How we used semantic search to make our search 10x smarter
At Tokopedia, we understand that the value in our product corpus is only unlocked when our buyers can find products that are relevant to them, so we strive to improve the relevance of search results.
To further that effort, we are introducing similarity search on Tokopedia. If you go to the search result page on mobile devices, you will find a “…” button that exposes a menu that gives you the option to search for products similar to the product.
Keyword-based search
Tokopedia Search uses Elasticsearch for the search and ranking of products. For each search request, we first query Elasticsearch, which ranks products according to the search query. ElasticSearch stores each word as a sequence of numbers representing ASCII (or UTF) codes for each letter. It builds an inverted-index to quickly find out, which documents contain words from the user query, and then finds the best match among them using various scoring algorithms. These scoring algorithms pay little attention to what the words mean, but rather to how frequently they occur in the document, how close they are to each other, etc. ASCII representation obviously contains enough information to convey the semantics (after all we, humans, can understand it). Unfortunately, there’s no good algorithm for the computer to compare ASCII-encoded words by their meaning.
Vector representation
One solution to this would be to come up with an alternative representation, which tells us not only about the letters contained in the word but also something about its meaning. For example, we could encode which other words our word is frequently used together with (represent by the probable context). We’d then assume that similar contexts represent similar things, and try to compare them using mathematical methods. We could even find a way to encode whole sentences by their meaning.
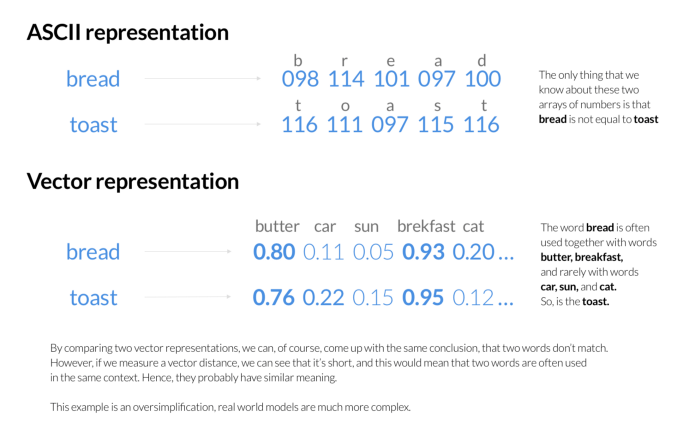 Blog_How we used semantic search to make our search 10x smarter_2.png
Blog_How we used semantic search to make our search 10x smarter_2.png
Select an embedding similarity search engine
Now that we have feature vectors, the remaining issue is how to retrieve from the large volume of vectors the ones that are similar to the target vector. When it comes to the embeddings search engine, we tried POC on several engines available on Github some of them are FAISS, Vearch, Milvus.
We prefer Milvus to other engines based on load test results. On the one hand, we have used FAISS before on other teams and hence would like to try something new. Compared to Milvus, FAISS is more of an underlying library, therefore not quite convenient to use. As we learned more about Milvus, we finally decided to adopt Milvus for its two main features:
Milvus is very easy to use. All you need to do is to pull its Docker image and update the parameters based on your own scenario.
It supports more indexes and has detailed supporting documentation.
In a nutshell, Milvus is very friendly to users and the documentation is quite detailed. If you come across any problem, you can usually find solutions in the documentation; otherwise, you can always get support from the Milvus community.
Milvus cluster service
After deciding to use Milvus as the feature vector search engine, we decided to use Milvus for one of our Ads service use-case where we wanted to match low fill rate keywords with high fill rate keywords. We configured a standalone node in a development (DEV) environment and started serving, it had been running well for a few days, and giving us improved CTR/CVR metrics. If a standalone node crashed in production, the entire service would become unavailable. Thus, we need to deploy a highly available search service.
Milvus provides both Mishards, a cluster sharding middleware, and Milvus-Helm for configuration. In Tokopedia we use Ansible playbooks for infrastructure setup so we created a playbook for infra orchestration. The diagram below from Milvus’ documentation shows how Mishards works:
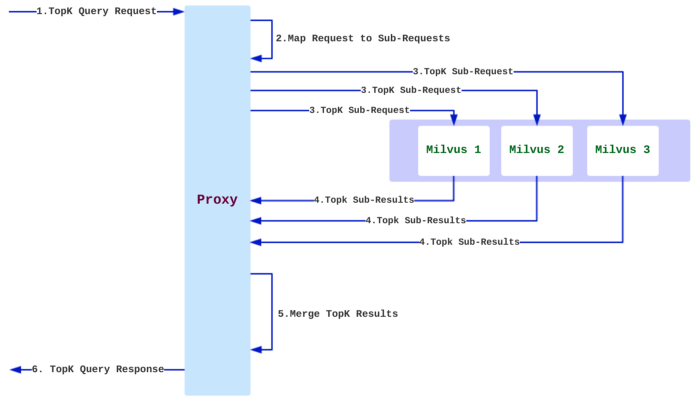 Blog_How we used semantic search to make our search 10x smarter_3.png
Blog_How we used semantic search to make our search 10x smarter_3.png
Mishards cascade a request from upstream down to its sub-modules splitting the upstream request, and then collects and returns the results of the sub-services to upstream. The overall architecture of the Mishards-based cluster solution is shown below:
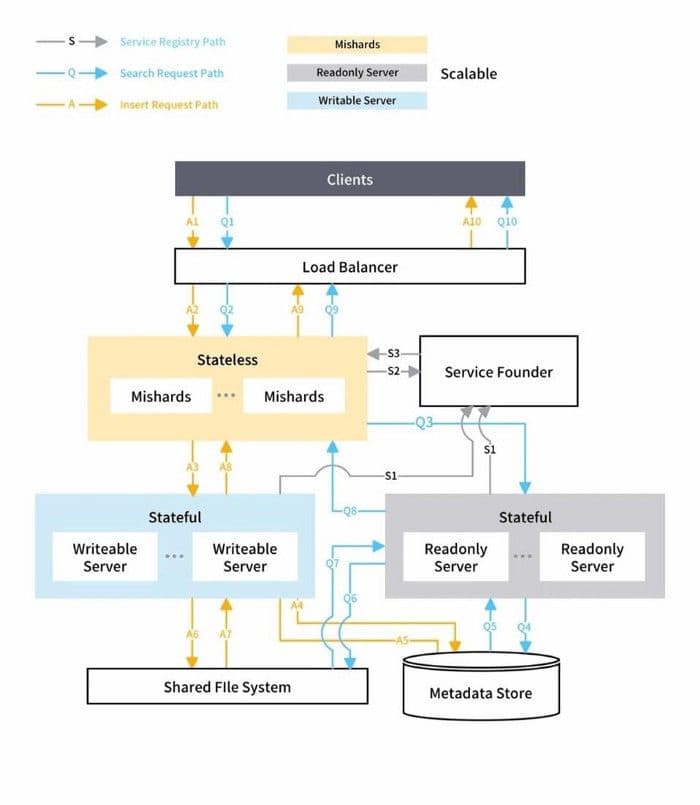 Blog_How we used semantic search to make our search 10x smarter_4.jpeg
Blog_How we used semantic search to make our search 10x smarter_4.jpeg
The official documentation provides a clear introduction of Mishards. You can refer to Mishards if you are interested.
In our keyword-to-keyword service, we deployed one writable node, two read-only nodes, and one Mishards middleware instance in GCP, using Milvus ansible. It has been stable so far. A huge component of what makes it possible to efficiently query the million-, billion-, or even trillion-vector datasets that similarity search engines rely on is indexing, a process of organizing data that drastically accelerates big data search.
How does vector indexing accelerate similarity search?
Similarity search engines work by comparing input to a database to find objects that are most similar to the input. Indexing is the process of efficiently organizing data, and it plays a major role in making similarity search useful by dramatically accelerating time-consuming queries on large datasets. After a massive vector dataset is indexed, queries can be routed to clusters, or subsets of data, that are most likely to contain vectors similar to an input query. In practice, this means a certain degree of accuracy is sacrificed to speed up queries on really big vector data.
An analogy can be drawn to a dictionary, where words are sorted alphabetically. When looking up a word, it is possible to quickly navigate to a section that only contains words with the same initial — drastically accelerating the search for the input word’s definition.
What next, you ask?
 Blog_How we used semantic search to make our search 10x smarter_5.jpeg
Blog_How we used semantic search to make our search 10x smarter_5.jpeg
As shown above, there is no solution that fits all, we always want to improve the model’s performance used for getting the embeddings.
Also, from a technical point of view, we want to run multiple learning models at the same time and compare the results from the various experiments. Watch this space for more information on our experiments like image search, video search.
References:
- Mishards Docs:https://milvus.io/docs/v0.10.2/mishards.md
- Mishards: https://github.com/milvus-io/milvus/tree/master/shards
- Milvus-Helm: https://github.com/milvus-io/milvus-helm/tree/master/charts/milvus
This blog article is reposted from: https://medium.com/tokopedia-engineering/how-we-used-semantic-search-to-make-our-search-10x-smarter-bd9c7f601821
Read other user stories to learn more about making things with Milvus.
Like the article? Spread the word


