen Vektoren. Obwohl die abgerufenen Vektoren nicht innerhalb eines Standardkreises mit festem Radius liegen, der auf die Abfrage zentriert ist, können wir sehen, dass sie dem Abfragevektor auf der 2D-Ebene immer noch sehr nahe sind.
Der Einsatz von Techniken zur Dimensionalitätsreduktion kann das Verständnis von Vektoren und die Fehlerbehebung erleichtern. Ich hoffe, dass Sie durch dieses Tutorial ein besseres Verständnis von Vektoren erlangen können.