Airbyte: Open-Source-Infrastruktur für die Datenübertragung
Airbyte ist eine Open-Source-Infrastruktur für die Datenübertragung zum Aufbau von Extraktions- und Ladepipelines (EL). Sie ist auf Vielseitigkeit, Skalierbarkeit und Benutzerfreundlichkeit ausgelegt. Der Konnektorkatalog von Airbyte enthält mehr als 350 vorkonfigurierte Konnektoren. Mit diesen Konnektoren kann die Replikation von Daten von einer Quelle zu einem Ziel in nur wenigen Minuten beginnen.
Die wichtigsten Komponenten von Airbyte
1. Konnektor-Katalog
- Über 350 vorgefertigte Konnektoren: Der Konnektorkatalog von Airbyte enthält mehr als 350 vorkonfigurierte Konnektoren. Mit diesen Konnektoren können Sie in wenigen Minuten mit der Replikation von Daten von einer Quelle zu einem Ziel beginnen.
- No-Code Connector Builder: Mit Hilfe von Tools wie dem No-Code Connector Builder können Sie die Funktionalität von Airbyte ganz einfach erweitern, um Ihre eigenen Anwendungsfälle zu unterstützen.
2. Die Plattform
Die Plattform von Airbyte bietet alle horizontalen Dienste, die für die Konfiguration und Skalierung von Datenverschiebungsvorgängen erforderlich sind, und ist als Cloud-Managed oder Self-Managed verfügbar.
3. Die Benutzeroberfläche
Airbyte verfügt über eine Benutzeroberfläche, PyAirbyte (Python-Bibliothek), eine API und einen Terraform-Provider zur Integration mit den von Ihnen bevorzugten Werkzeugen und Ansätzen für das Infrastrukturmanagement.
Mit der Fähigkeit von Airbyte können Benutzer Datenquellen in Milvus-Cluster für die Ähnlichkeitssuche integrieren.
Bevor Sie beginnen
Sie benötigen:
- Zendesk-Konto (oder eine andere Datenquelle, mit der Sie Daten synchronisieren möchten)
- Airbyte-Konto oder lokale Instanz
- OpenAI-API-Schlüssel
- Milvus-Cluster
- Lokal installiertes Python 3.10
Milvus-Cluster einrichten
Wenn Sie bereits einen K8s-Cluster für die Produktion eingerichtet haben, können Sie diesen Schritt überspringen und direkt mit der Einrichtung von Milvus Operator fortfahren. Wenn nicht, können Sie die Schritte zur Einrichtung eines Milvus-Clusters mit Milvus Operator befolgen.
Einzelne Entitäten (in unserem Fall Support-Tickets und Knowledge-Base-Artikel) werden in einer "Sammlung" gespeichert - nachdem Ihr Cluster eingerichtet ist, müssen Sie eine Sammlung erstellen. Wählen Sie einen geeigneten Namen und setzen Sie die Dimension auf 1536, um die vom OpenAI Embeddings Service generierte Vektordimensionalität zu erreichen.
Tragen Sie nach der Erstellung den Endpunkt und die Authentifizierungsdaten ein.
Einrichten der Verbindung in Airbyte
Unsere Datenbank ist fertig, jetzt können wir einige Daten übertragen! Zu diesem Zweck müssen wir eine Verbindung in Airbyte konfigurieren. Melden Sie sich entweder für ein Airbyte-Cloud-Konto unter cloud.airbyte.com an oder richten Sie eine lokale Instanz ein, wie in der Dokumentation beschrieben.
Quelle einrichten
Sobald Ihre Instanz läuft, müssen wir die Verbindung einrichten - klicken Sie auf "Neue Verbindung" und wählen Sie den Connector "Zendesk Support" als Quelle. Nachdem Sie auf die Schaltfläche "Testen und Speichern" geklickt haben, prüft Airbyte, ob die Verbindung hergestellt werden kann.
In der Airbyte-Cloud können Sie sich ganz einfach authentifizieren, indem Sie auf die Schaltfläche "Authentifizieren" klicken. Wenn Sie eine lokale Airbyte-Instanz verwenden, folgen Sie den Anweisungen auf der Dokumentationsseite.
Ziel einrichten
Wenn alles korrekt funktioniert, ist der nächste Schritt die Einrichtung des Ziels, zu dem die Daten verschoben werden sollen. Wählen Sie hier den "Milvus"-Konnektor.
Der Milvus-Konnektor erfüllt drei Aufgaben:
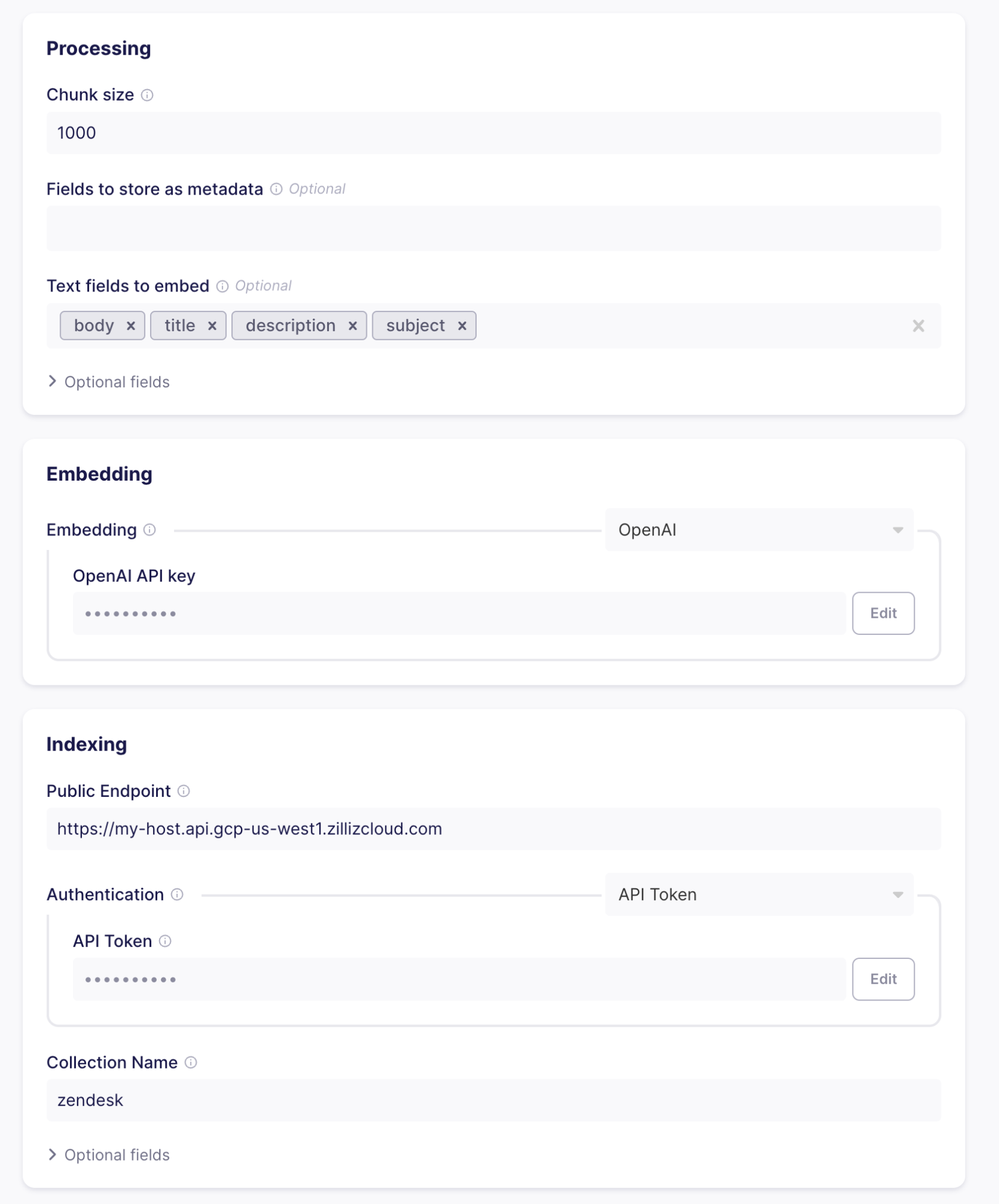
- Chunking und Formatierung - Aufteilung der Zendesk-Datensätze in Text und Metadaten. Wenn der Text größer als die angegebene Chunk-Größe ist, werden die Datensätze in mehrere Teile aufgeteilt, die einzeln in die Sammlung geladen werden. Die Aufteilung von Text (oder Chunking) kann zum Beispiel bei umfangreichen Support-Tickets oder Wissensartikeln erfolgen. Durch die Aufteilung des Textes können Sie sicherstellen, dass die Suche immer nützliche Ergebnisse liefert.
Nehmen wir eine Chunk-Größe von 1000 Token und die Textfelder body, title, description und subject, da diese in den Daten, die wir von Zendesk erhalten, vorhanden sein werden.
- Einbettung - Mithilfe von Modellen für maschinelles Lernen werden die vom Verarbeitungsteil erzeugten Textabschnitte in Vektoreinbettungen umgewandelt, die Sie dann nach semantischer Ähnlichkeit durchsuchen können. Um die Einbettungen zu erstellen, müssen Sie den OpenAI-API-Schlüssel angeben. Airbyte sendet jeden Chunk an OpenAI und fügt den resultierenden Vektor zu den Entitäten hinzu, die in Ihren Milvus-Cluster geladen wurden.
- Indexierung - Sobald Sie die Chunks vektorisiert haben, können Sie sie in die Datenbank laden. Geben Sie dazu die Informationen ein, die Sie beim Einrichten Ihres Clusters und Ihrer Sammlung in Milvus Cluster erhalten haben. Wenn Sie auf "Testen und speichern" klicken, wird geprüft, ob alles richtig eingestellt ist (gültige Anmeldeinformationen, die Sammlung existiert und hat die gleiche Vektordimensionalität wie die konfigurierte Einbettung usw.)
Stream-Synchronisierungsfluss einrichten
Der letzte Schritt, bevor die Daten fließen können, ist die Auswahl der zu synchronisierenden "Streams". Ein Stream ist eine Sammlung von Datensätzen in der Quelle. Da Zendesk eine große Anzahl von Streams unterstützt, die für unseren Anwendungsfall nicht relevant sind, wählen wir nur "Tickets" und "Artikel" aus und deaktivieren alle anderen, um Bandbreite zu sparen und sicherzustellen, dass nur die relevanten Informationen bei der Suche angezeigt werden:
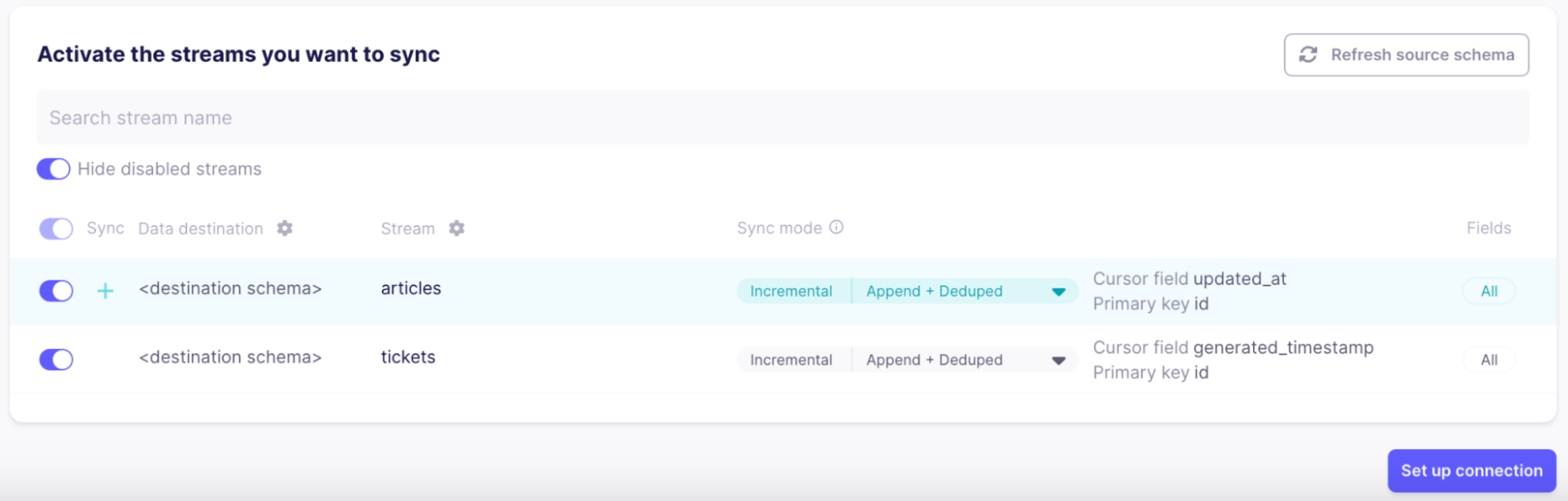
Sobald die Verbindung hergestellt ist, beginnt Airbyte mit der Synchronisierung der Daten. Es kann ein paar Minuten dauern, bis sie in Ihrer Milvus-Sammlung erscheinen.
Wenn Sie eine Replikationsfrequenz auswählen, wird Airbyte regelmäßig ausgeführt, um Ihre Milvus-Sammlung mit Änderungen an Zendesk-Artikeln und neu erstellten Tickets auf dem neuesten Stand zu halten.
Ablauf prüfen
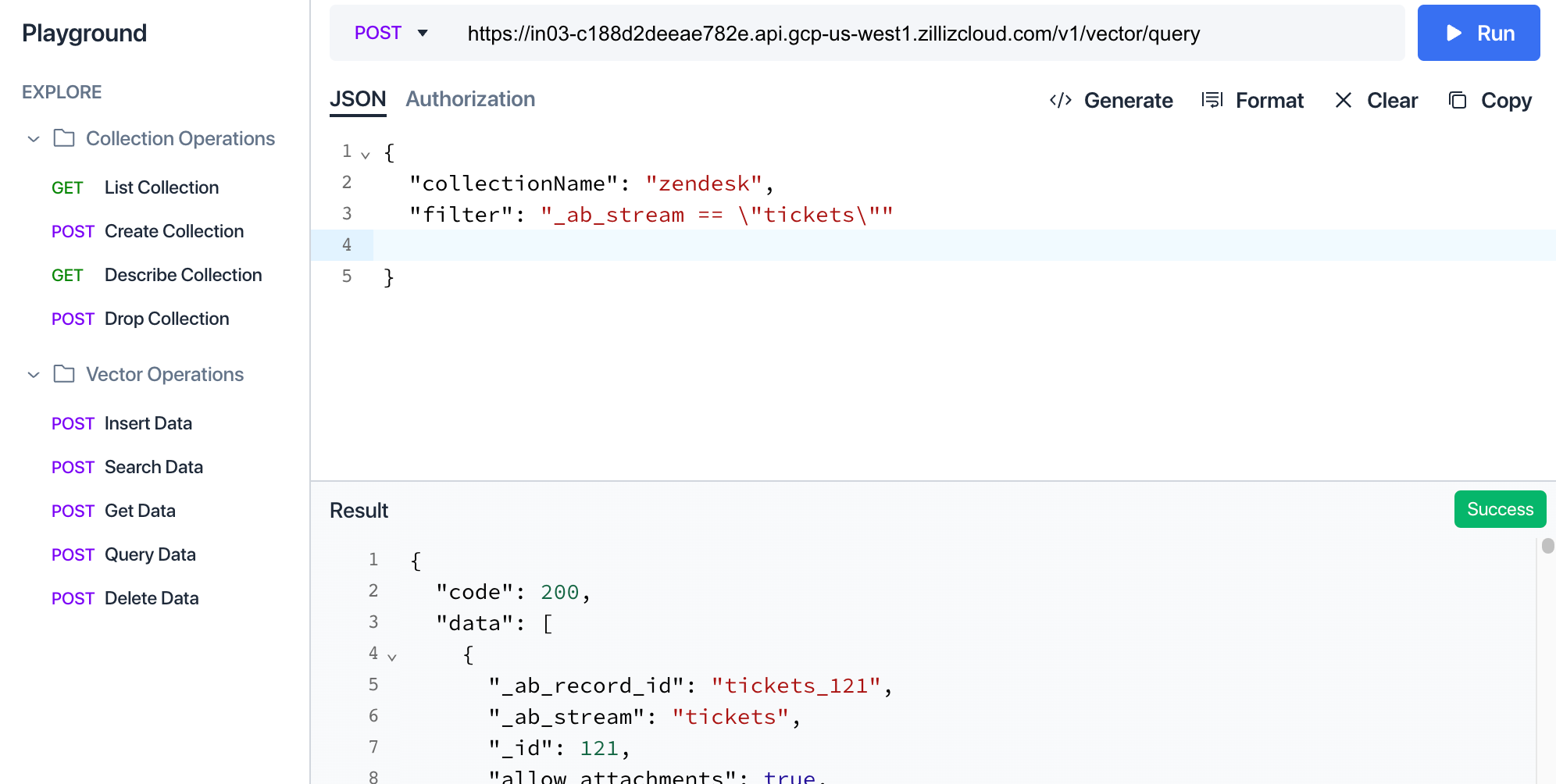
Sie können in der Milvus-Cluster-Benutzeroberfläche überprüfen, wie die Daten in der Sammlung strukturiert sind, indem Sie zur Spielwiese navigieren und eine "Query Data"-Abfrage mit einem auf "_ab_stream == \"tickets\"" gesetzten Filter ausführen.
Erstellen einer Streamlit-App zur Abfrage der Sammlung
Unsere Daten sind fertig - jetzt müssen wir die Anwendung erstellen, die sie nutzen soll. In diesem Fall wird die Anwendung ein einfaches Support-Formular sein, mit dem Benutzer Support-Fälle einreichen können. Wenn der Benutzer auf "Senden" klickt, werden wir zwei Dinge tun:
- Suche nach ähnlichen Anfragen, die von Benutzern der gleichen Organisation eingereicht wurden
- Suche nach wissensbasierten Artikeln, die für den Benutzer relevant sein könnten
In beiden Fällen werden wir die semantische Suche mit OpenAI-Einbettungen nutzen. Dazu wird die Beschreibung des Problems, das der Benutzer eingegeben hat, ebenfalls eingebettet und verwendet, um ähnliche Entitäten aus dem Milvus-Cluster zu finden. Wenn es relevante Ergebnisse gibt, werden diese unterhalb des Formulars angezeigt.
Einrichten der UI-Umgebung
Sie benötigen eine lokale Python-Installation, da wir Streamlit zur Implementierung der Anwendung verwenden werden.
Installieren Sie zunächst Streamlit, die Milvus-Client-Bibliothek und die OpenAI-Client-Bibliothek lokal:
pip install streamlit pymilvus openai
Um ein einfaches Unterstützungsformular zu rendern, erstellen Sie eine Python-Datei basic_support_form.py:
import streamlit as st
with st.form("my_form"):
st.write("Submit a support case")
text_val = st.text_area("Describe your problem")
submitted = st.form_submit_button("Submit")
if submitted:
# TODO check for related support cases and articles
st.write("Submitted!")
Um Ihre Anwendung auszuführen, verwenden Sie Streamlit run:
streamlit run basic_support_form.py
Dadurch wird ein einfaches Formular gerendert:
Backend-Abfragedienst einrichten
Als Nächstes wollen wir nach bestehenden offenen Tickets suchen, die relevant sein könnten. Dazu betten wir den Text ein, den der Benutzer mit OpenAI eingegeben hat, und führen dann eine Ähnlichkeitssuche in unserer Sammlung durch, wobei wir nach noch offenen Tickets filtern. Wenn es eines gibt, bei dem der Abstand zwischen dem eingegebenen Ticket und dem bestehenden Ticket sehr gering ist, wird der Benutzer darauf hingewiesen und das Ticket nicht abgeschickt:
import streamlit as st
import os
import pymilvus
import openai
with st.form("my_form"):
st.write("Submit a support case")
text_val = st.text_area("Describe your problem?")
submitted = st.form_submit_button("Submit")
if submitted:
import os
import pymilvus
import openai
org_id = 360033549136 # TODO Load from customer login data
pymilvus.connections.connect(uri=os.environ["MILVUS_URL"], token=os.environ["MILVUS_TOKEN"])
collection = pymilvus.Collection("zendesk")
embedding = openai.Embedding.create(input=text_val, model="text-embedding-ada-002")['data'][0]['embedding']
results = collection.search(data=[embedding], anns_field="vector", param={}, limit=2, output_fields=["_id", "subject", "description"], expr=f'status == "new" and organization_id == {org_id}')
st.write(results[0])
if len(results[0]) > 0 and results[0].distances[0] < 0.35:
matching_ticket = results[0][0].entity
st.write(f"This case seems very similar to {matching_ticket.get('subject')} (id #{matching_ticket.get('_id')}). Make sure it has not been submitted before")
else:
st.write("Submitted!")
Hier geschehen mehrere Dinge:
- Die Verbindung zum Milvus-Cluster wird aufgebaut.
- Der OpenAI-Dienst wird verwendet, um eine Einbettung der vom Benutzer eingegebenen Beschreibung zu erstellen.
- Es wird eine Ähnlichkeitssuche durchgeführt, wobei die Ergebnisse nach dem Ticketstatus und der Organisations-ID gefiltert werden (da nur offene Tickets derselben Organisation relevant sind).
- Wenn es Ergebnisse gibt und der Abstand zwischen den Einbettungsvektoren des bestehenden Tickets und des neu eingegebenen Textes unter einem bestimmten Schwellenwert liegt, wird diese Tatsache angezeigt.
Um die neue App zu starten, müssen Sie zunächst die Umgebungsvariablen für OpenAI und Milvus setzen:
export MILVUS_TOKEN=...
export MILVUS_URL=https://...
export OPENAI_API_KEY=sk-...
streamlit run app.py
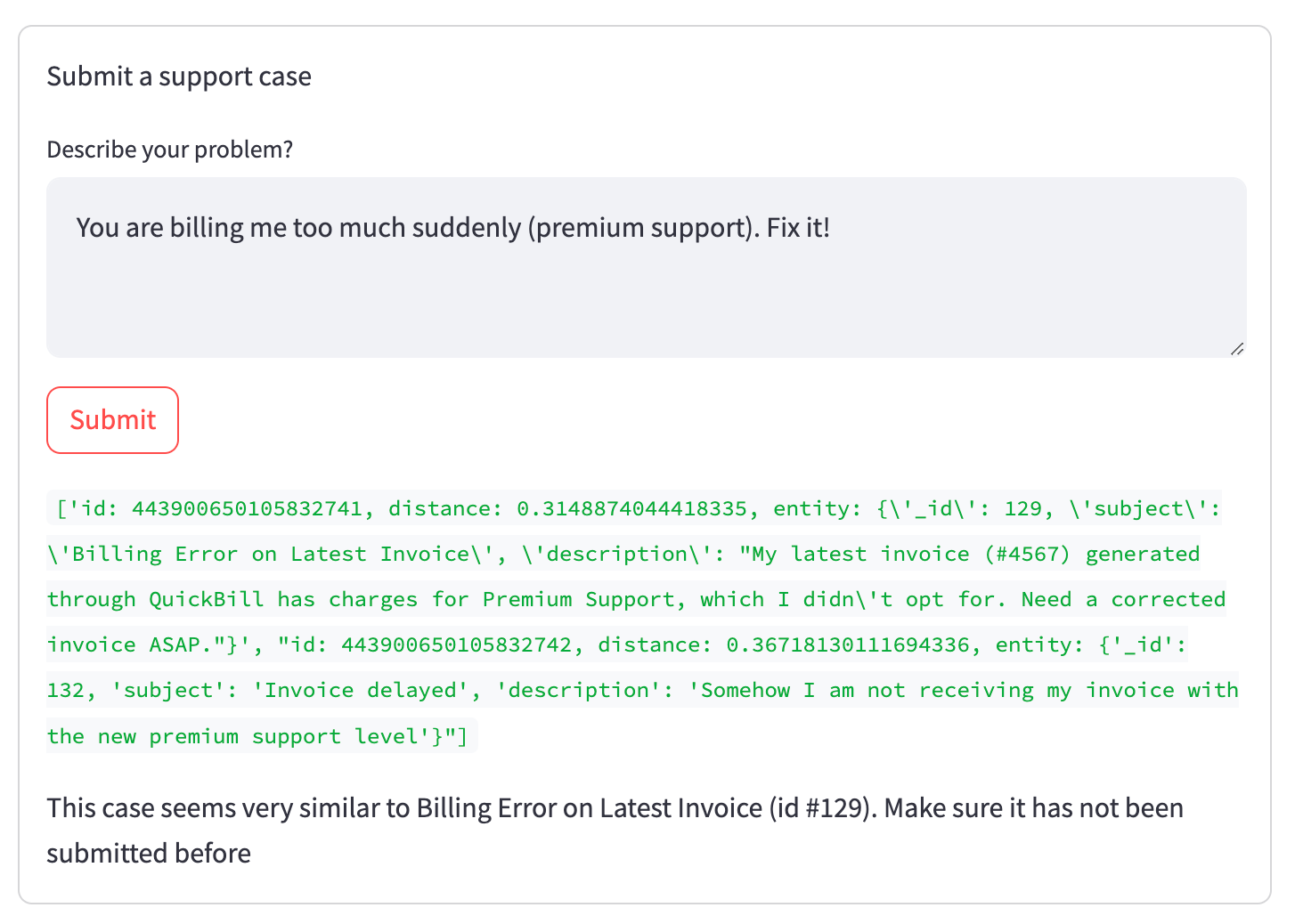
Wenn Sie versuchen, ein bereits bestehendes Ticket einzureichen, sieht das Ergebnis folgendermaßen aus:
Weitere relevante Informationen anzeigen
Wie Sie in der grünen Debug-Ausgabe sehen können, die in der endgültigen Version verborgen ist, entsprachen zwei Tickets unserer Suche (im Status "neu", von der aktuellen Organisation und in der Nähe des Einbettungsvektors). Das erste (relevante) Ticket wurde jedoch höher eingestuft als das zweite (in dieser Situation irrelevant), was sich im niedrigeren Abstandswert widerspiegelt. Diese Beziehung wird in den Einbettungsvektoren erfasst, ohne dass die Wörter direkt miteinander verglichen werden, wie bei einer normalen Volltextsuche.
Um das Ganze abzurunden, sollten wir hilfreiche Informationen anzeigen, nachdem das Ticket eingereicht wurde, um dem Benutzer so viele relevante Informationen wie möglich im Voraus zu geben.
Zu diesem Zweck führen wir eine zweite Suche durch, nachdem das Ticket eingereicht wurde, um die am besten übereinstimmenden Artikel der Wissensdatenbank abzurufen:
......
else:
# TODO Actually send out the ticket
st.write("Submitted!")
article_results = collection.search(data=[embedding], anns_field="vector", param={}, limit=5, output_fields=["title", "html_url"], expr=f'_ab_stream == "articles"')
st.write(article_results[0])
if len(article_results[0]) > 0:
st.write("We also found some articles that might help you:")
for hit in article_results[0]:
if hit.distance < 0.362:
st.write(f"* [{hit.entity.get('title')}]({hit.entity.get('html_url')})")
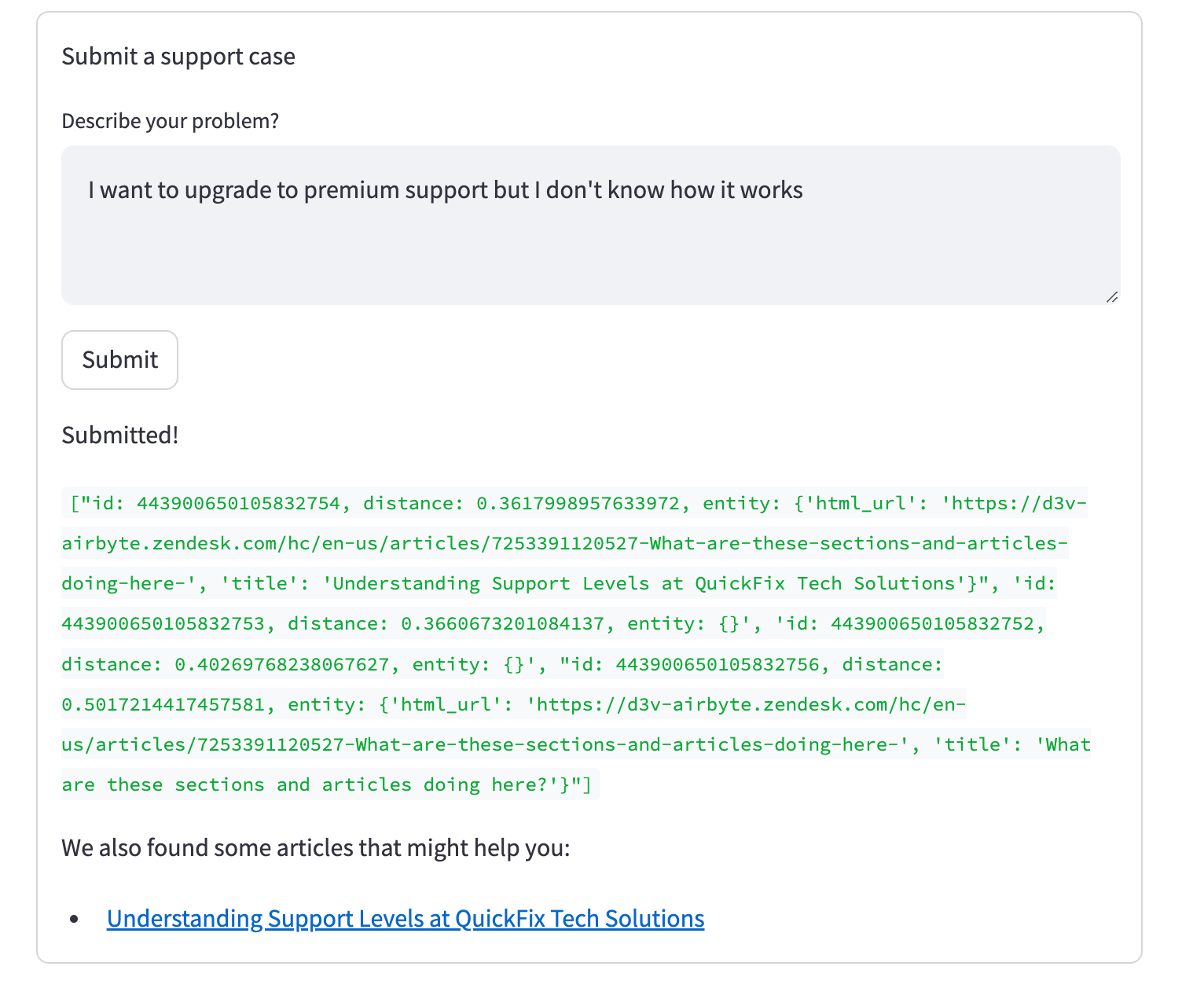
Wenn es kein offenes Support-Ticket mit einer hohen Ähnlichkeitsbewertung gibt, wird das neue Ticket eingereicht und die relevanten Wissensartikel werden unten angezeigt:
Fazit
Auch wenn die hier gezeigte Benutzeroberfläche kein tatsächliches Support-Formular ist, sondern nur ein Beispiel zur Veranschaulichung des Anwendungsfalls, ist die Kombination von Airbyte und Milvus sehr leistungsfähig - sie macht es einfach, Text aus einer Vielzahl von Quellen zu laden (von Datenbanken wie Postgres über APIs wie Zendesk oder GitHub bis hin zu vollständig benutzerdefinierten Quellen, die mit dem SDK von Airbyte oder dem Visual Connector Builder erstellt wurden) und ihn in eingebetteter Form in Milvus zu indizieren, einer leistungsstarken Vektorsuchmaschine, die auf große Datenmengen skalieren kann.
Airbyte und Milvus sind quelloffen und können völlig kostenlos in Ihrer Infrastruktur eingesetzt werden, mit Cloud-Angeboten zur Auslagerung von Operationen, falls gewünscht.
Neben dem klassischen Anwendungsfall der semantischen Suche, der in diesem Artikel dargestellt wird, kann das allgemeine Setup auch für den Aufbau eines Chatbots zur Beantwortung von Fragen nach der RAG-Methode (Retrieval Augmented Generation), für Empfehlungssysteme oder für die Verbesserung der Relevanz und Effizienz von Werbung verwendet werden.