How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
TL;DR: We tested 10 embedding models across four production scenarios that public benchmarks miss: cross-modal retrieval, cross-lingual retrieval, key information retrieval, and dimension compression. No single model wins everything. Gemini Embedding 2 is the best all-rounder. Open-source Qwen3-VL-2B beats closed-source APIs on cross-modal tasks. If you need to compress dimensions to save storage, go with Voyage Multimodal 3.5 or Jina Embeddings v4.
Why MTEB Isn’t Enough for Choosing an Embedding Model
Most RAG prototypes start with OpenAI’s text-embedding-3-small. It’s cheap, easy to integrate, and for English text retrieval it works well enough. But production RAG outgrows it fast. Your pipeline picks up images, PDFs, multilingual documents — and a text-only embedding model stops being enough.
The MTEB leaderboard tells you there are better options. The problem? MTEB only tests single-language text retrieval. It doesn’t cover cross-modal retrieval (text queries against image collections), cross-lingual search (a Chinese query finding an English document), long-document accuracy, or how much quality you lose when you truncate embedding dimensions to save storage in your vector database.
So which embedding model should you use? It depends on your data types, your languages, your document lengths, and whether you need dimension compression. We built a benchmark called CCKM and tested 10 models released between 2025 and 2026 across exactly those dimensions.
What Is the CCKM Benchmark?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) tests four capabilities that standard benchmarks miss:
| Dimension | What It Tests | Why It Matters |
|---|---|---|
| Cross-modal retrieval | Match text descriptions to the correct image when near-identical distractors are present | Multimodal RAG pipelines need text and image embeddings in the same vector space |
| Cross-lingual retrieval | Find the correct English document from a Chinese query, and vice versa | Production knowledge bases are often multilingual |
| Key information retrieval | Locate a specific fact buried in a 4K–32K character document (needle-in-a-haystack) | RAG systems frequently process long documents like contracts and research papers |
| MRL dimension compression | Measure how much quality the model loses when you truncate embeddings to 256 dimensions | Fewer dimensions = lower storage cost in your vector database, but at what quality cost? |
MTEB covers none of these. MMEB adds multimodal but skips hard negatives, so models score high without proving they handle subtle distinctions. CCKM is designed to cover what they miss.
Which Embedding Models Did We Test? Gemini Embedding 2, Jina Embeddings v4, and More
We tested 10 models covering both API services and open-source options, plus CLIP ViT-L-14 as a 2021 baseline.
| Model | Source | Parameters | Dimensions | Modality | Key Trait |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Undisclosed | 3072 | Text / image / video / audio / PDF | All-modality, widest coverage | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Text / image / PDF | MRL + LoRA adapters |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Undisclosed | 1024 | Text / image / video | Balanced across tasks |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Text / image / video | Open-source, lightweight multimodal |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Text / image | Modernized CLIP architecture |
| Cohere Embed v4 | Cohere | Undisclosed | Fixed | Text | Enterprise retrieval |
| OpenAI text-embedding-3-large | OpenAI | Undisclosed | 3072 | Text | Most widely used |
| BGE-M3 | BAAI | 568M | 1024 | Text | Open-source, 100+ languages |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Text | Lightweight, English-focused |
| nomic-embed-text | Nomic AI | 137M | 768 | Text | Ultra-lightweight |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Text / image | Baseline |
Cross-Modal Retrieval: Which Models Handle Text-to-Image Search?
If your RAG pipeline handles images alongside text, the embedding model needs to place both modalities in the same vector space. Think e-commerce image search, mixed image-text knowledge bases, or any system where a text query needs to find the right image.
Method
We took 200 image-text pairs from COCO val2017. For each image, GPT-4o-mini generated a detailed description. Then we wrote 3 hard negatives per image — descriptions that differ from the correct one by just one or two details. The model has to find the right match in a pool of 200 images and 600 distractors.
An example from the dataset:
 Vintage brown leather suitcases with travel stickers including California and Cuba, placed on a metal luggage rack against a blue sky — used as a test image in the cross-modal retrieval benchmark
Vintage brown leather suitcases with travel stickers including California and Cuba, placed on a metal luggage rack against a blue sky — used as a test image in the cross-modal retrieval benchmark
Correct description: “The image features vintage brown leather suitcases with various travel stickers including 'California’, 'Cuba’, and 'New York’, placed on a metal luggage rack against a clear blue sky.”
Hard negative: Same sentence, but “California” becomes “Florida” and “blue sky” becomes “overcast sky.” The model has to actually understand the image details to tell these apart.
Scoring:
- Generate embeddings for all images and all text (200 correct descriptions + 600 hard negatives).
- Text-to-image (t2i): Each description searches 200 images for the closest match. Score a point if the top result is correct.
- Image-to-text (i2t): Each image searches all 800 texts for the closest match. Score a point only if the top result is the correct description, not a hard negative.
- Final score: hard_avg_R@1 = (t2i accuracy + i2t accuracy) / 2
Results
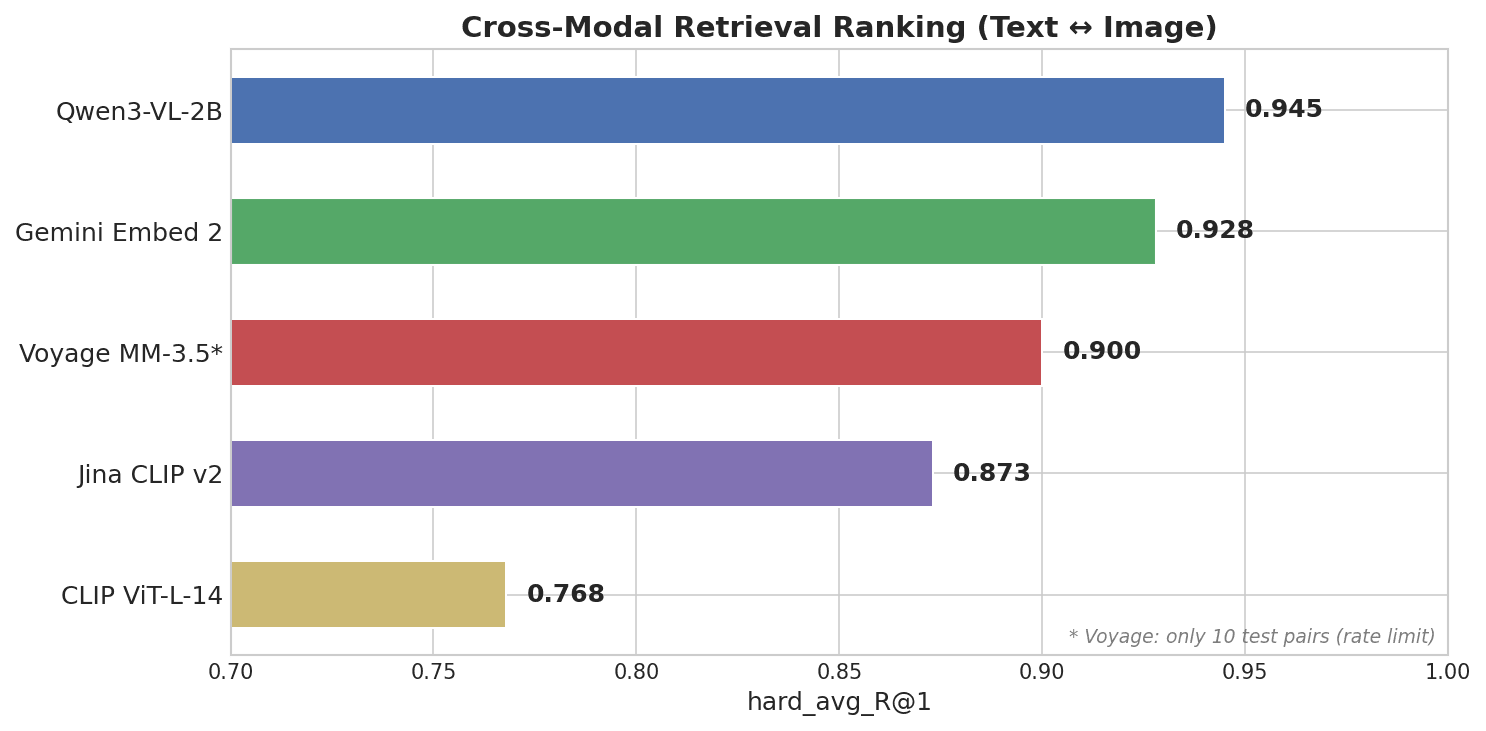 Horizontal bar chart showing Cross-Modal Retrieval Ranking: Qwen3-VL-2B leads at 0.945, followed by Gemini Embed 2 at 0.928, Voyage MM-3.5 at 0.900, Jina CLIP v2 at 0.873, and CLIP ViT-L-14 at 0.768
Horizontal bar chart showing Cross-Modal Retrieval Ranking: Qwen3-VL-2B leads at 0.945, followed by Gemini Embed 2 at 0.928, Voyage MM-3.5 at 0.900, Jina CLIP v2 at 0.873, and CLIP ViT-L-14 at 0.768
Qwen3-VL-2B, an open-source 2B parameter model from Alibaba’s Qwen team, came in first — ahead of every closed-source API.
Modality gap explains most of the difference. Embedding models map text and images into the same vector space, but in practice the two modalities tend to cluster in different regions. The modality gap measures the L2 distance between those two clusters. Smaller gap = easier cross-modal retrieval.
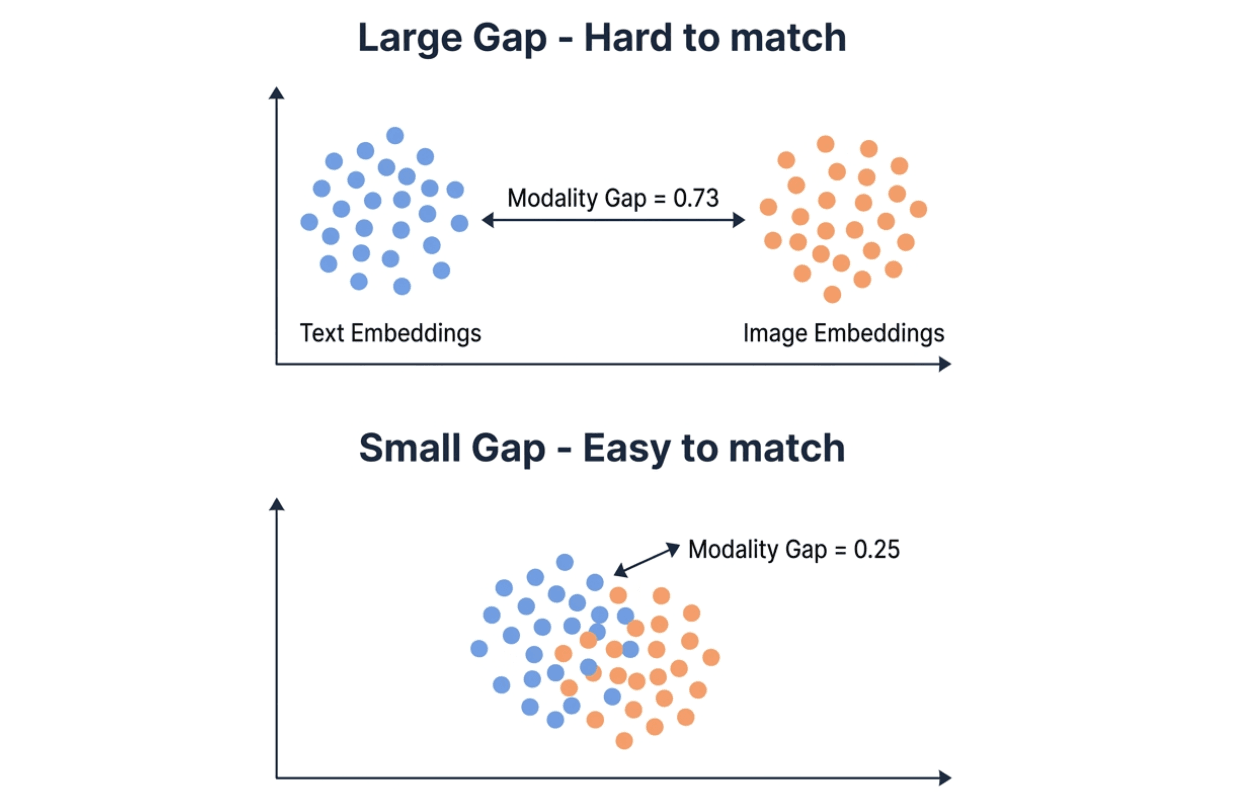 Visualization comparing large modality gap (0.73, text and image embedding clusters far apart) versus small modality gap (0.25, clusters overlapping) — smaller gap makes cross-modal matching easier
Visualization comparing large modality gap (0.73, text and image embedding clusters far apart) versus small modality gap (0.25, clusters overlapping) — smaller gap makes cross-modal matching easier
| Model | Score (R@1) | Modality Gap | Params |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Unknown (closed) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Unknown (closed) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Qwen’s modality gap is 0.25 — roughly a third of Gemini’s 0.73. In a vector database like Milvus, a small modality gap means you can store text and image embeddings in the same collection and search across both directly. A large gap can make cross-modal similarity search less reliable, and you may need a re-ranking step to compensate.
Cross-Lingual Retrieval: Which Models Align Meaning Across Languages?
Multilingual knowledge bases are common in production. A user asks a question in Chinese, but the answer lives in an English document — or the other way around. The embedding model needs to align meaning across languages, not just within one.
Method
We built 166 parallel sentence pairs in Chinese and English across three difficulty levels:
 Cross-lingual difficulty tiers: Easy tier maps literal translations like 我爱你 to I love you; Medium tier maps paraphrased sentences like 这道菜太咸了 to This dish is too salty with hard negatives; Hard tier maps Chinese idioms like 画蛇添足 to gilding the lily with semantically different hard negatives
Cross-lingual difficulty tiers: Easy tier maps literal translations like 我爱你 to I love you; Medium tier maps paraphrased sentences like 这道菜太咸了 to This dish is too salty with hard negatives; Hard tier maps Chinese idioms like 画蛇添足 to gilding the lily with semantically different hard negatives
Each language also gets 152 hard negative distractors.
Scoring:
- Generate embeddings for all Chinese text (166 correct + 152 distractors) and all English text (166 correct + 152 distractors).
- Chinese → English: Each Chinese sentence searches 318 English texts for its correct translation.
- English → Chinese: Same in reverse.
- Final score: hard_avg_R@1 = (zh→en accuracy + en→zh accuracy) / 2
Results
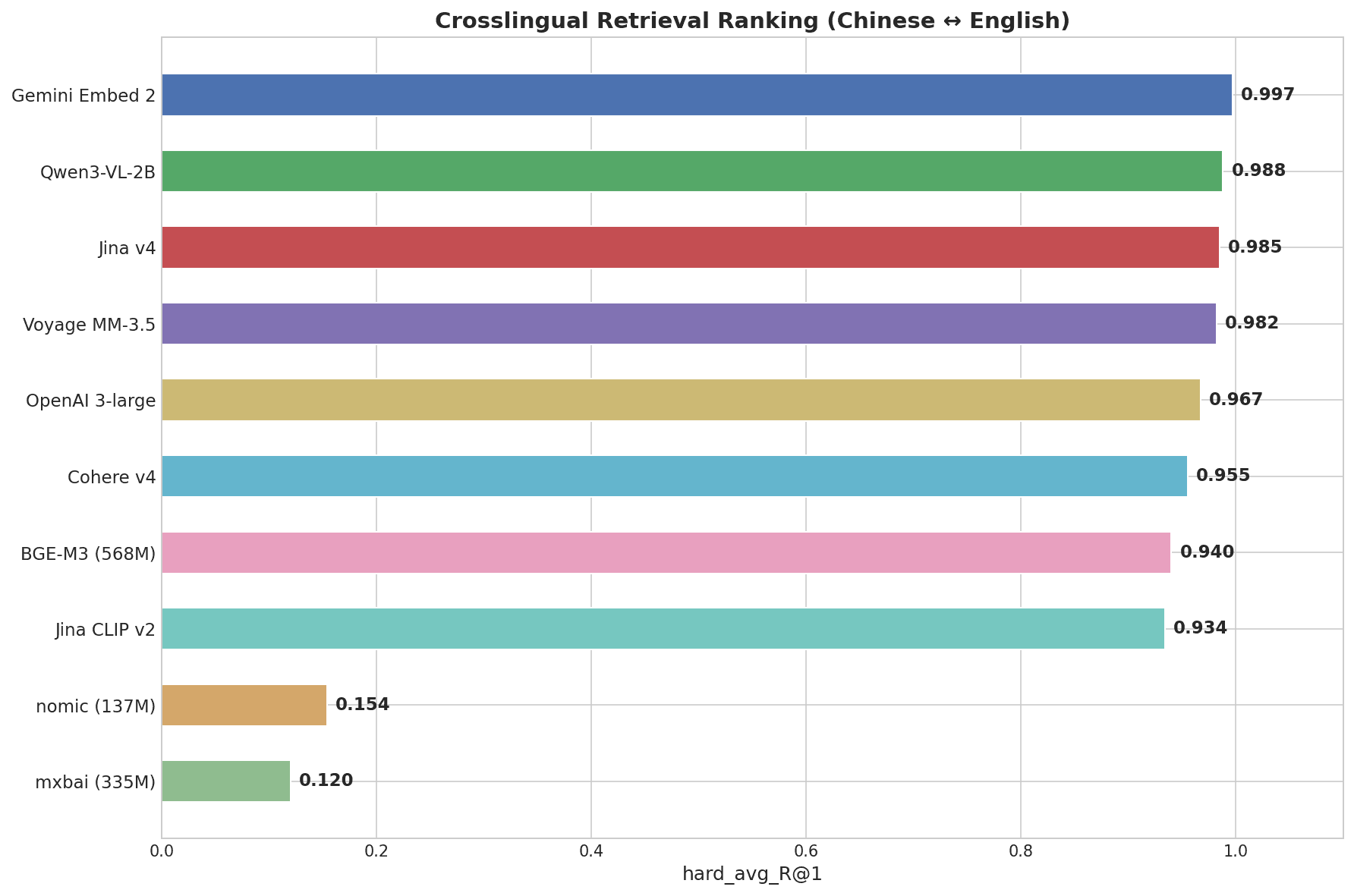 Horizontal bar chart showing Cross-Lingual Retrieval Ranking: Gemini Embed 2 leads at 0.997, followed by Qwen3-VL-2B at 0.988, Jina v4 at 0.985, Voyage MM-3.5 at 0.982, down to mxbai at 0.120
Horizontal bar chart showing Cross-Lingual Retrieval Ranking: Gemini Embed 2 leads at 0.997, followed by Qwen3-VL-2B at 0.988, Jina v4 at 0.985, Voyage MM-3.5 at 0.982, down to mxbai at 0.120
Gemini Embedding 2 scored 0.997 — the highest of any model tested. It was the only model to score a perfect 1.000 on the Hard tier, where pairs like “画蛇添足” → “gilding the lily” require genuine semantic understanding across languages, not pattern matching.
| Model | Score (R@1) | Easy | Medium | Hard (idioms) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
The top 7 models all clear 0.93 on the overall score — the real differentiation happens on the Hard tier (Chinese idioms). nomic-embed-text and mxbai-embed-large, both English-focused lightweight models, score near zero on cross-lingual tasks.
Key Information Retrieval: Can Models Find a Needle in a 32K-Token Document?
RAG systems often process lengthy documents — legal contracts, research papers, internal reports containing unstructured data. The question is whether an embedding model can still find one specific fact buried in thousands of characters of surrounding text.
Method
We took Wikipedia articles of varying lengths (4K to 32K characters) as the haystack and inserted a single fabricated fact — the needle — at different positions: start, 25%, 50%, 75%, and end. The model has to determine, based on a query embedding, which version of the document contains the needle.
Example:
- Needle: “The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025.”
- Query: “What was Meridian Corporation’s quarterly revenue?”
- Haystack: A 32,000-character Wikipedia article about photosynthesis, with the needle hidden somewhere inside.
Scoring:
- Generate embeddings for the query, the document with the needle, and the document without.
- If the query is more similar to the document containing the needle, count it as a hit.
- Average accuracy across all document lengths and needle positions.
- Final metrics: overall_accuracy and degradation_rate (how much accuracy drops from shortest to longest document).
Results
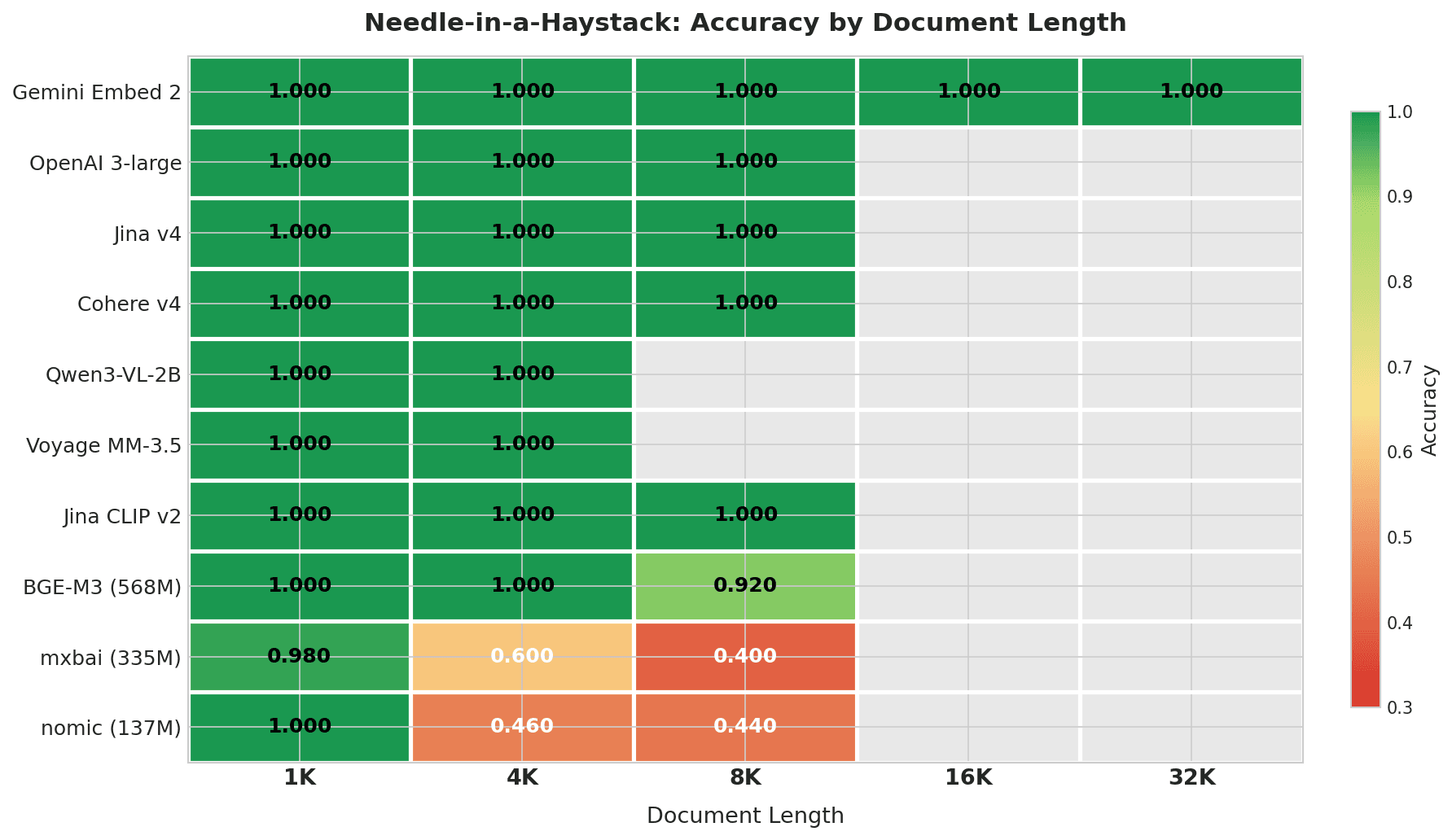 Heatmap showing Needle-in-a-Haystack accuracy by document length: Gemini Embed 2 scores 1.000 across all lengths up to 32K; top 7 models score perfectly within their context windows; mxbai and nomic degrade sharply at 4K+
Heatmap showing Needle-in-a-Haystack accuracy by document length: Gemini Embed 2 scores 1.000 across all lengths up to 32K; top 7 models score perfectly within their context windows; mxbai and nomic degrade sharply at 4K+
Gemini Embedding 2 is the only model tested across the full 4K–32K range, and it scored perfectly at every length. No other model in this test has a context window that reaches 32K.
| Model | 1K | 4K | 8K | 16K | 32K | Overall | Degradation |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
“—” means the document length exceeds the model’s context window.
The top 7 models score perfectly within their context windows. BGE-M3 starts to slip at 8K (0.920). The lightweight models (mxbai and nomic) drop to 0.4–0.6 at just 4K characters — roughly 1,000 tokens. For mxbai, this drop partly reflects its 512-token context window truncating most of the document.
MRL Dimension Compression: How Much Quality Do You Lose at 256 Dimensions?
Matryoshka Representation Learning (MRL) is a training technique that makes the first N dimensions of a vector meaningful on their own. Take a 3072-dimension vector, truncate it to 256, and it still holds most of its semantic quality. Fewer dimensions mean lower storage and memory costs in your vector database — going from 3072 to 256 dimensions is a 12x storage reduction.
 Illustration showing MRL dimension truncation: 3072 dimensions at full quality, 1024 at 95%, 512 at 90%, 256 at 85% — with 12x storage savings at 256 dimensions
Illustration showing MRL dimension truncation: 3072 dimensions at full quality, 1024 at 95%, 512 at 90%, 256 at 85% — with 12x storage savings at 256 dimensions
Method
We used 150 sentence pairs from the STS-B benchmark, each with a human-annotated similarity score (0–5). For each model, we generated embeddings at full dimensions, then truncated to 1024, 512, and 256.
 STS-B data examples showing sentence pairs with human similarity scores: A girl is styling her hair vs A girl is brushing her hair scores 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach scores 3.6
STS-B data examples showing sentence pairs with human similarity scores: A girl is styling her hair vs A girl is brushing her hair scores 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach scores 3.6
Scoring:
- At each dimension level, compute the cosine similarity between each sentence pair’s embeddings.
- Compare the model’s similarity ranking to the human ranking using Spearman’s ρ (rank correlation).
What is Spearman’s ρ? It measures how well two rankings agree. If humans rank pair A as most similar, B second, C least — and the model’s cosine similarities produce the same order A > B > C — then ρ approaches 1.0. A ρ of 1.0 means perfect agreement. A ρ of 0 means no correlation.
Final metrics: spearman_rho (higher is better) and min_viable_dim (the smallest dimension where quality stays within 5% of full-dimension performance).
Results
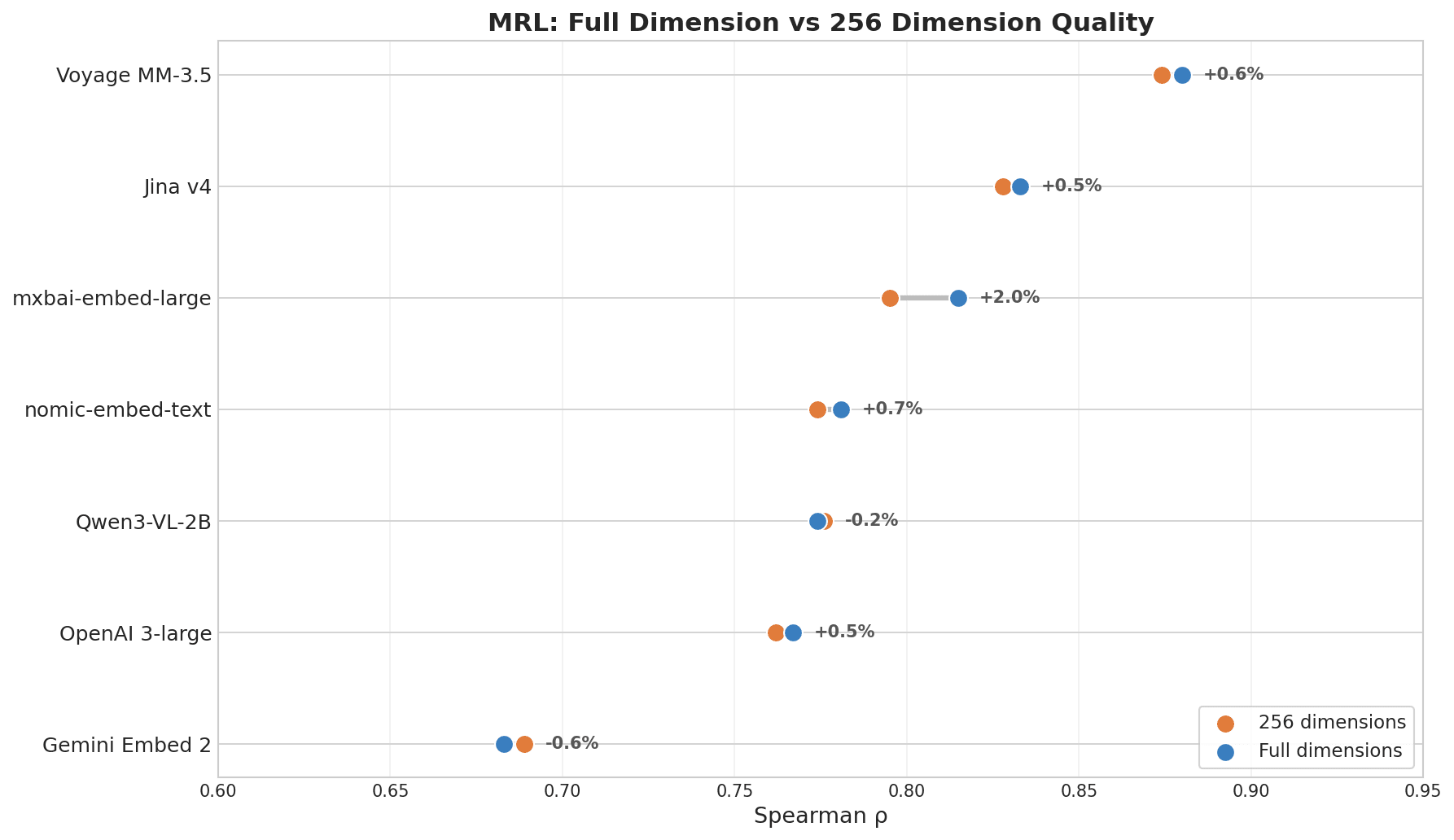 Dot plot showing MRL Full Dimension vs 256 Dimension Quality: Voyage MM-3.5 leads with +0.6% change, Jina v4 +0.5%, while Gemini Embed 2 shows -0.6% at the bottom
Dot plot showing MRL Full Dimension vs 256 Dimension Quality: Voyage MM-3.5 leads with +0.6% change, Jina v4 +0.5%, while Gemini Embed 2 shows -0.6% at the bottom
If you’re planning to reduce storage costs in Milvus or another vector database by truncating dimensions, this result matters.
| Model | ρ (full dim) | ρ (256 dim) | Decay |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage and Jina v4 lead because both were explicitly trained with MRL as an objective. Dimension compression has little to do with model size — whether the model was trained for it is what matters.
A note on Gemini’s score: the MRL ranking reflects how well a model preserves quality after truncation, not how good its full-dimension retrieval is. Gemini’s full-dimension retrieval is strong — the cross-lingual and key information results already proved that. It just wasn’t optimized for shrinking. If you don’t need dimension compression, this metric doesn’t apply to you.
Which Embedding Model Should You Use?
No single model wins everything. Here’s the full scorecard:
| Model | Params | Cross-Modal | Cross-Lingual | Key Info | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Undisclosed | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Undisclosed | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Undisclosed | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Undisclosed | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
“—” means the model doesn’t support that modality or capability. CLIP is a 2021 baseline for reference.
Here’s what stands out:
- Cross-modal: Qwen3-VL-2B (0.945) first, Gemini (0.928) second, Voyage (0.900) third. An open-source 2B model beat every closed-source API. The deciding factor was modality gap, not parameter count.
- Cross-lingual: Gemini (0.997) leads — the only model to score perfectly on idiom-level alignment. The top 8 models all clear 0.93. English-only lightweight models score near zero.
- Key information: API and large open-source models score perfectly up to 8K. Models below 335M start degrading at 4K. Gemini is the only model that handles 32K with a perfect score.
- MRL dimension compression: Voyage (0.880) and Jina v4 (0.833) lead, losing less than 1% at 256 dimensions. Gemini (0.668) comes last — strong at full dimension, not optimized for truncation.
How to Pick: A Decision Flowchart
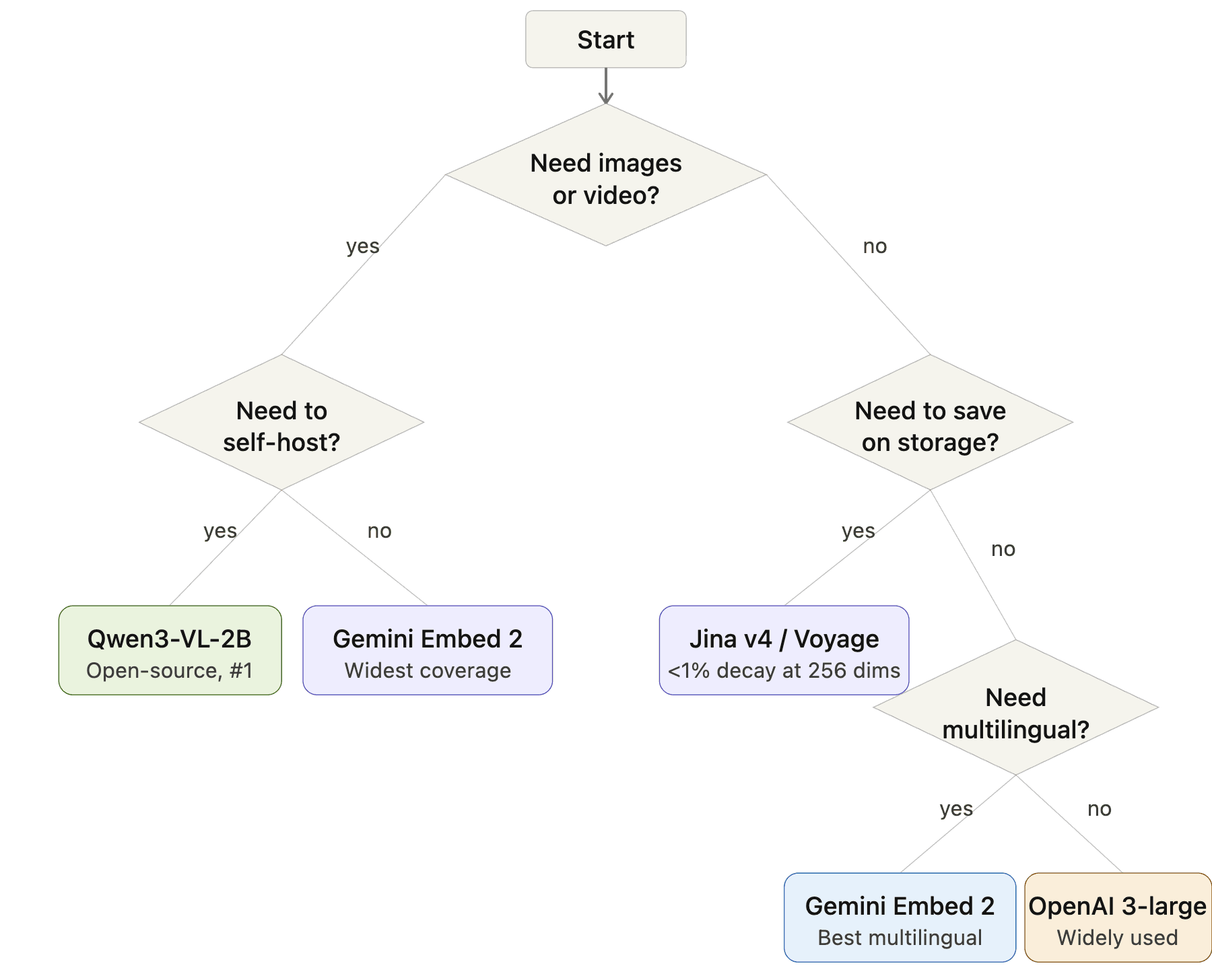 Embedding model selection flowchart: Start → Need images or video? → Yes: Need to self-host? → Yes: Qwen3-VL-2B, No: Gemini Embedding 2. No images → Need to save storage? → Yes: Jina v4 or Voyage, No: Need multilingual? → Yes: Gemini Embedding 2, No: OpenAI 3-large
Embedding model selection flowchart: Start → Need images or video? → Yes: Need to self-host? → Yes: Qwen3-VL-2B, No: Gemini Embedding 2. No images → Need to save storage? → Yes: Jina v4 or Voyage, No: Need multilingual? → Yes: Gemini Embedding 2, No: OpenAI 3-large
The Best All-Rounder: Gemini Embedding 2
On balance, Gemini Embedding 2 is the strongest overall model in this benchmark.
Strengths: First in cross-lingual (0.997) and key information retrieval (1.000 across all lengths up to 32K). Second in cross-modal (0.928). Widest modality coverage — five modalities (text, image, video, audio, PDF) where most models top out at three.
Weaknesses: Last in MRL compression (ρ = 0.668). Beaten on cross-modal by the open-source Qwen3-VL-2B.
If you don’t need dimension compression, Gemini has no real competitor on the combination of cross-lingual + long-document retrieval. But for cross-modal precision or storage optimization, specialized models do better.
Limitations
- We didn’t include every model worth considering — NVIDIA’s NV-Embed-v2 and Jina’s v5-text were on the list but didn’t make this round.
- We focused on text and image modalities; video, audio, and PDF embedding (despite some models claiming support) weren’t covered.
- Code retrieval and other domain-specific scenarios were out of scope.
- Sample sizes were relatively small, so tight ranking differences between models may fall within statistical noise.
This article’s results will be outdated within a year. New models ship constantly, and the leaderboard reshuffles with every release. The more durable investment is building your own evaluation pipeline — define your data types, your query patterns, your document lengths, and run new models through your own tests when they drop. Public benchmarks like MTEB, MMTEB, and MMEB are worth monitoring, but the final call should always come from your own data.
Our benchmark code is open-source on GitHub — fork it and adapt it to your use case.
Once you’ve picked your embedding model, you need somewhere to store and search those vectors at scale. Milvus is the world’s most widely adopted open-source vector database with 43K+ GitHub stars built for exactly this — it supports MRL-truncated dimensions, mixed multimodal collections, hybrid search combining dense and sparse vectors, and scales from a laptop to billions of vectors.
- Get started with the Milvus Quickstart guide, or install with
pip install pymilvus. - Join the Milvus Slack or Milvus Discord to ask questions about embedding model integration, vector indexing strategies, or production scaling.
- Book a free Milvus Office Hours session to walk through your RAG architecture — we can help with model selection, collection schema design, and performance tuning.
- If you’d rather skip the infrastructure work, Zilliz Cloud (managed Milvus) offers a free tier to get started.
A few questions that come up when engineers are choosing an embedding model for production RAG:
Q: Should I use a multimodal embedding model even if I only have text data right now?
It depends on your roadmap. If your pipeline will likely add images, PDFs, or other modalities within the next 6–12 months, starting with a multimodal model like Gemini Embedding 2 or Voyage Multimodal 3.5 avoids a painful migration later — you won’t need to re-embed your entire dataset. If you’re confident it’s text-only for the foreseeable future, a text-focused model like OpenAI 3-large or Cohere Embed v4 will give you better price/performance.
Q: How much storage does MRL dimension compression actually save in a vector database?
Going from 3072 dimensions to 256 dimensions is a 12x reduction in storage per vector. For a Milvus collection with 100 million vectors at float32, that’s roughly 1.14 TB → 95 GB. The key is that not all models handle truncation well — Voyage Multimodal 3.5 and Jina Embeddings v4 lose less than 1% quality at 256 dimensions, while others degrade significantly.
Q: Is Qwen3-VL-2B really better than Gemini Embedding 2 for cross-modal search?
On our benchmark, yes — Qwen3-VL-2B scored 0.945 versus Gemini’s 0.928 on hard cross-modal retrieval with near-identical distractors. The main reason is Qwen’s much smaller modality gap (0.25 vs 0.73), which means text and image embeddings cluster closer together in vector space. That said, Gemini covers five modalities while Qwen covers three, so if you need audio or PDF embedding, Gemini is the only option.
Q: Can I use these embedding models with Milvus directly?
Yes. All of these models output standard float vectors, which you can insert into Milvus and search with cosine similarity, L2 distance, or inner product. PyMilvus works with any embedding model — generate your vectors with the model’s SDK, then store and search them in Milvus. For MRL-truncated vectors, just set the collection’s dimension to your target (e.g., 256) when creating the collection.
- Why MTEB Isn't Enough for Choosing an Embedding Model
- What Is the CCKM Benchmark?
- Which Embedding Models Did We Test? Gemini Embedding 2, Jina Embeddings v4, and More
- Cross-Modal Retrieval: Which Models Handle Text-to-Image Search?
- Method
- Results
- Cross-Lingual Retrieval: Which Models Align Meaning Across Languages?
- Method
- Results
- Key Information Retrieval: Can Models Find a Needle in a 32K-Token Document?
- Method
- Results
- MRL Dimension Compression: How Much Quality Do You Lose at 256 Dimensions?
- Method
- Results
- Which Embedding Model Should You Use?
- How to Pick: A Decision Flowchart
- The Best All-Rounder: Gemini Embedding 2
- Limitations
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



