Stop Building Vanilla RAG: Embrace Agentic RAG with DeepSearcher
The Shift to AI-Powered Search with LLMs and Deep Research
The evolution of search technology has progressed dramatically over the decades—from keyword-based retrieval in the pre-2000s to personalized search experiences in the 2010s. We’re witnessing the emergence of AI-powered solutions capable of handling complex queries requiring in-depth, professional analysis.
OpenAI’s Deep Research exemplifies this shift, using reasoning capabilities to synthesize large amounts of information and generate multi-step research reports. For example, when asked about “What is Tesla’s reasonable market cap?” Deep Research can comprehensively analyze corporate finances, business growth trajectories, and market value estimations.
Deep Research implements an advanced form of the RAG (Retrieval-Augmented Generation) framework at its core. Traditional RAG enhances language model outputs by retrieving and incorporating relevant external information. OpenAI’s approach takes this further by implementing iterative retrieval and reasoning cycles. Instead of a single retrieval step, Deep Research dynamically generates multiple queries, evaluates intermediate results, and refines its search strategy—demonstrating how advanced or agentic RAG techniques can deliver high-quality, enterprise-level content that feels more like professional research than simple question-answering.
DeepSearcher: A Local Deep Research Bringing Agentic RAG to Everyone
Inspired by these advancements, developers worldwide have been creating their own implementations. Zilliz engineers built and open-sourced the DeepSearcher project, which can be considered a local and open-source Deep Research. This project has garnered over 4,900 GitHub stars in less than a month.
DeepSearcher redefines AI-powered enterprise search by combining the power of advanced reasoning models, sophisticated search features, and an integrated research assistant. Integrating local data via Milvus (a high-performance and open-source vector database), DeepSearcher delivers faster, more relevant results while allowing users to swap core models for a customized experience easily.
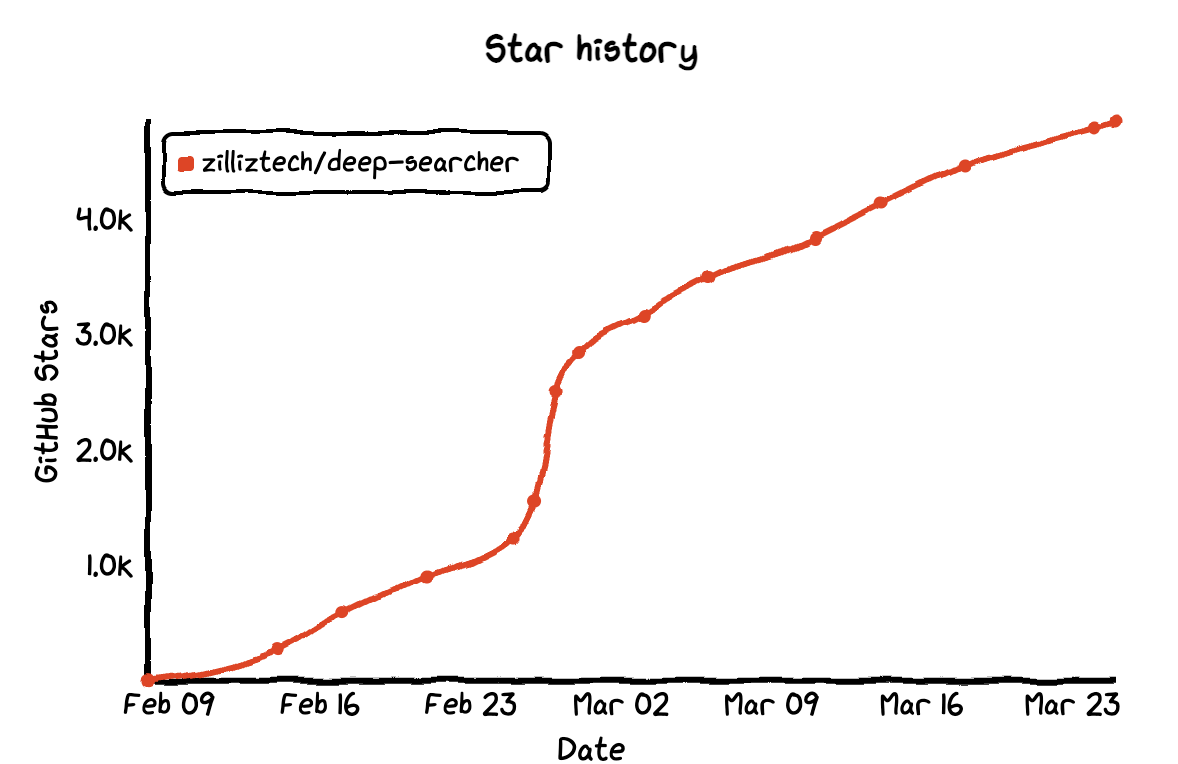
Figure 1: DeepSearcher’s star history (Source)
In this article, we’ll explore the evolution from traditional RAG to Agentic RAG, exploring what specifically makes these approaches different on a technical level. We’ll then discuss DeepSearcher’s implementation, showing how it leverages intelligent agent capabilities to enable dynamic, multi-turn reasoning—and why this matters for developers building enterprise-level search solutions.
From Traditional RAG to Agentic RAG: The Power of Iterative Reasoning
Agentic RAG enhances the traditional RAG framework by incorporating intelligent agent capabilities. DeepSearcher is a prime example of an agentic RAG framework. Through dynamic planning, multi-step reasoning, and autonomous decision-making, it establishes a closed-loop process that retrieves, processes, validates, and optimizes data to solve complex problems.
The growing popularity of Agentic RAG is driven by significant advancements in large language model (LLM) reasoning capabilities, particularly their improved ability to break down complex problems and maintain coherent chains of thought across multiple steps.
| Comparison Dimension | Traditional RAG | Agentic RAG |
| Core Approach | Passive and reactive | Proactive, agent-driven |
| Process Flow | Single-step retrieval and generation (one-time process) | Dynamic, multi-step retrieval and generation (iterative refinement) |
| Retrieval Strategy | Fixed keyword search, dependent on initial query | Adaptive retrieval (e.g., keyword refinement, data source switching) |
| Complex Query Handling | Direct generation; prone to errors with conflicting data | Task decomposition → targeted retrieval → answer synthesis |
| Interaction Capability | Relies entirely on user input; no autonomy | Proactive engagement (e.g., clarifying ambiguities, requesting details) |
| Error Correction & Feedback | No self-correction; limited by initial results | Iterative validation → self-triggered re-retrieval for accuracy |
| Ideal Use Cases | Simple Q&A, factual lookups | Complex reasoning, multi-stage problem-solving, open-ended tasks |
| Example | User asks: “What is quantum computing?” → System returns a textbook definition | User asks: “How can quantum computing optimize logistics?” → System retrieves quantum principles and logistics algorithms, then synthesizes actionable insights |
Unlike traditional RAG, which relies on a single, query-based retrieval, Agentic RAG breaks down a query into multiple sub-questions and iteratively refines its search until it reaches a satisfactory answer. This evolution offers three primary benefits:
Proactive Problem-Solving: The system transitions from passively reacting to actively solving problems.
Dynamic, Multi-Turn Retrieval: Instead of performing a one-time search, the system continually adjusts its queries and self-corrects based on ongoing feedback.
Broader Applicability: It extends beyond basic fact-checking to handle complex reasoning tasks and generate comprehensive reports.
By leveraging these capabilities, Agentic RAG apps like DeepSearcher operate much like a human expert—delivering not only the final answer but also a complete, transparent breakdown of its reasoning process and execution details.
In the long term, Agentic RAG is set to overtake baseline RAG systems. Conventional approaches often struggle to address the underlying logic in user queries, which require iterative reasoning, reflection, and continuous optimization.
What Does an Agentic RAG Architecture Look Like? DeepSearcher as an Example
Now that we’ve understood the power of agentic RAG systems, what does their architecture look like? Let’s take DeepSearcher as an example.
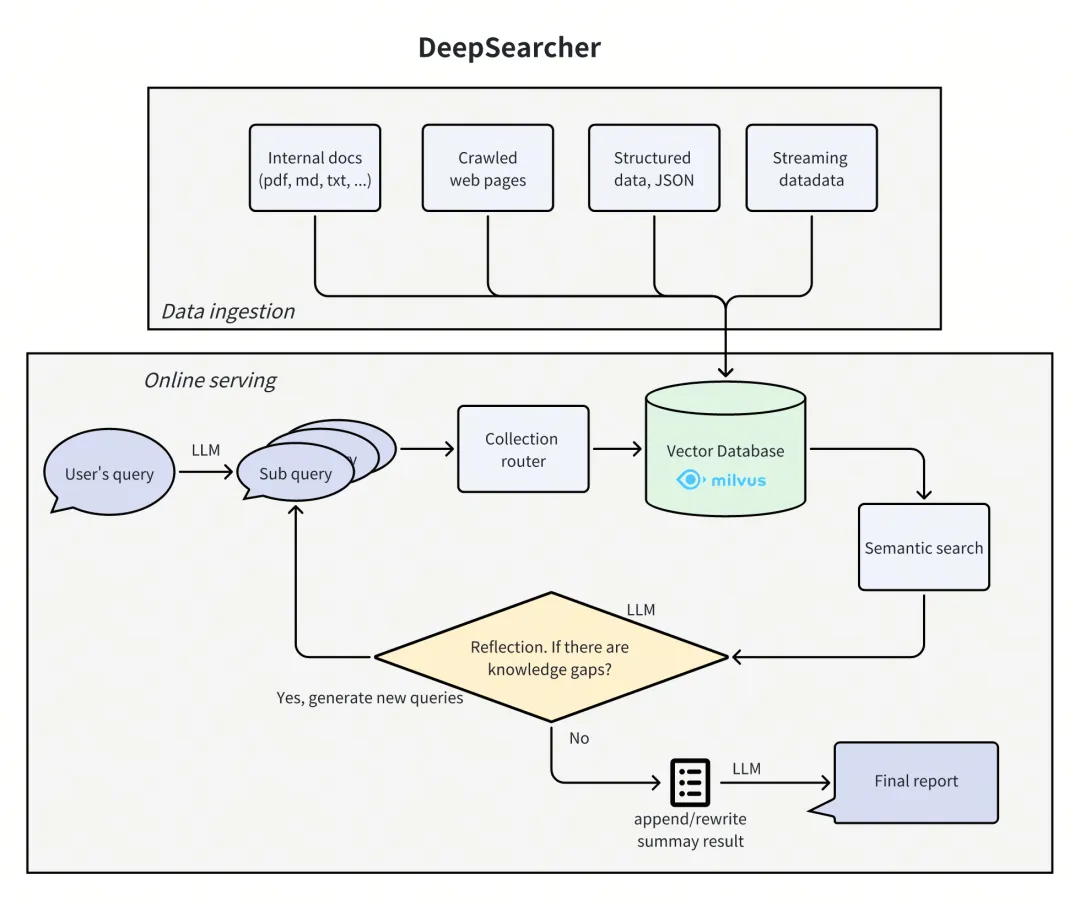
Figure 2: Two Modules Within DeepSearcher
DeepSearcher’s architecture consists of two primary modules:
1. Data Ingestion Module
This module connects various third-party proprietary data sources via a Milvus vector database. It is especially valuable for enterprise environments that rely on proprietary datasets. The module handles:
Document parsing and chunking
Embedding generation
Vector storage and indexing
Metadata management for efficient retrieval
2. Online Reasoning and Query Module
This component implements diverse agent strategies within the RAG framework to deliver precise, insightful responses. It operates on a dynamic, iterative loop—after each data retrieval, the system reflects on whether the accumulated information sufficiently answers the original query. If not, another iteration is triggered; if yes, the final report is generated.
This ongoing cycle of “follow-up” and “reflection” represents a fundamental improvement over other basic RAG approaches. While traditional RAG performs a one-shot retrieval and generation process, DeepSearcher’s iterative approach mirrors how human researchers work—asking initial questions, evaluating the information received, identifying gaps, and pursuing new lines of inquiry.
How Effective is DeepSearcher, and What Use Cases is It Best Suited For?
Once installed and configured, DeepSearcher indexes your local files through the Milvus vector database. When you submit a query, it performs a comprehensive, in-depth search of this indexed content. A key advantage for developers is that the system logs every step of its search and reasoning process, providing transparency into how it arrived at its conclusions—a critical feature for debugging and optimizing RAG systems.
Figure 3: Accelerated Playback of DeepSearcher Iteration
This approach consumes more computational resources than traditional RAG but delivers better results for complex queries. Let’s discuss two specific use cases where DeepSearcher is best suited for.
1. Overview-Type Queries
Overview-type queries—such as generating reports, drafting documents, or summarizing trends—provide a brief topic but require an exhaustive, detailed output.
For example, when querying "How has The Simpsons changed over time?", DeepSearcher first generates an initial set of sub-queries:
_Break down the original query into new sub queries: [_
_'How has the cultural impact and societal relevance of The Simpsons evolved from its debut to the present?',_
_'What changes in character development, humor, and storytelling styles have occurred across different seasons of The Simpsons?',_
_'How has the animation style and production technology of The Simpsons changed over time?',_
_'How have audience demographics, reception, and ratings of The Simpsons shifted throughout its run?']_
It retrieves relevant information, and then iterates with feedback to refine its search, generating the next sub-queries:
_New search queries for next iteration: [_
_"How have changes in The Simpsons' voice cast and production team influenced the show's evolution over different seasons?",_
_"What role has The Simpsons' satire and social commentary played in its adaptation to contemporary issues across decades?",_
_'How has The Simpsons addressed and incorporated shifts in media consumption, such as streaming services, into its distribution and content strategies?']_
Each iteration builds on the previous one, culminating in a comprehensive report that covers multiple facets of the subject, structured with sections like:
**Report: The Evolution of _The Simpsons_ (1989–Present)**
**1. Cultural Impact and Societal Relevance**
_The Simpsons_ debuted as a subversive critique of American middle-class life, gaining notoriety for its bold satire in the 1990s. Initially a countercultural phenomenon, it challenged norms with episodes tackling religion, politics, and consumerism. Over time, its cultural dominance waned as competitors like _South Park_ and _Family Guy_ pushed boundaries further. By the 2010s, the show transitioned from trendsetter to nostalgic institution, balancing legacy appeal with attempts to address modern issues like climate change and LGBTQ+ rights, albeit with less societal resonance.
**2. Character Development and Storytelling Shifts**
Early seasons featured nuanced character arcs (e.g., Lisa’s activism, Marge’s resilience), but later seasons saw "Flanderization" (exaggerating traits, e.g., Homer’s stupidity, Ned Flanders’ piety). Humor evolved from witty, character-driven satire to reliance on pop culture references and meta-humor. Serialized storytelling in early episodes gave way to episodic, gag-focused plots, often sacrificing emotional depth for absurdity.
[...]
**12. Merchandising and Global Reach**
The 1990s merchandise boom (action figures, _Simpsons_-themed cereals) faded, but the franchise persists via collaborations (e.g., _Fortnite_ skins, Lego sets). International adaptations include localized dubbing and culturally tailored episodes (e.g., Japanese _Itchy & Scratchy_ variants).
**Conclusion**
_The Simpsons_ evolved from a radical satire to a television institution, navigating shifts in technology, politics, and audience expectations. While its golden-age brilliance remains unmatched, its adaptability—through streaming, updated humor, and global outreach—secures its place as a cultural touchstone. The show’s longevity reflects both nostalgia and a pragmatic embrace of change, even as it grapples with the challenges of relevance in a fragmented media landscape.
(For brevity, only excerpts of the process and final report are shown)
The final report provides a thorough analysis with proper citations and structured organization.
2. Complex Reasoning Queries
Complex queries involve multiple layers of logic and interconnected entities.
Consider the query: “Which film has the director who is older, God’s Gift To Women or Aldri annet enn bråk?”
While this might seem simple to a human, simple RAG systems struggle with it because the answer isn’t stored directly in the knowledge base. DeepSearcher tackles this challenge by decomposing the query into smaller sub-questions:
["Who is the director of God'S Gift To Women?", 'Who is the director of Aldri annet enn bråk?', 'What are the ages of the respective directors?', 'Which director is older?']
It first retrieves information on the directors of both films,
The director of "God's Gift To Women" is Michael Curtiz, the director of "Aldri annet enn bråk" is Edith Carlmar
then generates sub-queries:
["Find the birthdate of Michael Curtiz, the director of God's Gift To Women", 'Find the birthdate of Edith Carlmar, the director of Aldri annet enn bråk']
and then extracts their birth dates, and finally compares them to determine the correct answer:
The director of "God's Gift To Women" is Michael Curtiz, who was born on December 24, 1886 and passed away on April 11, 1962. He was a Hungarian-born American film director known for his prolific career in Hollywood.
On the other hand, the director of "Aldri annet enn bråk" is Edith Carlmar, who was born on November 15, 1911 and passed away on May 17, 2003.
Therefore, Michael Curtiz is older than Edith Carlmar.
In contrast, a conventional RAG system might miss key details due to limited retrieval in a single pass, potentially resulting in hallucinated or inaccurate answers:
1. **Aldri annet enn bråk** (1954) is directed by **Edith Carlmar**, who was born on November 15, 1911.
2. The related chunks did not provide specific details about the director of "God's Gift to Women." However, if we look at external sources for "God's Gift to Women," the film was directed by **L. M. (Lyman) Steinberg**, who was born on December 19, 1905.
By comparing their birth dates:
- Edith Carlmar: November 15, 1911
- L. M. Steinberg: December 19, 1905
**Conclusion**: L. M. Steinberg, the director of "God's Gift to Women," is older than Edith Carlmar, the director of "Aldri annet enn bråk."
DeepSearcher stands out by performing deep, iterative searches on imported local data. It logs each step of its reasoning process and ultimately delivers a comprehensive and unified report. This makes it particularly effective for overview-type queries—such as generating detailed reports or summarizing trends—and for complex reasoning queries that require breaking down a question into smaller sub-questions and aggregating data through multiple feedback loops.
In the next section, we will compare DeepSearcher with other RAG systems, exploring how its iterative approach and flexible model integration stack up against traditional methods.
Quantitative Comparison: DeepSearcher vs. Traditional RAG
In the DeepSearcher GitHub repository, we’ve made available code for quantitative testing. For this analysis, we used the popular 2WikiMultiHopQA dataset. (Note: We evaluated only the first 50 entries to manage API token consumption, but the overall trends remain clear.)
Recall Rate Comparison
As shown in Figure 4, the recall rate improves significantly as the number of maximum iterations increases:
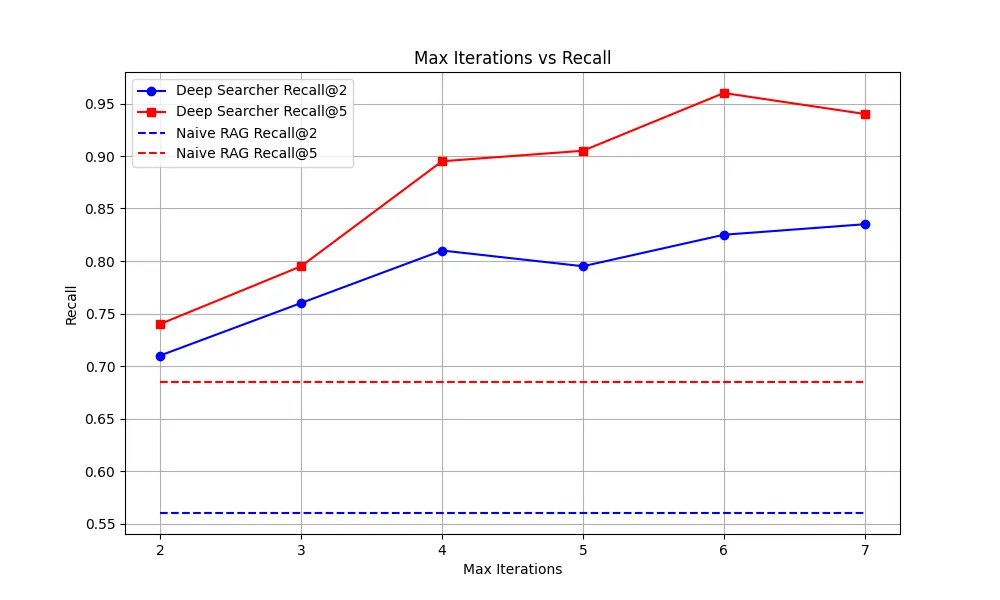
Figure 4: Max Iterations vs. Recall
After a certain point, the marginal improvements taper off—hence, we typically set the default to 3 iterations, though this can be adjusted based on specific needs.
Token Consumption Analysis
We also measured the total token usage for 50 queries across different iteration counts:
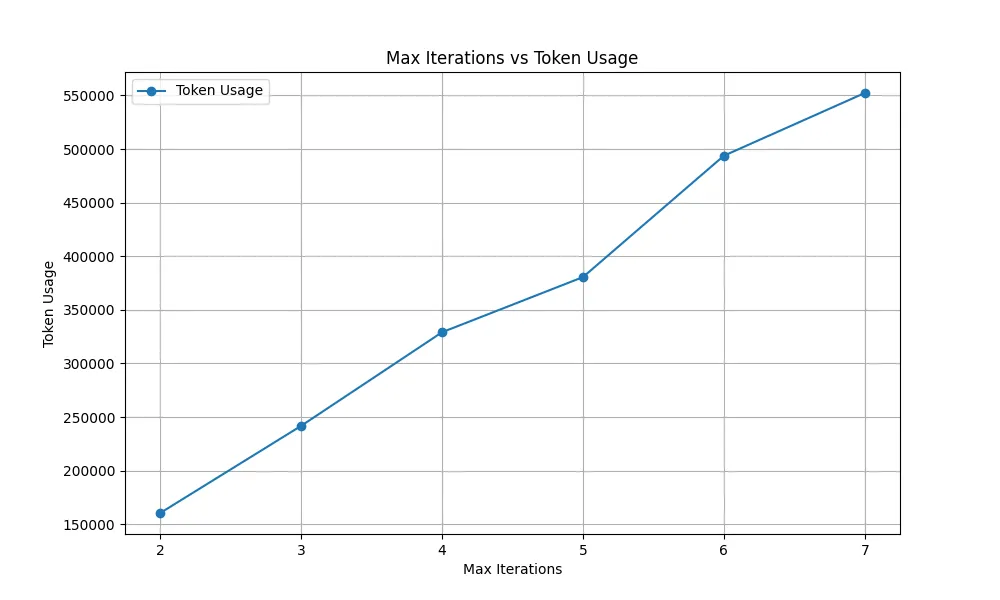
Figure 5: Max Iterations vs. Token Usage
The results show that token consumption increases linearly with more iterations. For example, with 4 iterations, DeepSearcher consumes roughly 0.3M tokens. Using a rough estimate based on OpenAI’s gpt-4o-mini pricing of 0.0036 per query (or roughly $0.18 for 50 queries).
For more resource-intensive inference models, the costs would be several times higher due to both higher per-token pricing and larger token outputs.
Model Performance Comparison
A significant advantage of DeepSearcher is its flexibility in switching between different models. We tested various inference models and non-inference models (like gpt-4o-mini). Overall, inference models—especially Claude 3.7 Sonnet—tended to perform the best, although the differences weren’t dramatic.
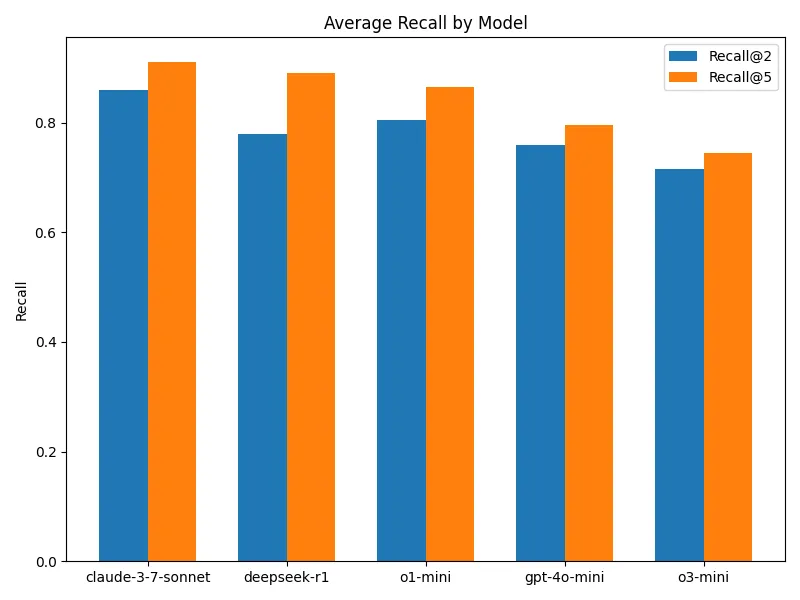
Figure 6: Average Recall by Model
Notably, some smaller non-inference models sometimes couldn’t complete the full agent query process because of their limited ability to follow instructions—a common challenge for many developers working with similar systems.
DeepSearcher (Agentic RAG) vs. Graph RAG
Graph RAG is also able to handle complex queries, particularly multi-hop queries. Then, what is the difference between DeepSearcher (Agentic RAG) and Graph RAG?
Graph RAG is designed to query documents based on explicit relational links, making it particularly strong in multi-hop queries. For instance, when processing a long novel, Graph RAG can precisely extract the intricate relationships between characters. However, this method requires substantial token usage during data import to map out these relationships, and its query mode tends to be rigid—typically effective only for single-relationship queries.
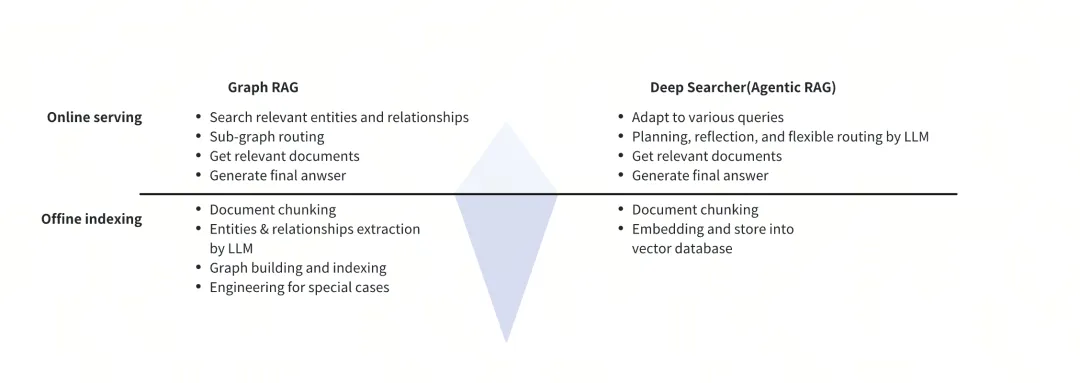
Figure 7: Graph RAG vs. DeepSearcher
In contrast, Agentic RAG—as exemplified by DeepSearcher—takes a fundamentally different approach. It minimizes token consumption during data import and instead invests computational resources during query processing. This design choice creates important technical tradeoffs:
Lower upfront costs: DeepSearcher requires less preprocessing of documents, making initial setup faster and less expensive
Dynamic query handling: The system can adjust its retrieval strategy on-the-fly based on intermediate findings
Higher per-query costs: Each query requires more computation than Graph RAG, but delivers more flexible results
For developers, this distinction is crucial when designing systems with different usage patterns. Graph RAG may be more efficient for applications with predictable query patterns and high query volume, while DeepSearcher’s approach excels in scenarios requiring flexibility and handling unpredictable, complex queries.
Looking ahead, as the cost of LLMs drops and inference performance continues to improve, Agentic RAG systems like DeepSearcher are likely to become more prevalent. The computational cost disadvantage will diminish, while the flexibility advantage will remain.
DeepSearcher vs. Deep Research
Unlike OpenAI’s Deep Research, DeepSearcher is specifically tailored for the deep retrieval and analysis of private data. By leveraging a vector database, DeepSearcher can ingest diverse data sources, integrate various data types, and store them uniformly in a vector-based knowledge repository. Its robust semantic search capabilities enable it to efficiently search through vast amounts of offline data.
Furthermore, DeepSearcher is completely open source. While Deep Research remains a leader in content generation quality, it comes with a monthly fee and operates as a closed-source product, meaning its internal processes are hidden from users. In contrast, DeepSearcher provides full transparency—users can examine the code, customize it to suit their needs, or even deploy it in their own production environments.
Technical Insights
Throughout the development and subsequent iterations of DeepSearcher, we’ve gathered several important technical insights:
Inference Models: Effective but Not Infallible
Our experiments reveal that while inference models perform well as agents, they sometimes overanalyze straightforward instructions, leading to excessive token consumption and slower response times. This observation aligns with the approach of major AI providers like OpenAI, which no longer distinguish between inference and non-inference models. Instead, model services should automatically determine the necessity of inference based on specific requirements to conserve tokens.
The Imminent Rise of Agentic RAG
From a demand perspective, deep content generation is essential; technically, enhancing RAG effectiveness is also crucial. In the long run, cost is the primary barrier to the widespread adoption of Agentic RAG. However, with the emergence of cost-effective, high-quality LLMs like DeepSeek-R1 and the cost reductions driven by Moore’s Law, the expenses associated with inference services are expected to decrease.
The Hidden Scaling Limit of Agentic RAG
A critical finding from our research concerns the relationship between performance and computational resources. Initially, we hypothesized that simply increasing the number of iterations and token allocation would proportionally improve results for complex queries.
Our experiments revealed a more nuanced reality: while performance does improve with additional iterations, we observed clear diminishing returns. Specifically:
Performance increased sharply from 1 to 3 iterations
Improvements from 3 to 5 iterations were modest
Beyond 5 iterations, gains were negligible despite significant increases in token consumption
This finding has important implications for developers: simply throwing more computational resources at RAG systems isn’t the most efficient approach. The quality of the retrieval strategy, the decomposition logic, and the synthesis process often matter more than raw iteration count. This suggests that developers should focus on optimizing these components rather than just increasing token budgets.
The Evolution Beyond Traditional RAG
Traditional RAG offers valuable efficiency with its low-cost, single-retrieval approach, making it suitable for straightforward question-answering scenarios. Its limitations become apparent, however, when handling queries with complex implicit logic.
Consider a user query like “How to earn 100 million in a year.” A traditional RAG system might retrieve content about high-earning careers or investment strategies, but would struggle to:
Identify unrealistic expectations in the query
Break down the problem into feasible sub-goals
Synthesize information from multiple domains (business, finance, entrepreneurship)
Present a structured, multi-path approach with realistic timelines
This is where Agentic RAG systems like DeepSearcher show their strength. By decomposing complex queries and applying multi-step reasoning, they can provide nuanced, comprehensive responses that better address the user’s underlying information needs. As these systems become more efficient, we expect to see their adoption accelerate across enterprise applications.
Conclusion
DeepSearcher represents a significant evolution in RAG system design, offering developers a powerful framework for building more sophisticated search and research capabilities. Its key technical advantages include:
Iterative reasoning: The ability to break down complex queries into logical sub-steps and progressively build toward comprehensive answers
Flexible architecture: Support for swapping underlying models and customizing the reasoning process to suit specific application needs
Vector database integration: Seamless connection to Milvus for efficient storage and retrieval of vector embeddings from private data sources
Transparent execution: Detailed logging of each reasoning step, enabling developers to debug and optimize system behavior
Our performance testing confirms that DeepSearcher delivers superior results for complex queries compared to traditional RAG approaches, though with clear tradeoffs in computational efficiency. The optimal configuration (typically around 3 iterations) balances accuracy against resource consumption.
As LLM costs continue to decrease and reasoning capabilities improve, the Agentic RAG approach implemented in DeepSearcher will become increasingly practical for production applications. For developers working on enterprise search, research assistants, or knowledge management systems, DeepSearcher offers a powerful open-source foundation that can be customized to specific domain requirements.
We welcome contributions from the developer community and invite you to explore this new paradigm in RAG implementation by checking out our GitHub repository.
- The Shift to AI-Powered Search with LLMs and Deep Research
- DeepSearcher: A Local Deep Research Bringing Agentic RAG to Everyone
- From Traditional RAG to Agentic RAG: The Power of Iterative Reasoning
- What Does an Agentic RAG Architecture Look Like? DeepSearcher as an Example
- 1. Data Ingestion Module
- 2. Online Reasoning and Query Module
- How Effective is DeepSearcher, and What Use Cases is It Best Suited For?
- 1. Overview-Type Queries
- 2. Complex Reasoning Queries
- Quantitative Comparison: DeepSearcher vs. Traditional RAG
- Recall Rate Comparison
- Token Consumption Analysis
- Model Performance Comparison
- DeepSearcher (Agentic RAG) vs. Graph RAG
- DeepSearcher vs. Deep Research
- Technical Insights
- Inference Models: Effective but Not Infallible
- The Imminent Rise of Agentic RAG
- The Hidden Scaling Limit of Agentic RAG
- The Evolution Beyond Traditional RAG
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



