We Trained and Open-Sourced a Bilingual Semantic Highlighting Model for Production RAG and AI Search
Whether you’re building a product search, a RAG pipeline, or an AI agent, users ultimately need the same thing: a fast way to see why a result is relevant. Highlighting helps by marking the exact text that supports the match, so users don’t have to scan the entire document.
Most systems still rely on keyword-based highlighting. If a user searches for “iPhone performance,” the system highlights the exact tokens “iPhone” and “performance.” But this breaks down as soon as the text expresses the same idea using different wording. A description like “A15 Bionic chip, over one million in benchmarks, smooth with no lag” clearly addresses performance, yet nothing is highlighted because the keywords never appear.
Semantic highlighting solves this problem. Instead of matching exact strings, it identifies text spans that are semantically aligned with the query. For RAG systems, AI search, and agents—where relevance depends on meaning rather than surface form—this yields more precise, more reliable explanations of why a document was retrieved.
However, existing semantic highlighting methods aren’t designed for production AI workloads. After evaluating all available solutions, we found that none delivered the precision, latency, multilingual coverage, or robustness required for RAG pipelines, agent systems, or large-scale web search. So we trained our own bilingual semantic highlighting model—and open-sourced it.
Our semantic highlighting model: zilliz/semantic-highlight-bilingual-v1
Tell us what you think—join our Discord, follow us on LinkedIn, or book a 20-minute Milvus Office Hours session with us.
How Keyword-Based Highlighting Works — and Why It Fails in Modern AI Systems
Traditional search systems implement highlighting through simple keyword matching. When results are returned, the engine locates the exact token positions that match the query and wraps them in markup (usually <em> tags), leaving the frontend to render the highlight. This works fine when the query terms appear verbatim in the text.
The problem is that this model assumes relevance is tied to exact keyword overlap. Once that assumption breaks, reliability drops fast. Any result that expresses the right idea with different wording ends up with no highlight at all, even if the retrieval step was correct.
This weakness becomes obvious in modern AI applications. In RAG pipelines and AI agent workflows, queries are more abstract, documents are longer, and relevant information may not reuse the same words. Keyword-based highlighting can no longer show developers—or end users—where the answer actually is, which makes the overall system feel less accurate even when retrieval is working as intended.
Suppose a user asks: “How can I improve the execution efficiency of Python code?” The system retrieves a technical document from a vector database. Traditional highlighting can only mark literal matches such as “Python”, “code”, “execution”, and “efficiency”.
However, the most useful parts of the document might be:
Use NumPy vectorized operations instead of explicit loops
Avoid repeatedly creating objects inside loops
These sentences directly answer the question, but they contain none of the query terms. As a result, traditional highlighting fails completely. The document may be relevant, but the user still has to scan it line by line to locate the actual answer.
The problem becomes even more pronounced with AI agents. An agent’s search query is often not the user’s original question, but a derived instruction produced through reasoning and task decomposition. For example, if a user asks, “Can you analyze recent market trends?”, the agent might generate a query like “Retrieve Q4 2024 consumer electronics sales data, year-over-year growth rates, changes in major competitors’ market share, and supply chain cost fluctuations”.
This query spans multiple dimensions and encodes complex intent. Traditional keyword-based highlighting, however, can only mechanically mark literal matches such as “2024”, “sales data”, or “growth rate”.
Meanwhile, the most valuable insights may look like:
The iPhone 15 series drove a broader market recovery
Chip supply constraints pushed costs up by 15%
These conclusions may not share a single keyword with the query, even though they are exactly what the agent is trying to extract. Agents need to quickly identify truly useful information from large volumes of retrieved content—and keyword-based highlighting offers no real help.
What Is Semantic Highlighting, and Pain Points in Today’s Solutions
Semantic highlighting builds on the same idea behind semantic search: matching based on meaning rather than exact words. In semantic search, embedding models map text into vectors so a search system—typically backed by a vector database like Milvus—can retrieve passages that convey the same idea as the query, even if the wording is different. Semantic highlighting applies this principle at a finer granularity. Instead of marking literal keyword hits, it highlights the specific spans inside a document that are semantically relevant to the user’s intent.
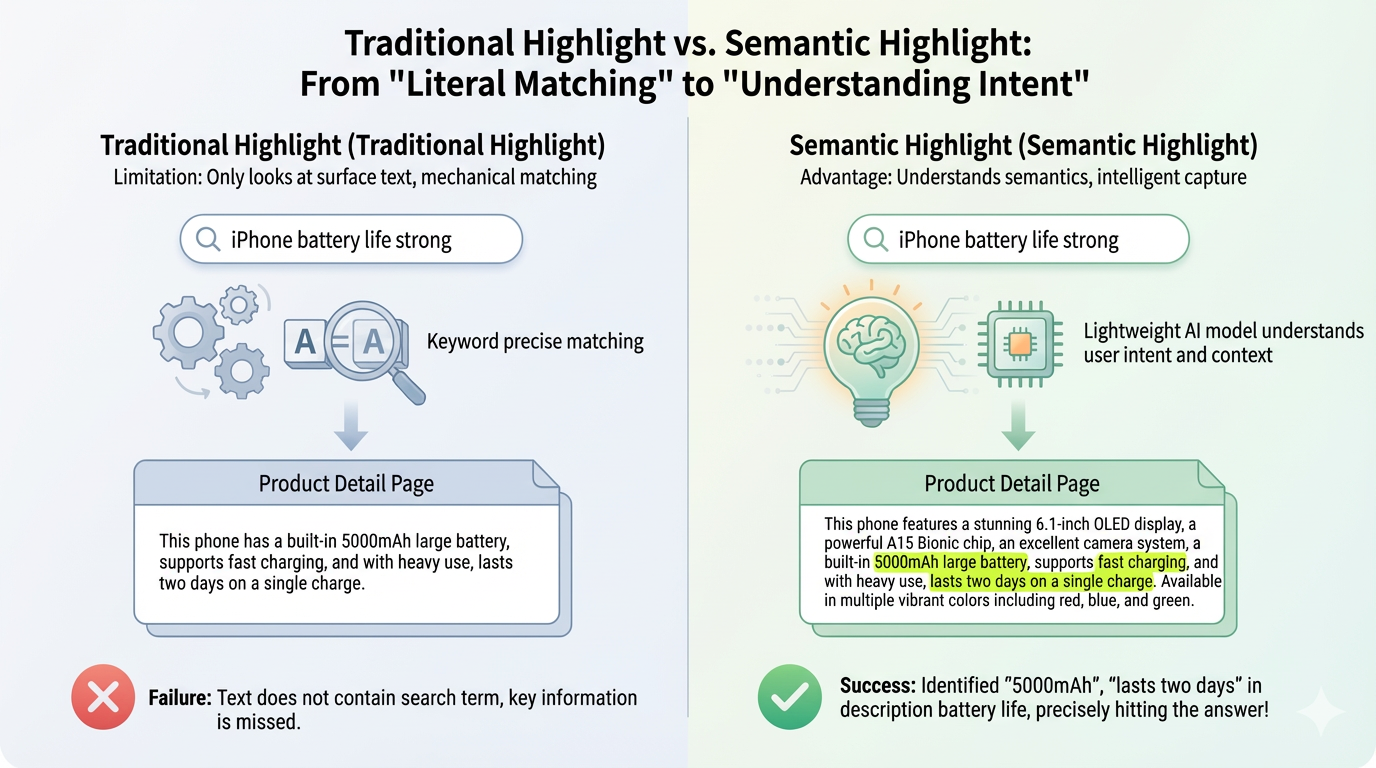
This approach solves a core problem with traditional highlighting, which only works when the query terms appear verbatim. If a user searches for “iPhone performance,” keyword-based highlighting ignores phrases like “A15 Bionic chip,” “over one million in benchmarks,” or “smooth with no lag,” even though these lines clearly answer the question. Semantic highlighting captures these meaning-driven connections and surfaces the parts of the text users actually care about.
In theory, this is a straightforward semantic matching problem. Modern embedding models already encode similarity well, so the conceptual pieces are already in place. The challenge comes from real-world constraints: highlighting occurs on every query, often across many retrieved documents, making latency, throughput, and cross-domain robustness non-negotiable requirements. Large language models are simply too slow and too expensive to run in this high-frequency path.
That is why practical semantic highlighting requires a lightweight, specialized model—small enough to sit alongside search infrastructure and fast enough to return results in a few milliseconds. This is where most existing solutions break down. Heavy models deliver accuracy but cannot run at scale; lighter models are fast but lose precision or fail on multilingual or domain-specific data.
opensearch-semantic-highlighter

Last year, OpenSearch released a dedicated model for semantic highlighting: opensearch-semantic-highlighter-v1. While it is a meaningful attempt at the problem, it has two critical limitations.
Small context window: The model is based on a BERT architecture and supports a maximum of 512 tokens—roughly 300–400 Chinese characters or 400–500 English words. In real-world scenarios, product descriptions and technical documents often span thousands of words. Content beyond the first window is simply truncated, forcing the model to identify highlights based on only a small fraction of the document.
Poor out-of-domain generalization: The model performs well only on data distributions similar to its training set. When applied to out-of-domain data—such as using a model trained on news articles to highlight e-commerce content or technical documentation—performance degrades sharply. In our experiments, the model achieves an F1 score of around 0.72 on in-domain data, but drops to approximately 0.46 on out-of-domain datasets. This level of instability is problematic in production. In addition, the model does not support Chinese.
Provence / XProvence
Provence is a model developed by Naver and was initially trained for context pruning—a task that is closely related to semantic highlighting.
Both tasks are built on the same underlying idea: using semantic matching to identify relevant content and filter out irrelevant parts. For this reason, Provence can be repurposed for semantic highlighting with relatively little adaptation.

Provence is an English-only model and performs reasonably well in that setting. XProvence is its multilingual variant, supporting more than a dozen languages, including Chinese, Japanese, and Korean. At first glance, this makes XProvence appear to be a good candidate for bilingual or multilingual semantic highlighting scenarios.
In practice, however, both Provence and XProvence have several notable limitations:
Weaker English performance in the multilingual model: XProvence does not match Provence’s performance on English benchmarks. This is a common trade-off in multilingual models: capacity is shared across languages, often leading to weaker performance in high-resource languages such as English. This limitation matters in real-world systems where English remains a primary or dominant workload.
Limited Chinese performance: XProvence supports many languages. During multilingual training, data and model capacity are spread across languages, which limits how well the model can specialize in any single one. As a result, its Chinese performance is only marginally acceptable and often insufficient for high-precision highlighting use cases.
Mismatch between pruning and highlighting objectives: Provence is optimized for context pruning, where the priority is recall—keeping as much potentially useful content as possible to avoid losing critical information. Semantic highlighting, by contrast, emphasizes precision: highlighting only the most relevant sentences, not large portions of the document. When Provence-style models are applied to highlighting, this mismatch often leads to overly broad or noisy highlights.
Restrictive licensing: Both Provence and XProvence are released under the CC BY-NC 4.0 license, which does not permit commercial use. This restriction alone makes them unsuitable for many production deployments.
Open Provence

Open Provence is a community-driven project that reimplements the Provence training pipeline in an open and transparent way. It provides not only training scripts, but also data processing workflows, evaluation tools, and pretrained models at multiple scales.
A key advantage of Open Provence is its permissive MIT license. Unlike Provence and XProvence, it can be safely used in commercial environments without legal restrictions, which makes it attractive for production-oriented teams.
That said, Open Provence currently supports only English and Japanese, which makes it unsuitable for our bilingual use cases.
We Trained and Open-Sourced a Bilingual Semantic Highlighting Model
A semantic highlighting model designed for real-world workloads must deliver a few essential capabilities:
Strong multilingual performance
A context window large enough to support long documents
Robust out-of-domain generalization
High precision in semantic highlighting tasks
A permissive, production-friendly license (MIT or Apache 2.0)
After evaluating existing solutions, we found that none of the available models met the requirements needed for production use. So we decided to train our own semantic highlight model: zilliz/semantic-highlight-bilingual-v1.
To achieve all of these, we adopted a straightforward approach: use large language models to generate high-quality labeled data, then train a lightweight semantic highlighting model on top of it using open-source tooling. This lets us combine the reasoning strength of LLMs with the efficiency and low latency required in production systems.
The most challenging part of this process is data construction. During annotation, we prompt an LLM (Qwen3 8B) to output not only the highlight spans but also the whole reasoning behind them. This additional reasoning signal produces more accurate, consistent supervision and significantly improves the quality of the resulting model.
At a high level, the annotation pipeline works as follows: LLM reasoning → highlight labels → filtering → final training sample.
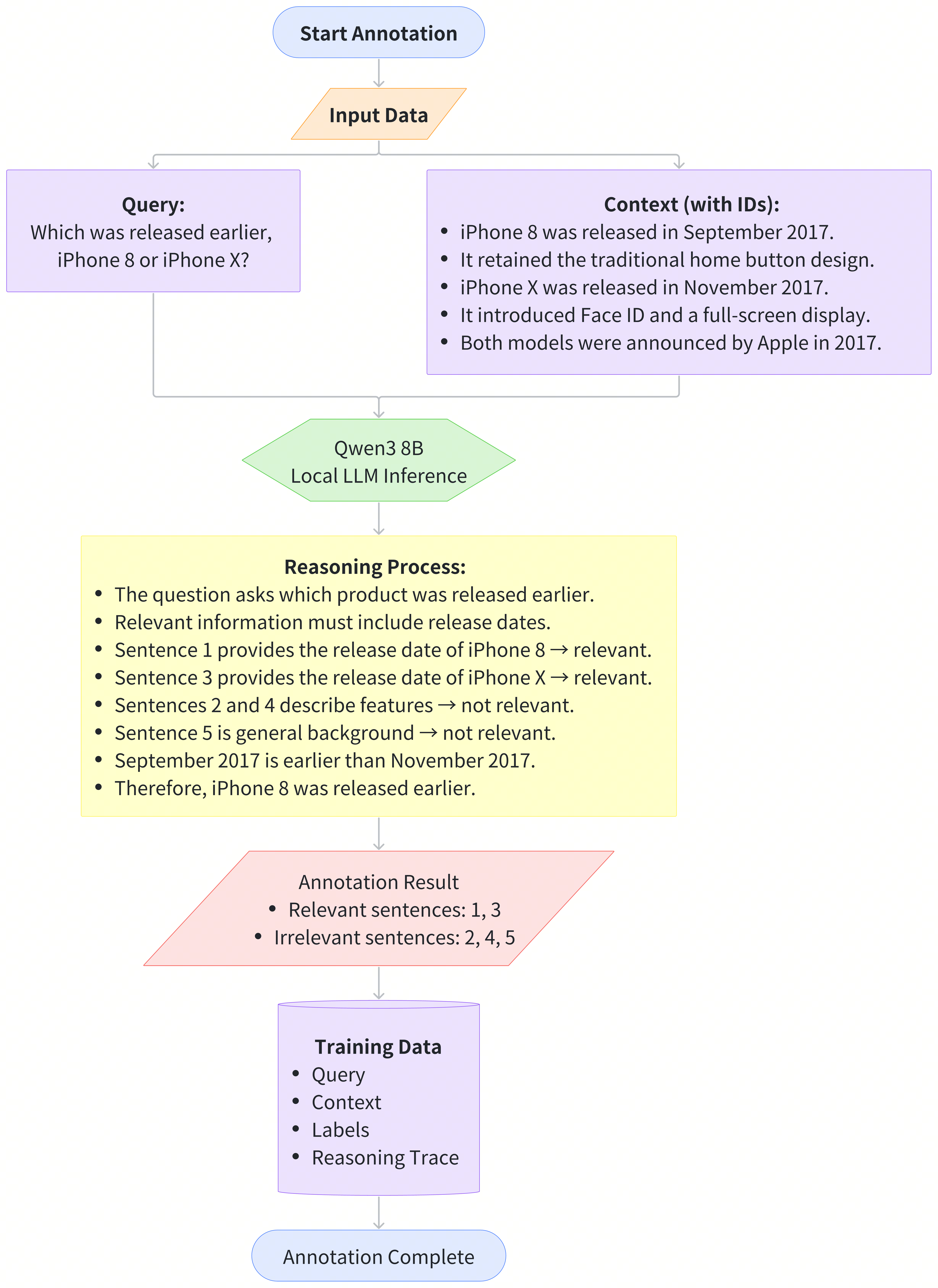
This design delivers three concrete benefits in practice:
Higher labeling quality: The model is prompted to think first, then answer. This intermediate reasoning step serves as a built-in self-check, reducing the likelihood of shallow or inconsistent labels.
Improved observability and debuggability: Because each label is accompanied by a reasoning trace, errors become visible. This makes it easier to diagnose failure cases and quickly adjust prompts, rules, or data filters in the pipeline.
Reusable data: Reasoning traces provide valuable context for future re-labeling. As requirements change, the same data can be revisited and refined without starting from scratch.
Using this pipeline, we generated more than one million bilingual training samples, split roughly evenly between English and Chinese.
For model training, we started from BGE-M3 Reranker v2 (0.6B parameters, 8,192-token context window), adopted the Open Provence training framework, and trained for three epochs on 8× A100 GPUs, completing training in approximately five hours.
We will dive deeper into these technical choices—including why we rely on reasoning traces, how we selected the base model, and how the dataset was constructed—in a follow-up post.
Benchmarking Zilliz’s Bilingual Semantic Highlighting Model
To assess real-world performance, we evaluated multiple semantic highlighting models across a diverse set of datasets. The benchmarks cover both in-domain and out-of-domain scenarios, in English and Chinese, to reflect the variety of content encountered in production systems.
Datasets
We used the following datasets in our evaluation:
MultiSpanQA (English) – an in-domain multi-span question answering dataset
WikiText-2 (English) – an out-of-domain Wikipedia corpus
MultiSpanQA-ZH (Chinese) – a Chinese multi-span question answering dataset
WikiText-2-ZH (Chinese) – an out-of-domain Chinese Wikipedia corpus
Models Compared
The models included in the comparison are:
Open Provence models
Provence / XProvence (released by Naver)
OpenSearch Semantic Highlighter
Zilliz’s bilingual semantic highlighting model
Results and Analysis
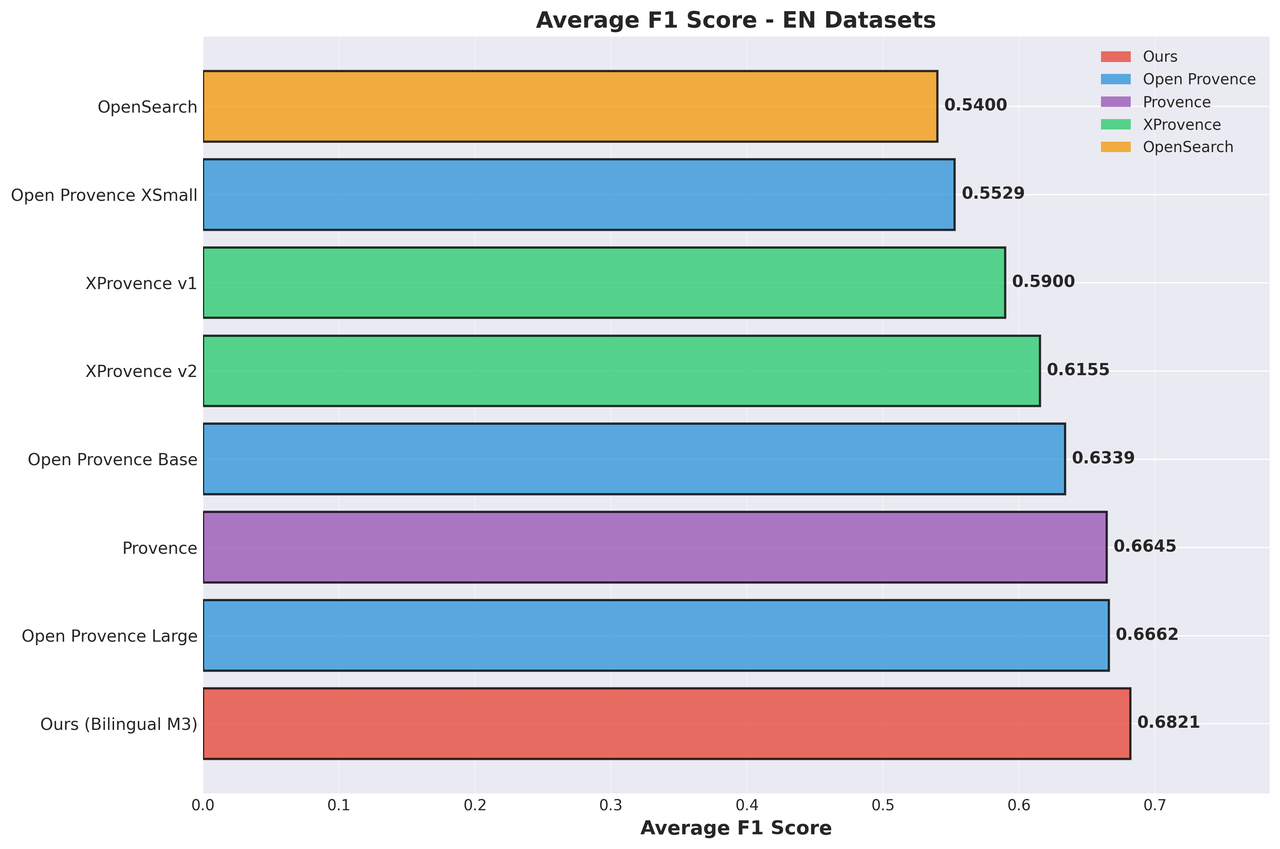
English Datasets:
Chinese Datasets:
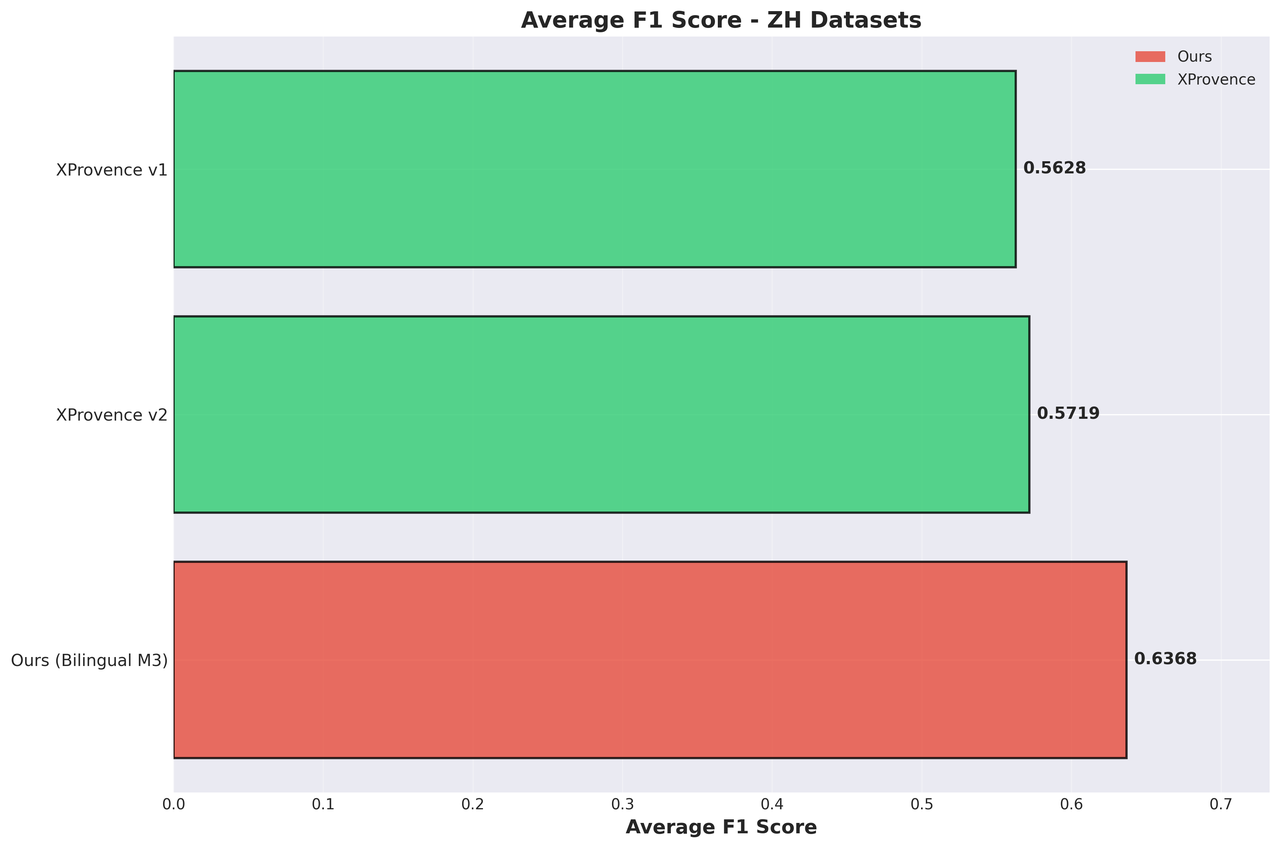
Across the bilingual benchmarks, our model achieves state-of-the-art average F1 scores, outperforming all previously evaluated models and approaches. The gains are especially pronounced on the Chinese datasets, where our model significantly outperforms XProvence—the only other evaluated model with Chinese support.
More importantly, our model delivers balanced performance across both English and Chinese, a property that existing solutions struggle to achieve:
Open Provence supports English only
XProvence sacrifices English performance compared to Provence
OpenSearch Semantic Highlighter lacks Chinese support and shows weak generalization
As a result, our model avoids the common trade-offs between language coverage and performance, making it better suited for real-world bilingual deployments.
A Concrete Example in Practice
Beyond benchmark scores, it is often more revealing to examine a concrete example. The following case shows how our model behaves in a real semantic highlighting scenario and why precision matters.
Query: Who wrote the film The Killing of a Sacred Deer?
Context (5 sentences):
The Killing of a Sacred Deer is a 2017 psychological thriller film directed by Yorgos Lanthimos, with the screenplay written by Lanthimos and Efthymis Filippou.
The film stars Colin Farrell, Nicole Kidman, Barry Keoghan, Raffey Cassidy, Sunny Suljic, Alicia Silverstone, and Bill Camp.
The story is based on the ancient Greek play Iphigenia in Aulis by Euripides.
The film follows a cardiac surgeon who forms a secret friendship with a teenage boy connected to his past.
He introduces the boy to his family, after which mysterious illnesses begin to occur.
Correct highlight: Sentence 1 is the correct answer, as it explicitly states that the screenplay was written by Yorgos Lanthimos and Efthymis Filippou.
This example contains a subtle trap. Sentence 3 mentions Euripides, the author of the original Greek play on which the story is loosely based. However, the question asks who wrote the film, not the ancient source material. The correct answer is therefore the screenwriters of the movie, not the playwright from thousands of years ago.
Results:
The table below summarizes how different models performed on this example.
| Model | Correct Answer Identified | Outcome |
|---|---|---|
| Ours (Bilingual M3) | ✓ | Selected sentence 1 (correct) and sentence 3 |
| XProvence v1 | ✗ | Selected sentence 3 only, missed the correct answer |
| XProvence v2 | ✗ | Selected sentence 3 only, missed the correct answer |
Sentence-Level Score Comparison
| Sentence | Ours (Bilingual M3) | XProvence v1 | XProvence v2 |
|---|---|---|---|
| Sentence 1 (film screenplay, correct) | 0.915 | 0.133 | 0.081 |
| Sentence 3 (original play, distractor) | 0.719 | 0.947 | 0.802 |
Where XProvence falls short
XProvence is strongly attracted to the keywords “Euripides” and “wrote”, assigning sentence 3 an almost perfect score (0.947 and 0.802).
At the same time, it largely ignores the correct answer in sentence 1, assigning extremely low scores (0.133 and 0.081).
Even after lowering the decision threshold from 0.5 to 0.2, the model still fails to surface the correct answer.
In other words, the model is primarily driven by surface-level keyword associations rather than the question’s actual intent.
How our model behaves differently
Our model assigns a high score (0.915) to the correct answer in sentence 1, correctly identifying the film’s screenwriters.
It also assigns a moderate score (0.719) to sentence 3, since that sentence does mention a screenplay-related concept.
Crucially, the separation is clear and meaningful: 0.915 vs. 0.719, a gap of nearly 0.2.
This example highlights the core strength of our approach: moving beyond keyword-driven associations to correctly interpret user intent. Even when multiple “author” concepts appear, the model consistently highlights the one the question actually refers to.
We will share a more detailed evaluation report and additional case studies in a follow-up post.
Try It Out and Tell Us What You Think
We’ve open-sourced our bilingual semantic highlighting model on Hugging Face, with all model weights publicly available so you can start experimenting right away. We’d love to hear how it works for you—please share any feedback, issues, or improvement ideas as you try it out.
In parallel, we’re working on a production-ready inference service and integrating the model directly into Milvus as a native Semantic Highlighting API. This integration is already underway and will be available soon.
Semantic highlighting opens the door to a more intuitive RAG and agentic AI experience. When Milvus retrieves several long documents, the system can immediately surface the most relevant sentences, making it clear where the answer is. This doesn’t just improve the end-user experience—it also helps developers debug retrieval pipelines by showing exactly which parts of the context the system relies on.
We believe semantic highlighting will become a standard capability in next-generation search and RAG systems. If you have ideas, suggestions, or use cases for bilingual semantic highlighting, join our Discord channel and share your thoughts. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
- How Keyword-Based Highlighting Works — and Why It Fails in Modern AI Systems
- What Is Semantic Highlighting, and Pain Points in Today’s Solutions
- opensearch-semantic-highlighter
- Provence / XProvence
- Open Provence
- We Trained and Open-Sourced a Bilingual Semantic Highlighting Model
- Benchmarking Zilliz’s Bilingual Semantic Highlighting Model
- Datasets
- Models Compared
- Results and Analysis
- A Concrete Example in Practice
- Try It Out and Tell Us What You Think
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



