Why and When Do You Need a Purpose-Built Vector Database?

This article was originally published on AIAI and is reposted here with permission.
The increasing popularity of ChatGPT and other large language models (LLMs) has fueled the rise of vector search technologies, including purpose-built vector databases such as Milvus and Zilliz Cloud, vector search libraries such as FAISS, and vector search plugins integrated with traditional databases. However, choosing the best solution for your needs can be challenging. Like choosing between a high-end restaurant and a fast-food chain, selecting the right vector search technology depends on your needs and expectations.
In this post, I will provide an overview of vector search and its functioning, compare different vector search technologies, and explain why opting for a purpose-built vector database is crucial.
What is vector search, and how does it work?
Vector search, also known as vector similarity search, is a technique for retrieving the top-k results that are most similar or semantically related to a given query vector among an extensive collection of dense vector data.
Before conducting similarity searches, we leverage neural networks to transform unstructured data, such as text, images, videos, and audio, into high-dimensional numerical vectors called embedding vectors. For example, we can use the pre-trained ResNet-50 convolutional neural network to transform a bird image into a collection of embeddings with 2,048 dimensions. Here, we list the first three and last three vector elements: [0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909].
 A bird image by Patrice Bouchard
A bird image by Patrice Bouchard
After generating embedding vectors, vector search engines compare the spatial distance between the input query vector and the vectors in the vector stores. The closer they are in space, the more similar they are.
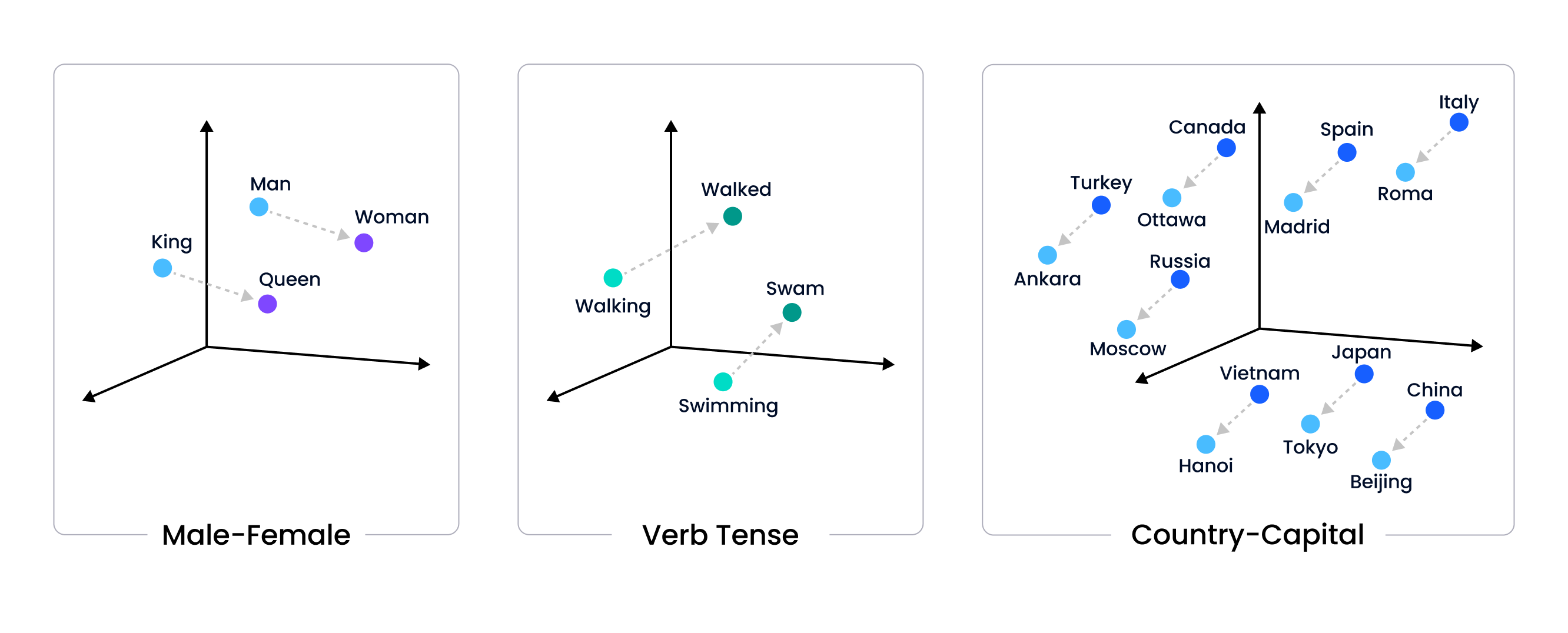 Embedding arithmetic
Embedding arithmetic
Popular vector search technologies
Multiple vector search technologies are available in the market, including machine learning libraries like Python’s NumPy, vector search libraries like FAISS, vector search plugins built on traditional databases, and specialized vector databases like Milvus and Zilliz Cloud.
Machine learning libraries
Using machine learning libraries is the easiest way to implement vector searches. For instance, we can use Python’s NumPy to implement a nearest neighbor algorithm in less than 20 lines of code.
import numpy as np
# Function to calculate euclidean distance
def euclidean_distance(a, b):
return np.linalg.norm(a - b)
# Function to perform knn
def knn(data, target, k):
# Calculate distances between target and all points in the data
distances = [euclidean_distance(d, target) for d in data]
# Combine distances with data indices
distances = np.array(list(zip(distances, np.arange(len(data)))))
# Sort by distance
sorted_distances = distances[distances[:, 0].argsort()]
# Get the top k closest indices
closest_k_indices = sorted_distances[:k, 1].astype(int)
# Return the top k closest vectors
return data[closest_k_indices]
We can generate 100 two-dimensional vectors and find the nearest neighbor to the vector [0.5, 0.5].
# Define some 2D vectors
data = np.random.rand(100, 2)
# Define a target vector
target = np.array([0.5, 0.5])
# Define k
k = 3
# Perform knn
closest_vectors = knn(data, target, k)
# Print the result
print("The closest vectors are:")
print(closest_vectors)
Machine learning libraries, such as Python’s NumPy, offer great flexibility at a low cost. However, they do have some limitations. For instance, they can only handle a small amount of data and do not ensure data persistence.
I only recommend using NumPy or other machine learning libraries for vector search when:
- You need quick prototyping.
- You don’t care about data persistence.
- Your data size is under one million, and you do not require scalar filtering.
- You do not need high performance.
Vector search libraries
Vector search libraries can help you quickly build a high-performance prototype vector search system. FAISS is a typical example. It is open-source and developed by Meta for efficient similarity search and dense vector clustering. FAISS can handle vector collections of any size, even those that cannot be fully loaded into memory. Additionally, FAISS offers tools for evaluation and parameter tuning. Even though written in C++, FAISS provides a Python/NumPy interface.
Below is the code for an example vector search based on FAISS:
import numpy as np
import faiss
# Generate some example data
dimension = 64 # dimension of the vector space
database_size = 10000 # size of the database
query_size = 100 # number of queries to perform
np.random.seed(123) # make the random numbers predictable
# Generating vectors to index in the database (db_vectors)
db_vectors = np.random.random((database_size, dimension)).astype('float32')
# Generating vectors for query (query_vectors)
query_vectors = np.random.random((query_size, dimension)).astype('float32')
# Building the index
index = faiss.IndexFlatL2(dimension) # using the L2 distance metric
print(index.is_trained) # should return True
# Adding vectors to the index
index.add(db_vectors)
print(index.ntotal) # should return database_size (10000)
# Perform a search
k = 4 # we want to see 4 nearest neighbors
distances, indices = index.search(query_vectors, k)
# Print the results
print("Indices of nearest neighbors: \n", indices)
print("\nL2 distances to the nearest neighbors: \n", distances)
Vector search libraries such as FAISS are easy to use and fast enough to handle small-scale production environments with millions of vectors. You can enhance their query performance by utilizing quantization and GPUs and reducing data dimensions.
However, these libraries have some limitations when used in production. For example, FAISS does not support real-time data addition and deletion, remote calls, multiple languages, scalar filtering, scalability, or disaster recovery.
Different types of vector databases
Vector databases have emerged to address the limitations of the libraries above, providing a more comprehensive and practical solution for production applications.
Four types of vector databases are available on the battlefield:
- Existing relational or columnar databases that incorporate a vector search plugin. PG Vector is an example.
- Traditional inverted index search engines with support for dense vector indexing. ElasticSearch is an example.
- Lightweight vector databases built on vector search libraries. Chroma is an example.
- Purpose-built vector databases. This type of database is specifically designed and optimized for vector searching from the bottom up. Purpose-built vector databases typically offer more advanced features, including distributed computing, disaster recovery, and data persistence. Milvus is a primary example.
Not all vector databases are created equal. Each stack has unique advantages and limitations, making them more or less suitable for different applications.
I prefer specialized vector databases over other solutions because they are the most efficient and convenient option, offering numerous unique benefits. In the following sections, I will use Milvus as an example to explain the reasons for my preference.
Key benefits of purpose-built vector databases
Milvus is an open-source, distributed, purpose-built vector database that can store, index, manage, and retrieve billions of embedding vectors. It is also one of the most popular vector databases for LLM retrieval augmented generation. As an exemplary instance of purpose-built vector databases, Milvus shares many unique advantages with its counterparts.
Data Persistence and Cost-Effective Storage
While preventing data loss is the minimum requirement for a database, many single-machine and lightweight vector databases do not prioritize data reliability. By contrast, purpose-built distributed vector databases like Milvus prioritize system resilience, scalability, and data persistence by separating storage and computation.
Moreover, most vector databases that utilize approximate nearest neighbor (ANN) indexes need a lot of memory to perform vector searching, as they load ANN indexes purely into memory. However, Milvus supports disk indexes, making storage over ten times more cost-effective than in-memory indexes.
Optimal Query Performance
A specialized vector database provides optimal query performance compared to other vector search options. For example, Milvus is ten times faster at handling queries than vector search plugins. Milvus uses the ANN algorithm instead of the KNN brutal search algorithm for faster vector searching. Additionally, it shards its indexes, reducing the time it takes to construct an index as the data volume increases. This approach enables Milvus to easily handle billions of vectors with real-time data additions and deletions. In contrast, other vector search add-ons are only suitable for scenarios with fewer than tens of millions of data and infrequent additions and deletions.
Milvus also supports GPU acceleration. Internal testing shows that GPU-accelerated vector indexing can achieve 10,000+ QPS when searching tens of millions of data, which is at least ten times faster than traditional CPU indexing for single-machine query performance.
System Reliability
Many applications use vector databases for online queries that require low query latency and high throughput. These applications demand single-machine failover at the minute level, and some even require cross-region disaster recovery for critical scenarios. Traditional replication strategies based on Raft/Paxos suffer from serious resource waste and need help to pre-shard the data, leading to poor reliability. In contrast, Milvus has a distributed architecture that leverages K8s message queues for high availability, reducing recovery time and saving resources.
Operability and Observability
To better serve enterprise users, vector databases must offer a range of enterprise-level features for better operability and observability. Milvus supports multiple deployment methods, including K8s Operator and Helm chart, docker-compose, and pip install, making it accessible to users with different needs. Milvus also provides a monitoring and alarm system based on Grafana, Prometheus, and Loki, improving its observability. With a distributed cloud-native architecture, Milvus is the industry’s first vector database to support multi-tenant isolation, RBAC, quota limiting, and rolling upgrades. All of these approaches make managing and monitoring Milvus much simpler.
Getting started with Milvus in 3 simple steps within 10 minutes
Building a vector database is a complex task, but using one is as simple as using Numpy and FAISS. Even students unfamiliar with AI can implement vector search based on Milvus in just ten minutes. To experience highly scalable and high-performance vector search services, follow these three steps:
- Deploy Milvus on your server with the help of the Milvus deployment document.
- Implement vector search with just 50 lines of code by referring to the Hello Milvus document.
- Explore the example documents of Towhee to gain insight into popular use cases of vector databases.
- What is vector search, and how does it work?
- Popular vector search technologies
- Machine learning libraries
- Vector search libraries
- Different types of vector databases
- Key benefits of purpose-built vector databases
- Data Persistence and Cost-Effective Storage
- Optimal Query Performance
- System Reliability
- Operability and Observability
- Getting started with Milvus in 3 simple steps within 10 minutes
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



