Efficient Vector Similarity Search in Recommender Workflows Using Milvus with NVIDIA Merlin
This post was first published on NVIDIA Merlin’s Medium channel and edited and reposted here with permission. It was jointly written by Burcin Bozkaya and William Hicks from NVIDIA and Filip Haltmayer and Li Liu from Zilliz.
Introduction
Modern recommender systems (Recsys) consist of training/inference pipelines involving multiple stages of data ingestion, data preprocessing, model training, and hyperparameter-tuning for retrieval, filtering, ranking, and scoring relevant items. An essential component of a recommender system pipeline is the retrieval or discovery of things that are most relevant to a user, particularly in the presence of large item catalogs. This step typically involves an approximate nearest neighbor (ANN) search over an indexed database of low-dimensional vector representations (i.e., embeddings) of product and user attributes created from deep learning models that train on interactions between users and products/services.
NVIDIA Merlin, an open-source framework developed for training end-to-end models to make recommendations at any scale, integrates with an efficient vector database index and search framework. One such framework that has gained much recent attention is Milvus, an open-source vector database created by Zilliz. It offers fast index and query capabilities. Milvus recently added GPU acceleration support that uses NVIDIA GPUs to sustain AI workflows. GPU acceleration support is great news because an accelerated vector search library makes fast concurrent queries possible, positively impacting the latency requirements in today’s recommender systems, where developers expect many concurrent requests. Milvus has over 5M docker pulls, ~23k stars on GitHub (as of September 2023), over 5,000 Enterprise customers, and a core component of many applications (see use cases).
This blog demonstrates how Milvus works with the Merlin Recsys framework at training and inference time. We show how Milvus complements Merlin in the item retrieval stage with a highly efficient top-k vector embedding search and how it can be used with NVIDIA Triton Inference Server (TIS) at inference time (see Figure 1). Our benchmark results show an impressive 37x to 91x speedup with GPU-accelerated Milvus that uses NVIDIA RAFT with the vector embeddings generated by Merlin Models. The code we use to show Merlin-Milvus integration and detailed benchmark results, along with the library that facilitated our benchmark study, are available here.
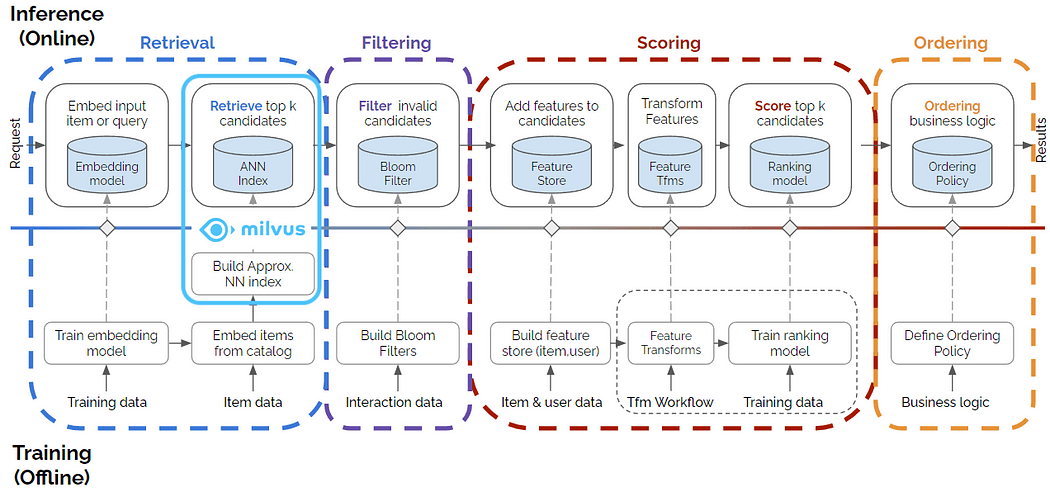
Figure 1. Multistage recommender system with Milvus framework contributing to the retrieval stage. Source for the original multistage figure: this blog post.
The challenges facing recommenders
Given the multistage nature of recommenders and the availability of various components and libraries they integrated, a significant challenge is integrating all components seamlessly in an end-to-end pipeline. We aim to show that integration can be done with less effort in our example notebooks.
Another challenge of recommender workflows is accelerating certain pipeline parts. While known to play a huge role in training large neural networks, GPUs are only recent additions to vector databases and ANN search. With an increasing size of e-commerce product inventories or streaming media databases and the number of users using these services, CPUs must provide the required performance to serve millions of users in performant Recsys workflows. GPU acceleration in other pipeline parts has become necessary to address this challenge. The solution in this blog addresses this challenge by showing that ANN search is efficient when using GPUs.
Tech stacks for the solution
Let’s start by first reviewing some of the fundamentals needed to conduct our work.
NVIDIA Merlin: an open-source library with high-level APIs accelerating recommenders on NVIDIA GPUs.
NVTabular: for pre-processing the input tabular data and feature engineering.
Merlin Models: for training deep learning models, and to learn, in this case, user and item embedding vectors from user interaction data.
Merlin Systems: for combining a TensorFlow-based recommendation model with other elements (e.g., feature store, ANN search with Milvus) to be served with TIS.
Triton Inference Server: for the inference stage where a user feature vector is passed, and product recommendations are generated.
Containerization: all of the above is available via container(s) NVIDIA provides in the NGC catalog. We used the Merlin TensorFlow 23.06 container available here.
Milvus 2.3: for conducting GPU-accelerated vector indexing and querying.
Milvus 2.2.11: same as above, but for doing it on CPU.
Pymilvus SDK: for connecting to the Milvus server, creating vector database indexes, and running queries via a Python interface.
Feast: for saving and retrieving user and item attributes in an (open source) feature store as part of our end-to-end RecSys pipeline.
Several underlying libraries and frameworks are also used under the hood. For example, Merlin relies on other NVIDIA libraries, such as cuDF and Dask, both available under RAPIDS cuDF. Likewise, Milvus relies on NVIDIA RAFT for primitives on GPU acceleration and modified libraries such as HNSW and FAISS for search.
Understanding vector databases and Milvus
Approximate nearest neighbor (ANN) is a functionality that relational databases cannot handle. Relational DBs are designed to handle tabular data with predefined structures and directly comparable values. Relational database indexes rely on this to compare data and create structures that take advantage of knowing if each value is less than or greater than the other. Embedding vectors cannot be directly compared to one another in this fashion, as we need to know what each value in the vector represents. They cannot say if one vector is necessarily less than the other. The only thing that we can do is calculate the distance between the two vectors. If the distance between two vectors is small, we can assume that the features they represent are similar, and if it is large, we can assume that the data they represent are more different. However, these efficient indexes come at a cost; computing the distance between two vectors is computationally expensive, and vector indexes are not readily adaptable and sometimes not modifiable. Due to these two limitations, integrating these indexes is more complex in relational databases, which is why purpose-built vector databases are needed.
Milvus was created to solve the problems that relational databases hit with vectors and was designed from the ground up to handle these embedding vectors and their indexes at a large scale. To fulfill the cloud-native badge, Milvus separates computing and storage and different computing tasks — querying, data wrangling, and indexing. Users can scale each database part to handle other use cases, whether data insert-heavy or search-heavy. If there is a large influx of insertion requests, the user can temporarily scale the index nodes horizontally and vertically to handle the ingestion. Likewise, if no data is being ingested, but there are many searches, the user can reduce the index nodes and instead scale up the query nodes for more throughput. This system design (see Figure 2) required us to think in a parallel computing mindset, resulting in a compute-optimized system with many doors open for further optimizations.
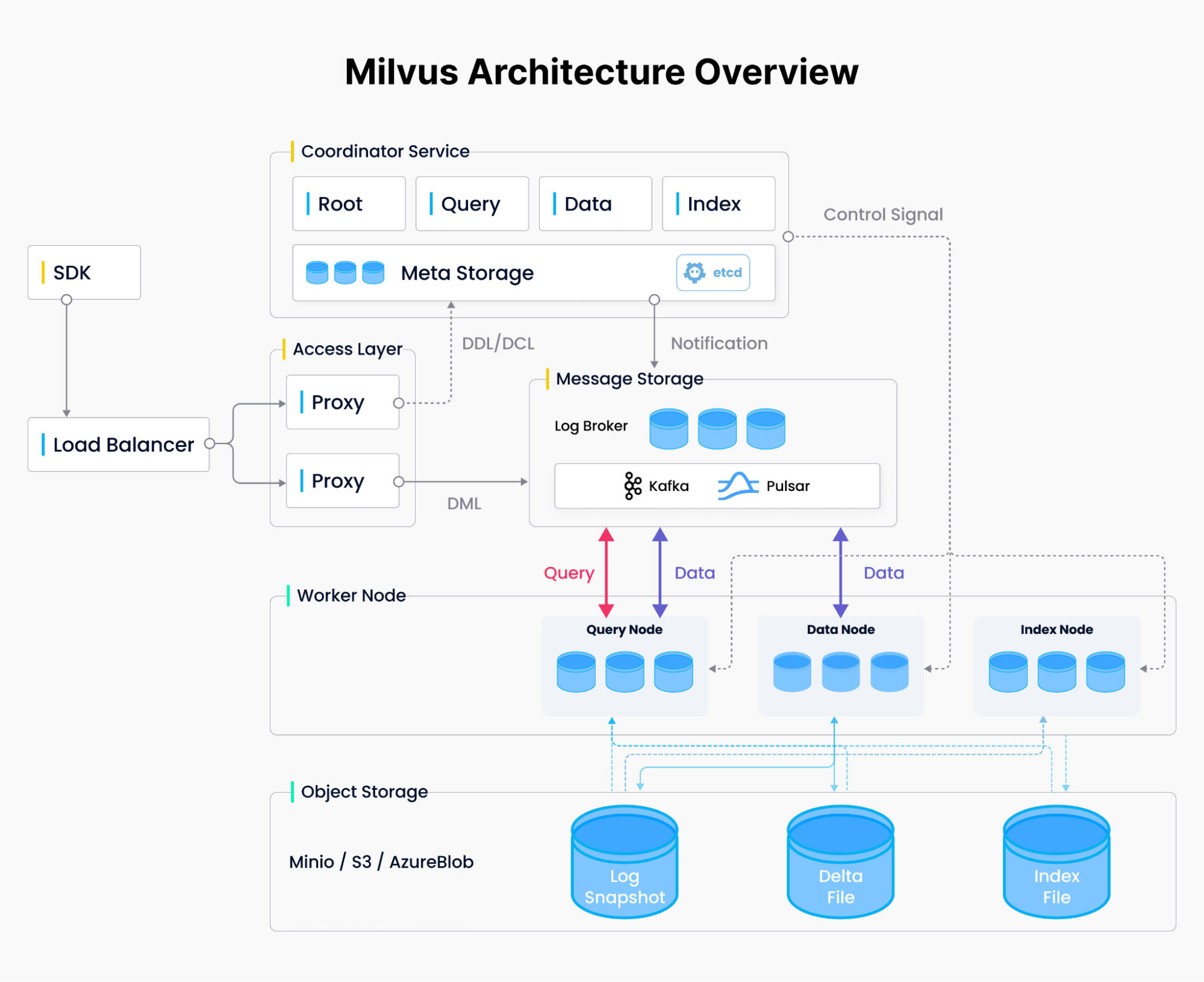
Figure 2. Milvus system design
Milvus also uses many state-of-the-art indexing libraries to give users as much customization for their system as possible. It improves them by adding the ability to handle CRUD operations, streamed data, and filtering. Later on, we will discuss how these indexes differ and what the pros and cons of each are.
Example solution: integration of Milvus and Merlin
The example solution we present here demonstrates the integration of Milvus with Merlin at the item retrieval stage (when the k most relevant items are retrieved through an ANN search). We use a real-life dataset from a RecSys challenge, described below. We train a Two-Tower deep learning model that learns vector embeddings for users and items. This section also provides the blueprint of our benchmarking work, including the metrics we collect and the range of parameters we use.
Our approach involves:
Data ingestion and preprocessing
Two-Tower deep learning model training
Milvus index building
Milvus similarity search
We briefly describe each step and refer the reader to our notebooks for details.
Dataset
YOOCHOOSE GmbH provides the dataset we use in this integration and benchmark study for the RecSys 2015 challenge and is available on Kaggle. It contains user click/buy events from a European online retailer with attributes such as a session ID, timestamp, item ID associated with click/buy, and item category, available in the file yoochoose-clicks.dat. The sessions are independent, and there is no hint of returning users, so we treat each session as belonging to a distinct user. The dataset has 9,249,729 unique sessions (users) and 52,739 unique items.
Data ingestion and preprocessing
The tool we use for data preprocessing is NVTabular, a GPU-accelerated, highly scalable feature engineering and preprocessing component of Merlin. We use NVTabular to read data into GPU memory, rearrange features as necessary, export to parquet files, and create a train-validation split for training. This results in 7,305,761 unique users and 49,008 unique items to train on. We also categorize each column and its values into integer values. The dataset is now ready for training with the Two-Tower model.
Model training
We use the Two-Tower deep learning model to train and generate user and item embeddings, later used in vector indexing and querying. After training the model, we can extract the learned user and item embeddings.
The following two steps are optional: a DLRM model trained to rank the retrieved items for recommendation and a feature store used (in this case, Feast) to store and retrieve user and item features. We include them for the completeness of the multi-stage workflow.
Finally, we export the user and item embeddings to parquet files, which can later be reloaded to create a Milvus vector index.
Building and querying the Milvus index
Milvus facilitates vector indexing and similarity search via a “server” launched on the inference machine. In our notebook #2, we set this up by pip-installing the Milvus server and Pymilvus, then starting the server with its default listening port. Next, we demonstrate building a simple index (IVF_FLAT) and querying against it using the functions setup_milvus and query_milvus, respectively.
Benchmarking
We have designed two benchmarks to demonstrate the case for using a fast and efficient vector indexing/search library such as Milvus.
Using Milvus to build vector indexes with the two sets of embeddings we generated: 1) user embeddings for 7.3M unique users, split as 85% train set (for indexing) and 15% test set (for querying), and 2) item embeddings for 49K products (with a 50–50 train-test split). This benchmark is done independently for each vector dataset, and results are reported separately.
Using Milvus to build a vector index for the 49K item embeddings dataset and querying the 7.3M unique users against this index for similarity search.
In these benchmarks, we used IVFPQ and HNSW indexing algorithms executed on GPU and CPU, along with various combinations of parameters. Details are available here.
The search quality-throughput tradeoff is an important performance consideration, especially in a production environment. Milvus allows complete control over indexing parameters to explore this tradeoff for a given use case to achieve better search results with ground truth. This may mean increased computational cost in the form of reduced throughput rate or queries per second (QPS). We measure the quality of the ANN search with a recall metric and provide QPS-recall curves that demonstrate the tradeoff. One can then decide on an acceptable level of search quality given the compute resources or latency/throughput requirements of the business case.
Also, note the query batch size (nq) used in our benchmarks. This is useful in workflows where multiple simultaneous requests are sent to inference (e.g., offline recommendations requested and sent to a list of email recipients or online recommendations created by pooling concurrent requests arriving and processing them all at once). Depending on the use case, TIS can also help process these requests in batches.
Results
We now report the results for the three sets of benchmarks on both CPU and GPU, using HNSW (CPU only) and IVF_PQ (CPU and GPU) index types implemented by Milvus.
Items vs. Items vector similarity search
With this smallest dataset, each run for a given parameter combination takes 50% of the item vectors as query vectors and queries the top 100 similar vectors from the rest. HNSW and IVF_PQ produce high recall with the parameter settings tested, in the range 0.958–1.0 and 0.665–0.997, respectively. This result suggests that HNSW performs better w.r.t. recall, but IVF_PQ with small nlist settings produces highly comparable recall. We should also note that the recall values can vary greatly depending on the indexing and querying parameters. The values we report have been obtained after preliminary experimentation with general parameter ranges and zooming further into a select subset.
The total time to execute all queries on CPU with HNSW for a given parameter combination ranges between 5.22 and 5.33 sec.s (faster as m gets larger, relatively unchanged with ef) and with IVF_PQ between 13.67 and 14.67 sec.s (slower as nlist and nprobe get larger). GPU acceleration does have a noticeable effect, as seen in Figure 3.
Figure 3 shows the recall-throughput trade-off over all runs completed on CPU and GPU with this small dataset using IVF_PQ. We find that GPU provides a speedup of 4x to 15x across all parameter combinations tested (larger speedup as nprobe gets larger). This is calculated by taking the ratio of QPS from GPU over QPS from CPU runs for each parameter combination. Overall, this set presents a little challenge for CPU or GPU and shows prospects for further speedup with the larger datasets, as discussed below.
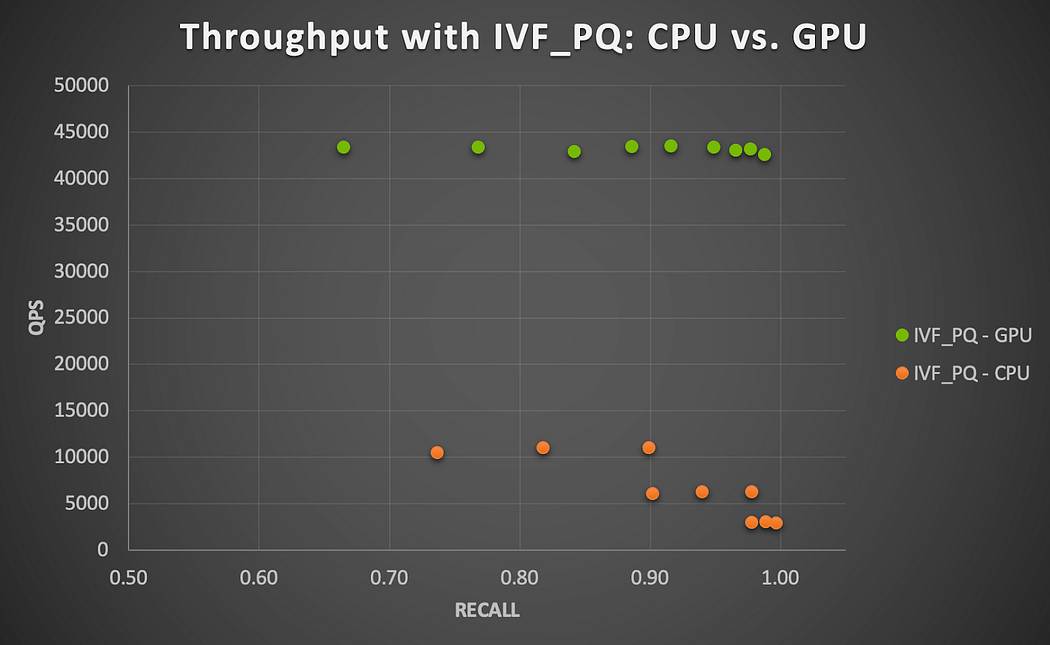
Figure 3. GPU speedup with Milvus IVF_PQ algorithm running on NVIDIA A100 GPU (item-item similarity search)
Users vs. Users vector similarity search
With the much larger second dataset (7.3M users), we set aside 85% (~6.2M) of the vectors as “train” (the set of vectors to be indexed), and the remaining 15% (~1.1M) “test” or query vector set. HNSW and IVF_PQ perform exceptionally well in this case, with recall values of 0.884–1.0 and 0.922–0.999, respectively. They are, however, computationally much more demanding, especially with IVF_PQ on the CPU. The total time to execute all queries on CPU with HNSW ranges from 279.89 to 295.56 sec.s and with IVF_PQ from 3082.67 to 10932.33 sec.s. Note that these query times are cumulative for 1.1M vectors queried, so one can say that a single query against the index is still very fast.
However, CPU-based querying may not be viable if the inference server expects many thousands of concurrent requests to run queries against an inventory of millions of items.
The A100 GPU delivers a blazing speedup of 37x to 91x (averaging 76.1x) across all parameter combinations with IVF_PQ in terms of throughput (QPS), shown in Figure 4. This is consistent with what we observed with the small dataset, which suggests the GPU performance scales reasonably well using Milvus with millions of embedding vectors.
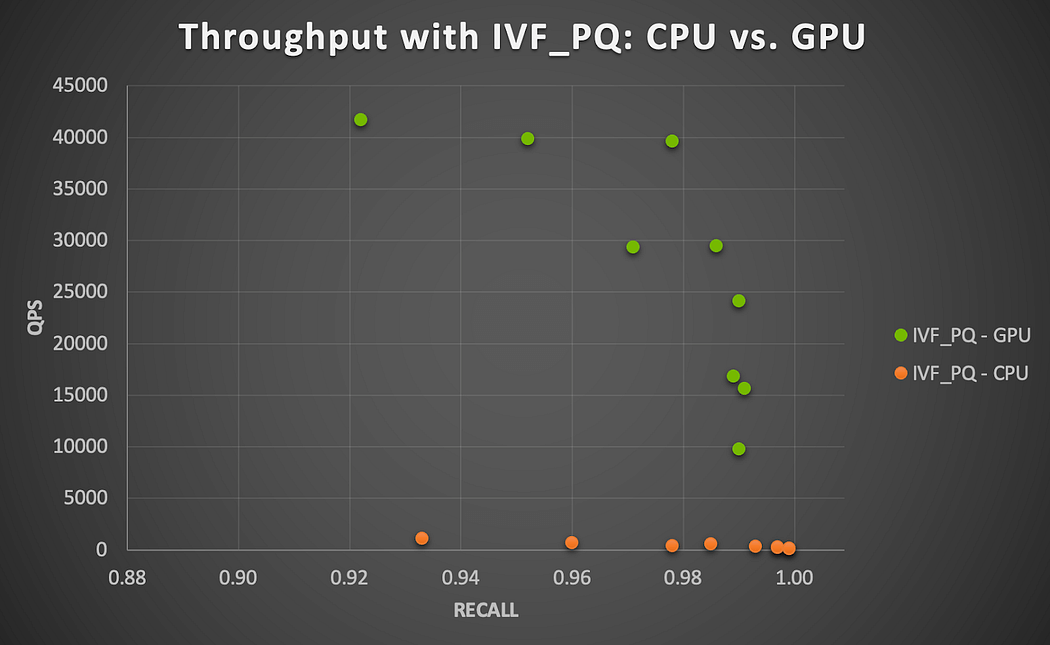
Figure 4. GPU speedup with Milvus IVF_PQ algorithm running on NVIDIA A100 GPU (user-user similarity search)
The following detailed Figure 5 shows the recall-QPS tradeoff for all parameter combinations tested on CPU and GPU with IVF_PQ. Each point set (top for GPU, bottom for CPU) on this chart depicts the tradeoff faced when changing vector indexing/query parameters towards achieving higher recall at the expense of lower throughput. Note the considerable loss of QPS in the GPU case as one tries to achieve higher recall levels.
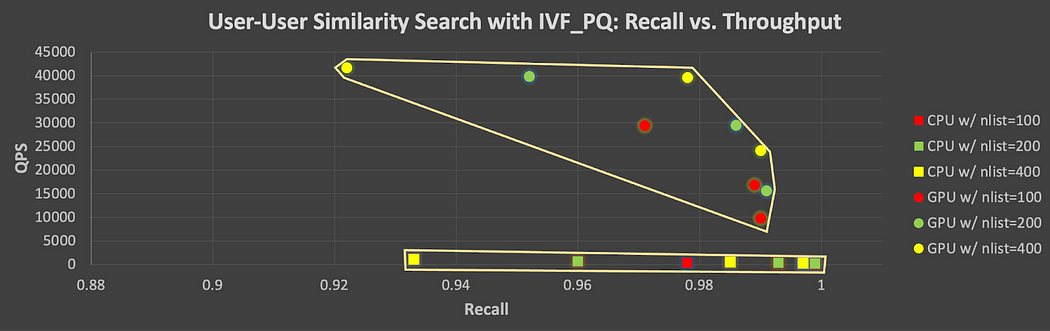
Figure 5. Recall-Throughput tradeoff for all parameter combinations tested on CPU and GPU with IVF_PQ (users vs. users)
Users vs. Items vector similarity search
Finally, we consider another realistic use case where user vectors are queried against item vectors (as demonstrated in Notebook 01 above). In this case, 49K item vectors are indexed, and 7.3M user vectors are each queried for the top 100 most similar items.
This is where things get interesting because querying 7.3M in batches of 1000 against an index of 49K items appears time-consuming on the CPU for both HNSW and IVF_PQ. GPU seems to handle this case better (see Figure 6). The highest accuracy levels by IVF_PQ on CPU when nlist = 100 are computed in about 86 minutes on average but vary significantly as the nprobe value increases (51 min. when nprobe = 5 vs. 128 min. when nprobe = 20). The NVIDIA A100 GPU speeds up the performance considerably by a factor 4x to 17x (higher speedups as nprobe gets larger). Remember that the IVF_PQ algorithm, through its quantization technique, also reduces memory footprint and provides a computationally viable ANN search solution combined with the GPU acceleration.
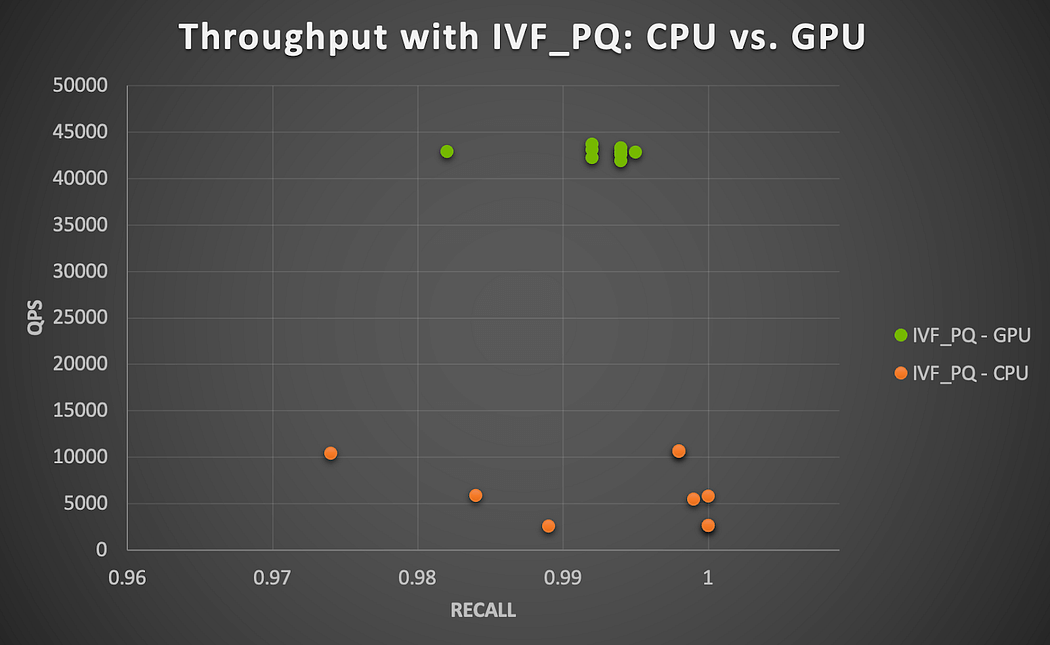
Figure 6. GPU speedup with Milvus IVF_PQ algorithm running on NVIDIA A100 GPU (user-item similarity search)
Similar to Figure 5, the recall-throughput trade-off is shown in Figure 7 for all parameter combinations tested with IVF_PQ. Here, one can still see how one may need to slightly give up some accuracy on ANN search in favor of increased throughput, though the differences are much less noticeable, especially in the case of GPU runs. This suggests that one can expect relatively consistently high levels of computational performance with the GPU while still achieving high recall.
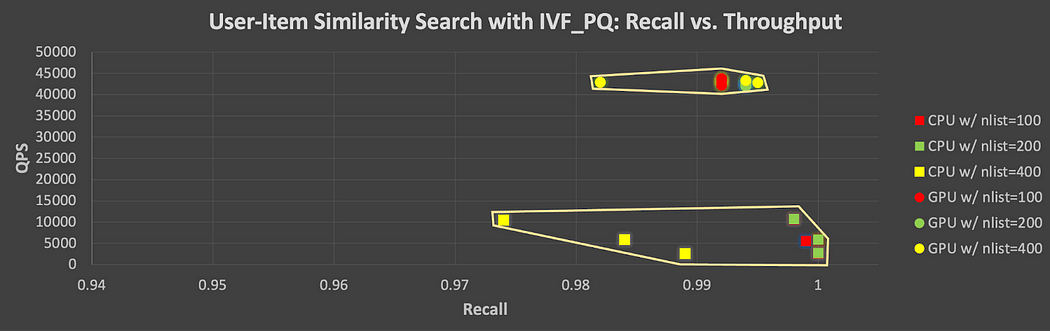
Figure 7. Recall-Throughput tradeoff for all parameter combinations tested on CPU and GPU with IVF_PQ (users vs. items)
Conclusion
We’d happily share a few concluding remarks if you’ve made it this far. We want to remind you that modern Recsys’ complexity and multi-stage nature necessitate performance and efficiency at every step. Hopefully, this blog has given you compelling reasons to consider using two critical features in your RecSys pipelines:
NVIDIA Merlin’s Merlin Systems library allows you to easily plug in Milvus, an efficient GPU-accelerated vector search engine.
Use GPU to accelerate computations for vector database indexing, and ANN search with technology such as RAPIDS RAFT.

These findings suggest that the Merlin-Milvus integration presented is highly performant and much less complex than other options for training and inference. Also, both frameworks are actively developed, and many new features (e.g., new GPU-accelerated vector database indexes by Milvus) are added in every release. The fact that vector similarity search is a crucial component in various workflows, such as computer vision, large language modeling, and recommender systems, makes this effort all the more worthwhile.
In closing, we would like to thank all those from Zilliz/Milvus and Merlin and the RAFT teams who contributed to the effort in producing this work and the blog post. Looking forward to hearing from you, should you have a chance to implement Merlin and Milvus in your recsys or other workflows.
- Introduction
- The challenges facing recommenders
- Tech stacks for the solution
- Understanding vector databases and Milvus
- Example solution: integration of Milvus and Merlin
- Dataset
- Data ingestion and preprocessing
- Model training
- Building and querying the Milvus index
- Benchmarking
- Results
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



