We Benchmarked 20+ Embedding APIs with Milvus: 7 Insights That Will Surprise You
Probably every AI developer has built a RAG system that works perfectly… in their local environment.
You’ve nailed the retrieval accuracy, optimized your vector database, and your demo runs like butter. Then you deploy to production and suddenly:
Your 200ms local queries take 3 seconds for actual users
Colleagues in different regions report completely different performance
The embedding provider you chose for “best accuracy” becomes your biggest bottleneck
What happened? Here’s the performance killer no one benchmarks: embedding API latency.
While MTEB rankings obsess over recall scores and model sizes, they ignore the metric your users feel—how long they wait before seeing any response. We tested every major embedding provider across real-world conditions and discovered extreme latency differences they’ll make you question your entire provider selection strategy.
Spoiler: The most popular embedding APIs aren’t the fastest. Geography matters more than model architecture. And sometimes a 200/month API call.
Why Embedding API Latency Is the Hidden Bottleneck in RAG
When building RAG systems, e-commerce search, or recommendation engines, embedding models are the core component that transforms text into vectors, enabling machines to understand semantics and perform efficient similarity searches. While we typically pre-compute embeddings for document libraries, user queries still require real-time embedding API calls to convert questions into vectors before retrieval, and this real-time latency often becomes the performance bottleneck in the entire application chain.
Popular embedding benchmarks like MTEB focus on recall accuracy or model size, often overlooking the crucial performance metric—API latency. Using Milvus’s TextEmbedding Function, we conducted comprehensive real-world tests on major embedding service providers in North America and Asia.
Embedding latency manifests at two critical stages:
Query-Time Impact
In a typical RAG workflow, when a user asks a question, the system must:
Convert the query to a vector via an embedding API call
Search for similar vectors in Milvus
Feed results and the original question to an LLM
Generate and return the answer
Many developers assume the LLM’s answer generation is the slowest part. However, many LLMs’ streaming output capability creates an illusion of speed—you see the first token quickly. In reality, if your embedding API call takes hundreds of milliseconds or even seconds, it becomes the first—and most noticeable—bottleneck in your response chain.
Data Ingestion Impact
Whether building an index from scratch or performing routine updates, bulk ingestion requires vectorizing thousands or millions of text chunks. If each embedding call experiences high latency, your entire data pipeline slows dramatically, delaying product releases and knowledge base updates.
Both situations make embedding API latency a non-negotiable performance metric for production RAG systems.
Measuring Real-World Embedding API Latency with Milvus
Milvus is an open-source, high-performance vector database that offers a new TextEmbedding Function interface. This feature directly integrates popular embedding models from OpenAI, Cohere, AWS Bedrock, Google Vertex AI, Voyage AI, and many more providers into your data pipeline, streamlining your vector search pipeline with a single call.
Using this new function interface, we tested and benchmarked popular embedding APIs from well-known providers like OpenAI and Cohere, as well as others like AliCloud and SiliconFlow, measuring their end-to-end latency in realistic deployment scenarios.
Our comprehensive test suite covered various model configurations:
| Provider | Model | Dimensions |
|---|---|---|
| OpenAI | text-embedding-ada-002 | 1536 |
| OpenAI | text-embedding-3-small | 1536 |
| OpenAI | text-embedding-3-large | 3072 |
| AWS Bedrock | amazon.titan-embed-text-v2:0 | 1024 |
| Google Vertex AI | text-embedding-005 | 768 |
| Google Vertex AI | text-multilingual-embedding-002 | 768 |
| VoyageAI | voyage-3-large | 1024 |
| VoyageAI | voyage-3 | 1024 |
| VoyageAI | voyage-3-lite | 512 |
| VoyageAI | voyage-code-3 | 1024 |
| Cohere | embed-english-v3.0 | 1024 |
| Cohere | embed-multilingual-v3.0 | 1024 |
| Cohere | embed-english-light-v3.0 | 384 |
| Cohere | embed-multilingual-light-v3.0 | 384 |
| Aliyun Dashscope | text-embedding-v1 | 1536 |
| Aliyun Dashscope | text-embedding-v2 | 1536 |
| Aliyun Dashscope | text-embedding-v3 | 1024 |
| Siliconflow | BAAI/bge-large-zh-v1.5 | 1024 |
| Siliconflow | BAAI/bge-large-en-v1.5 | 1024 |
| Siliconflow | netease-youdao/bce-embedding-base_v1 | 768 |
| Siliconflow | BAAI/bge-m3 | 1024 |
| Siliconflow | Pro/BAAI/bge-m3 | 1024 |
| TEI | BAAI/bge-base-en-v1.5 | 768 |
7 Key Findings from Our Benchmarking Results
We tested leading embedding models under varying batch sizes, token lengths, and network conditions, measuring median latency across all scenarios. The results uncover key insights that could reshape how you choose and optimize embedding APIs. Let’s take a look.
1. Global Network Effects Are More Significant Than You Think
The network environment is perhaps the most critical factor affecting embedding API performance. The same embedding API service provider can perform dramatically differently across network environments.
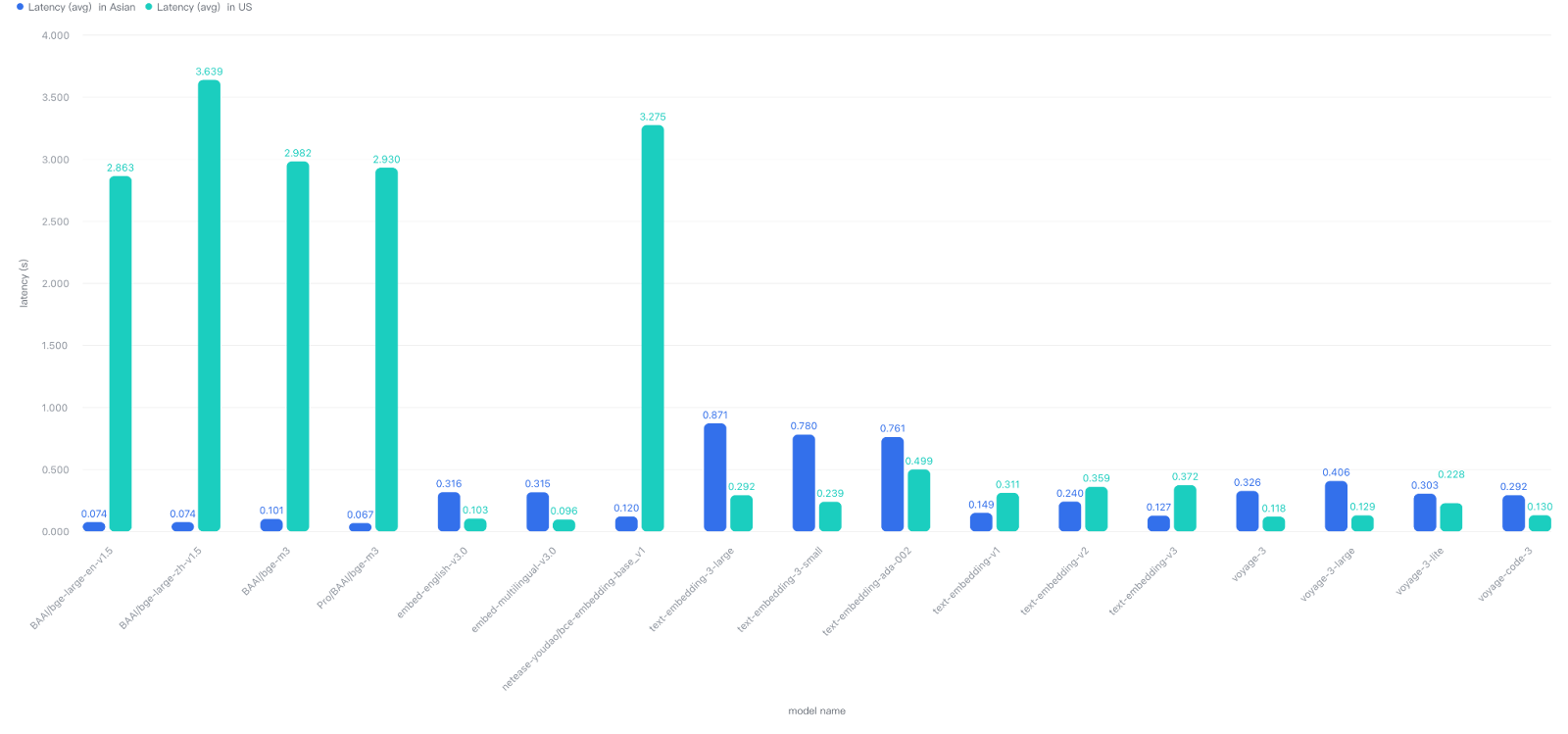
When your application is deployed in Asia and accesses services like OpenAI, Cohere, or VoyageAI deployed in North America, network latency increases significantly. Our real-world tests show API call latency universally increased by 3 to 4 times!
Conversely, when your application is deployed in North America and accesses Asian services like AliCloud Dashscope or SiliconFlow, performance degradation is even more severe. SiliconFlow, in particular, showed latency increases of nearly 100 times in cross-region scenarios!
This means you must always select embedding providers based on your deployment location and user geography—performance claims without network context are meaningless.
2. Model Performance Rankings Reveal Surprising Results
Our comprehensive latency testing revealed clear performance hierarchies:
North America-based Models (median latency): Cohere > Google Vertex AI > VoyageAI > OpenAI > AWS Bedrock
Asia-based Models (median latency): SiliconFlow > AliCloud Dashscope
These rankings challenge conventional wisdom about provider selection.
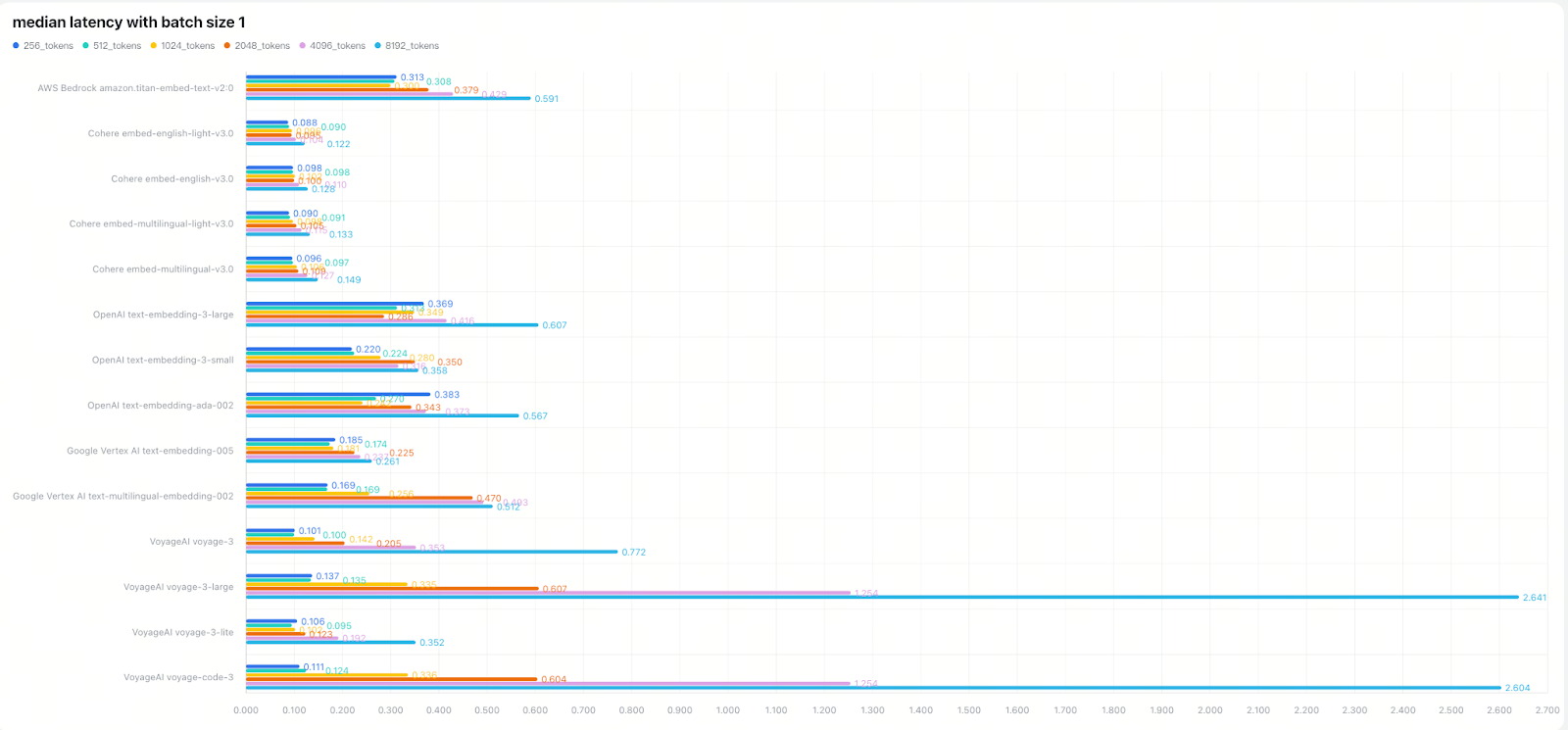
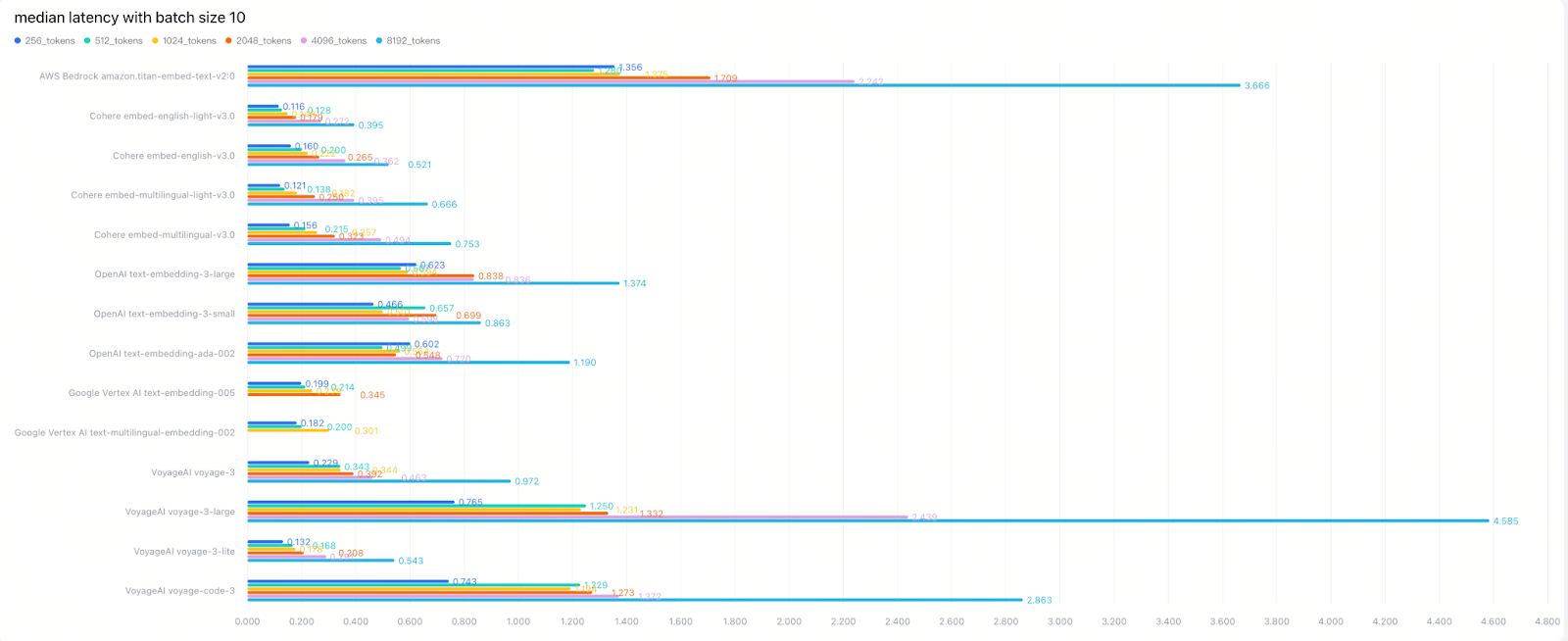
Note: Due to the significant impact of network environment and server geographic regions on real-time embedding API latency, we compared North America and Asia-based model latencies separately.
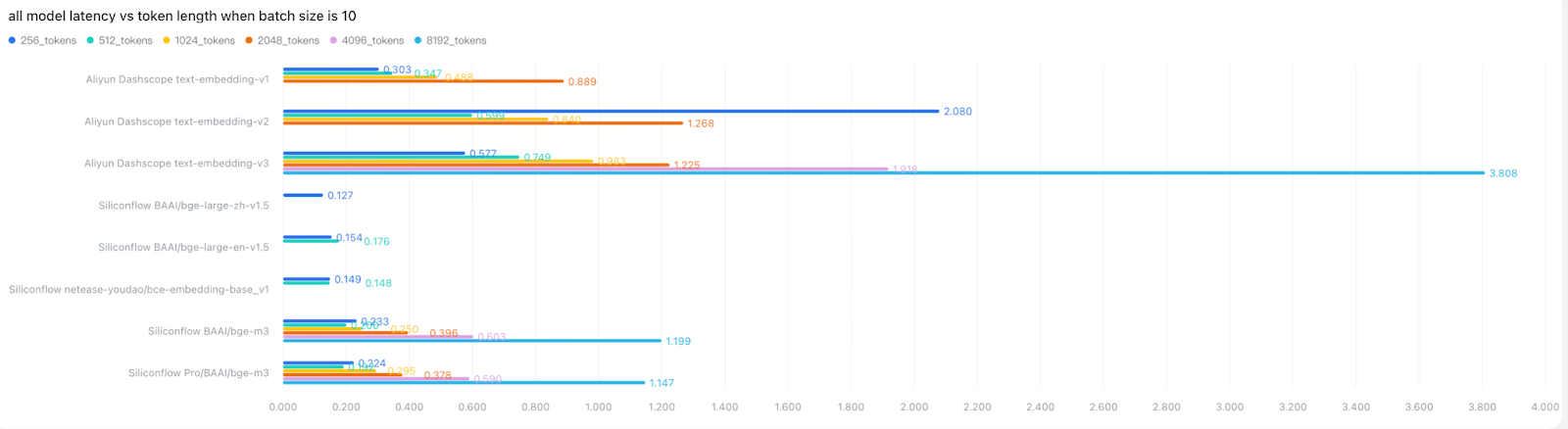
3. Model Size Impact Varies Dramatically by Provider
We observed a general trend where larger models have higher latency than standard models, which have higher latency than smaller/lite models. However, this pattern wasn’t universal and revealed important insights about backend architecture. For example:
Cohere and OpenAI showed minimal performance gaps between model sizes
VoyageAI exhibited clear performance differences based on model size
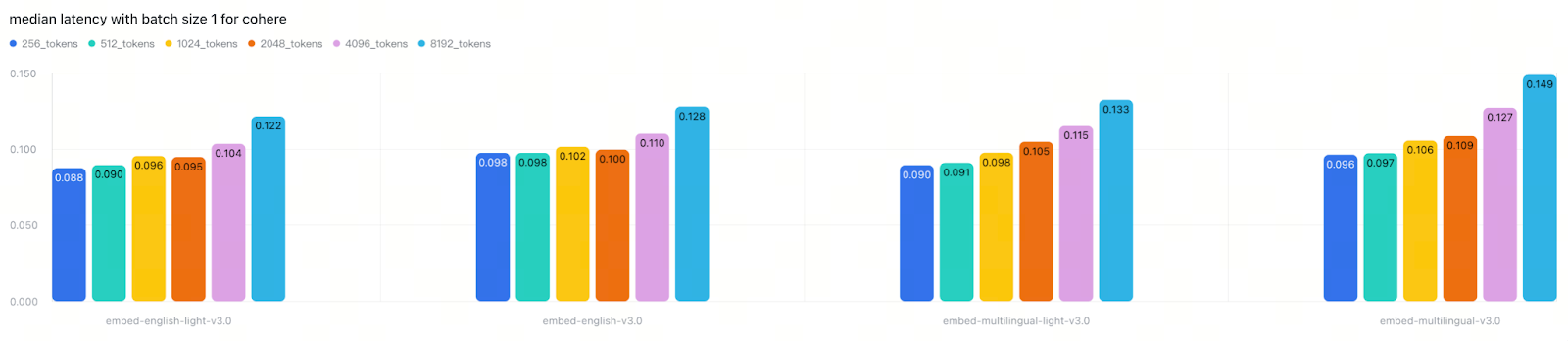
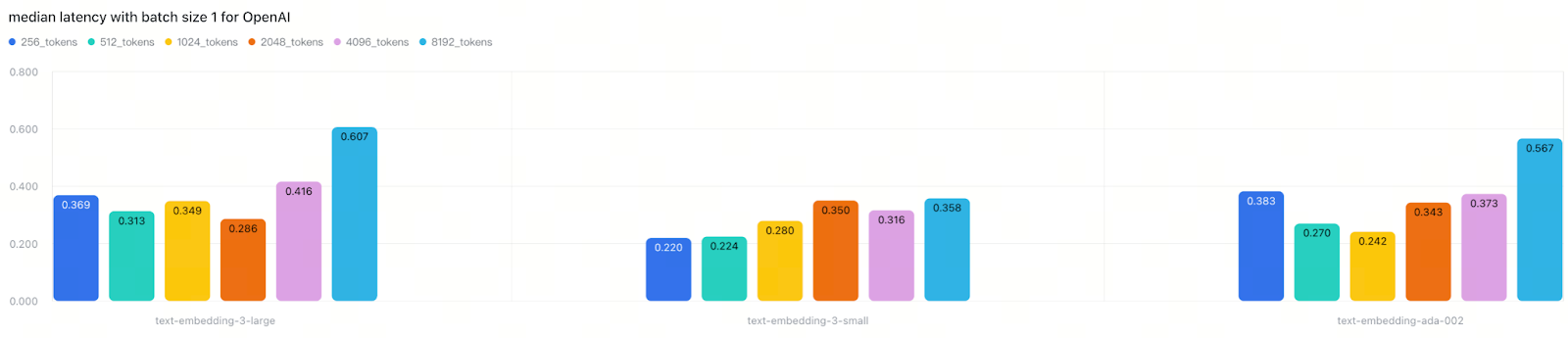
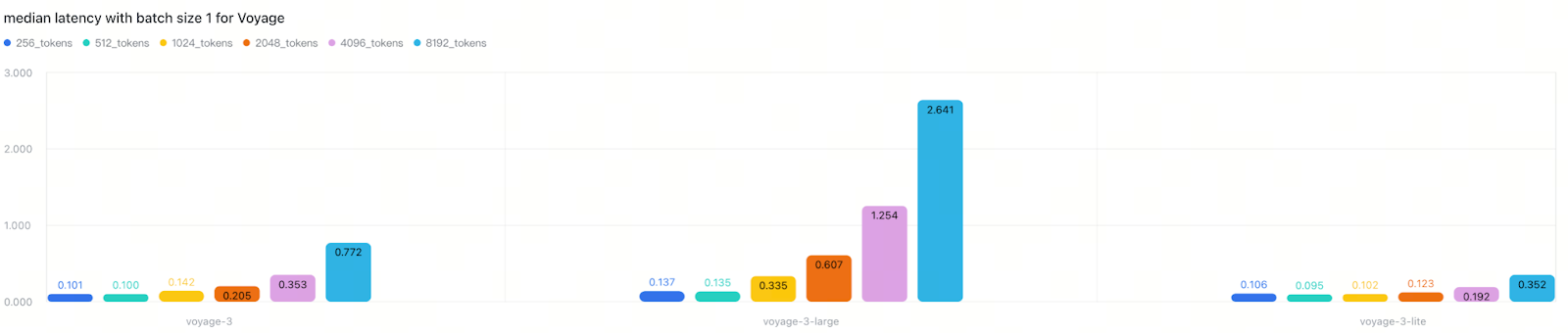
This indicates that API response time depends on multiple factors beyond model architecture, including backend batching strategies, request handling optimization, and provider-specific infrastructure. The lesson is clear: don’t trust model size or release date as reliable performance indicators—always test in your own deployment environment.
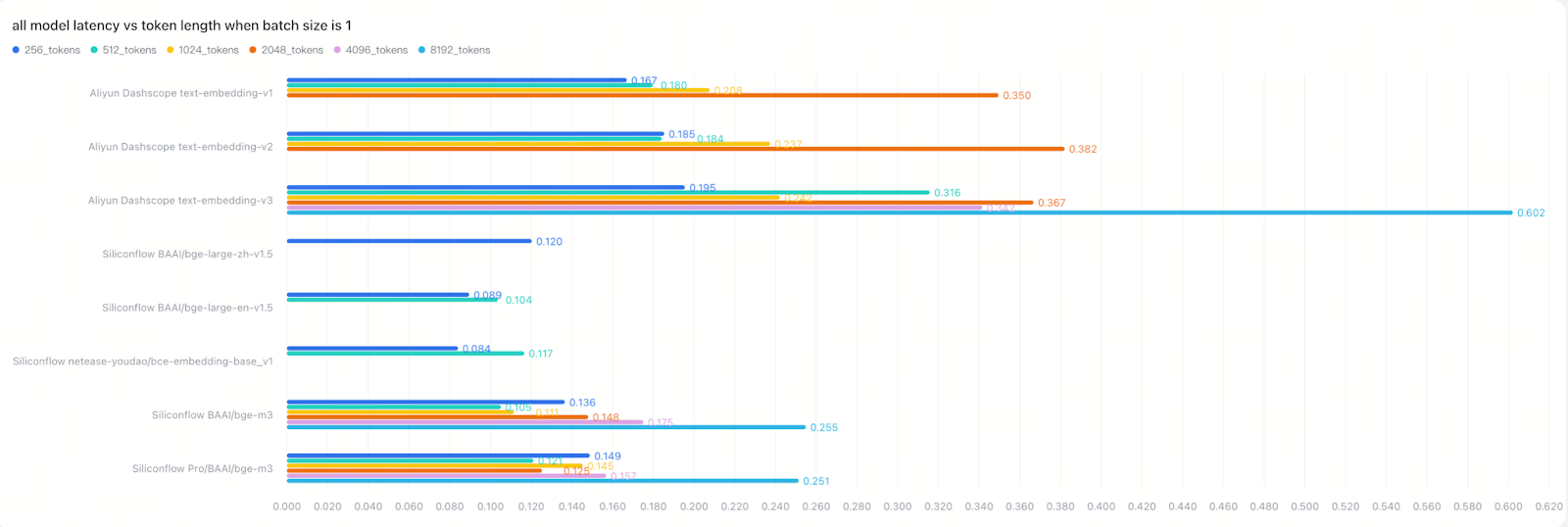
4. Token Length and Batch Size Create Complex Trade-offs
Depending on your backend implementation, especially your batching strategy. Token length may have little impact on latency until batch sizes grow. Our testing revealed some clear patterns:
OpenAI’s latency remained fairly consistent between small and large batches, suggesting generous backend batching capabilities
VoyageAI showed clear token-length effects, implying minimal backend batching optimization
Larger batch sizes increase absolute latency but improve overall throughput. In our tests, moving from batch=1 to batch=10 increased latency by 2×-5×, while substantially boosting total throughput. This represents a critical optimization opportunity for bulk processing workflows where you can trade individual request latency for dramatically improved overall system throughput.
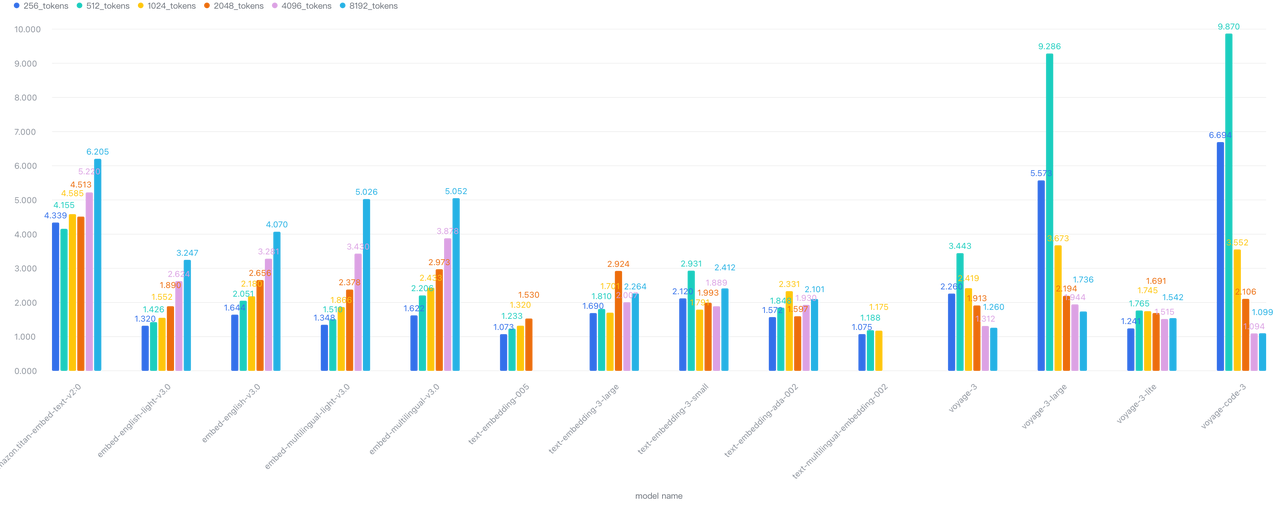
Going from batch=1 to 10, latency increased 2×–5×
5. API Reliability Introduces Production Risk
We observed significant variability in latency, particularly with OpenAI and VoyageAI, introducing unpredictability into production systems.
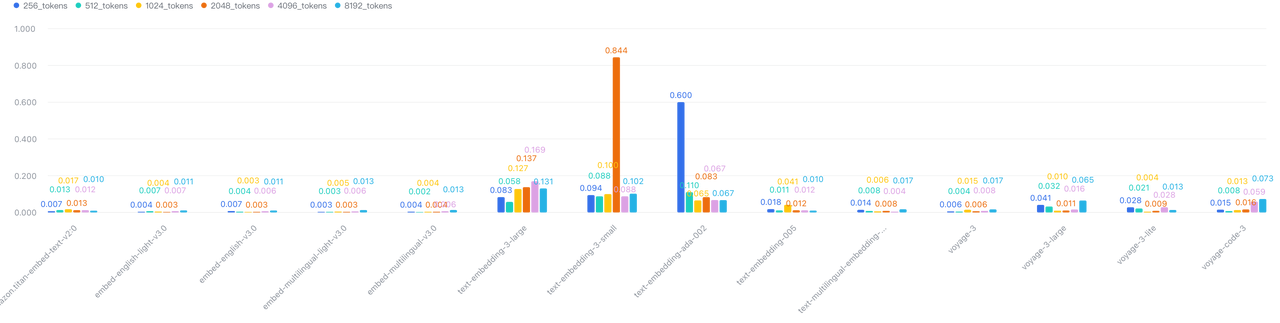
Latency variance when batch=1
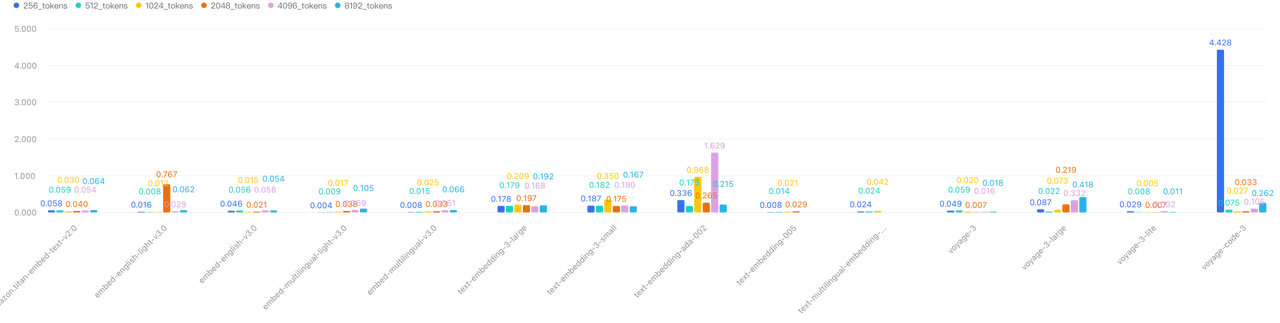
Latency variance when batch=10
While our testing focused primarily on latency, relying on any external API introduces inherent failure risks, including network fluctuations, provider rate limiting, and service outages. Without clear SLAs from providers, developers should implement robust error handling strategies, including retries, timeouts, and circuit breakers to maintain system reliability in production environments.
6. Local Inference Can Be Surprisingly Competitive
Our tests also revealed that deploying mid-sized embedding models locally can offer performance comparable to cloud APIs—a crucial finding for budget-conscious or latency-sensitive applications.
For example, deploying the open-source bge-base-en-v1.5 via TEI (Text Embeddings Inference) on a modest 4c8g CPU matched SiliconFlow’s latency performance, providing an affordable local-inference alternative. This finding is particularly significant for individual developers and small teams who may lack enterprise-grade GPU resources but still need high-performance embedding capabilities.
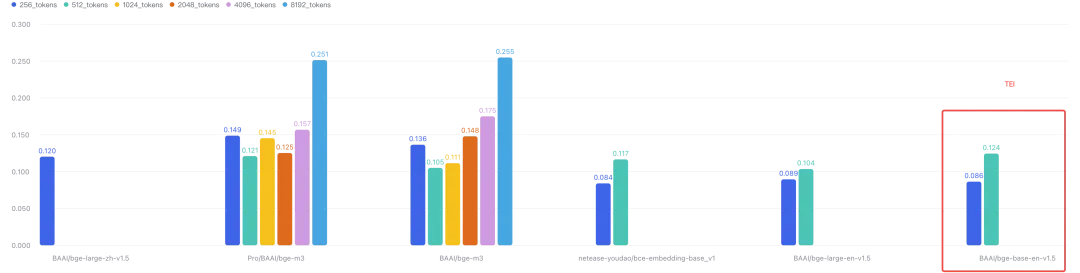
TEI Latency
7. Milvus Overhead Is Negligible
Since we used Milvus to test embedding API latency, we validated that the additional overhead introduced by Milvus’s TextEmbedding Function is minimal and virtually negligible. Our measurements show Milvus operations add only 20-40ms in total while embedding API calls take hundreds of milliseconds to several seconds, meaning Milvus adds less than 5% overhead to the total operation time. The performance bottleneck primarily lies in network transmission and the embedding API service providers’ processing capabilities, not in the Milvus server layer.
Tips: How to Optimize Your RAG Embedding Performance
Based on our benchmarks, we recommend the following strategies to optimize your RAG system’s embedding performance:
1. Always Localize Your Testing
Don’t trust any generic benchmark reports (including this one!). You should always test models within your actual deployment environment rather than relying solely on published benchmarks. Network conditions, geographic proximity, and infrastructure differences can dramatically impact real-world performance.
2. Geo-Match Your Providers Strategically
For North American deployments: Consider Cohere, VoyageAI, OpenAI/Azure, or GCP Vertex AI—and always conduct your own performance validation
For Asian deployments: Seriously consider Asian model providers such as AliCloud Dashscope or SiliconFlow, which offer better regional performance
For global audiences: Implement multi-region routing or select providers with globally distributed infrastructure to minimize cross-region latency penalties
3. Question Default Provider Choices
OpenAI’s embedding models are so popular that many enterprises and developers choose them as default options. However, our tests revealed that OpenAI’s latency and stability were average at best, despite its market popularity. Challenge assumptions about “best” providers with your own rigorous benchmarks—popularity doesn’t always correlate with optimal performance for your specific use case.
4. Optimize Batch and Chunk Configurations
One configuration doesn’t fit all models or use cases. The optimal batch size and chunk length vary significantly between providers due to different backend architectures and batching strategies. Experiment systematically with different configurations to find your optimal performance point, considering the throughput vs. latency trade-offs for your specific application requirements.
5. Implement Strategic Caching
For high-frequency queries, cache both the query text and its generated embeddings (using solutions like Redis). Subsequent identical queries can directly hit the cache, reducing latency to milliseconds. This represents one of the most cost-effective and impactful query latency optimization techniques.
6. Consider Local Inference Deployment
If you have extremely high requirements for data ingestion latency, query latency, and data privacy, or if API call costs are prohibitive, consider deploying embedding models locally for inference. Standard API plans often come with QPS limitations, unstable latency, and lack of SLA guarantees—constraints that can be problematic for production environments.
For many individual developers or small teams, the lack of enterprise-grade GPUs is a barrier to local deployment of high-performance embedding models. However, this doesn’t mean abandoning local inference entirely. With high-performance inference engines like Hugging Face’s text-embeddings-inference, even running small to medium-sized embedding models on a CPU can achieve decent performance that may outperform high-latency API calls, especially for large-scale offline embedding generation.
This approach requires careful consideration of trade-offs between cost, performance, and maintenance complexity.
How Milvus Simplifies Your Embedding Workflow
As mentioned, Milvus is not just a high-performance vector database—it also offers a convenient embedding function interface that seamlessly integrates with popular embedding models from various providers such as OpenAI, Cohere, AWS Bedrock, Google Vertex AI, Voyage AI, and more across the world into your vector search pipeline.
Milvus goes beyond vector storage and retrieval with features that streamline embedding integration:
Efficient Vector Management: As a high-performance database built for massive vector collections, Milvus offers reliable storage, flexible indexing options (HNSW, IVF, RaBitQ, DiskANN, and more), and fast, accurate retrieval capabilities.
Streamlined Provider Switching: Milvus offers a
TextEmbeddingFunction interface, allowing you to configure the function with your API keys, switch providers or models instantly, and measure real-world performance without complex SDK integration.End-to-End Data Pipelines: Call
insert()with raw text, and Milvus automatically embeds and stores vectors in one operation, dramatically simplifying your data pipeline code.Text-to-Results in One Call: Call
search()with text queries, and Milvus handles embedding, searching, and returning results—all in a single API call.Provider-Agnostic Integration: Milvus abstracts provider implementation details; just configure your Function and API key once, and you’re ready to go.
Open-Source Ecosystem Compatibility: Whether you generate embeddings via our built-in
TextEmbeddingFunction, local inference, or another method, Milvus provides unified storage and retrieval capabilities.
This creates a streamlined “Data-In, Insight-Out” experience where Milvus handles vector generation internally, making your application code more straightforward and maintainable.
Conclusion: The Performance Truth Your RAG System Needs
The silent killer of RAG performance isn’t where most developers are looking. While teams pour resources into prompt engineering and LLM optimization, embedding API latency quietly sabotages user experience with delays that can be 100x worse than expected. Our comprehensive benchmarks expose the harsh reality: popular doesn’t mean performant, geography matters more than algorithm choice in many cases, and local inference sometimes beats expensive cloud APIs.
These findings highlight a crucial blind spot in RAG optimization. Cross-region latency penalties, unexpected provider performance rankings, and the surprising competitiveness of local inference aren’t edge cases—they’re production realities affecting real applications. Understanding and measuring embedding API performance is essential for delivering responsive user experiences.
Your embedding provider choice is one critical piece of your RAG performance puzzle. By testing in your actual deployment environment, selecting geographically appropriate providers, and considering alternatives like local inference, you can eliminate a major source of user-facing delays and build truly responsive AI applications.
For more details on how we did this benchmarking, check this notebook.
- Why Embedding API Latency Is the Hidden Bottleneck in RAG
- Query-Time Impact
- Data Ingestion Impact
- Measuring Real-World Embedding API Latency with Milvus
- 7 Key Findings from Our Benchmarking Results
- 1. Global Network Effects Are More Significant Than You Think
- 2. Model Performance Rankings Reveal Surprising Results
- 3. Model Size Impact Varies Dramatically by Provider
- 4. Token Length and Batch Size Create Complex Trade-offs
- 5. API Reliability Introduces Production Risk
- 6. Local Inference Can Be Surprisingly Competitive
- 7. Milvus Overhead Is Negligible
- Tips: How to Optimize Your RAG Embedding Performance
- 1. Always Localize Your Testing
- 2. Geo-Match Your Providers Strategically
- 3. Question Default Provider Choices
- 4. Optimize Batch and Chunk Configurations
- 5. Implement Strategic Caching
- 6. Consider Local Inference Deployment
- How Milvus Simplifies Your Embedding Workflow
- Conclusion: The Performance Truth Your RAG System Needs
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



