How Milvus Implements Dynamic Data Update And Query
In this article, we will mainly describe how vector data are recorded in the memory of Milvus, and how these records are maintained.
Below are our main design goals:
- Efficiency of data import should be high.
- Data can be seen as soon as possible after data import.
- Avoid fragmentation of data files.
Therefore, we have established a memory buffer (insert buffer) to insert data to reduce the number of context switches of random IO on the disk and operating system to improve the performance of data insertion. The memory storage architecture based on MemTable and MemTableFile enables us to manage and serialize data more conveniently. The state of the buffer is divided into Mutable and Immutable, which allows the data to be persisted to disk while keeping external services available.
Preparation
When the user is ready to insert a vector into Milvus, he first needs to create a Collection (* Milvus renames Table to Collection in 0.7.0 version). Collection is the most basic unit for recording and searching vectors in Milvus.
Each Collection has a unique name and some properties that can be set, and vectors are inserted or searched based on the Collection name. When creating a new Collection, Milvus will record the information of this Collection in the metadata.
Data Insertion
When the user sends a request to insert data, the data are serialized and deserialized to reach the Milvus server. Data are now written into memory. Memory writing is roughly divided into the following steps:
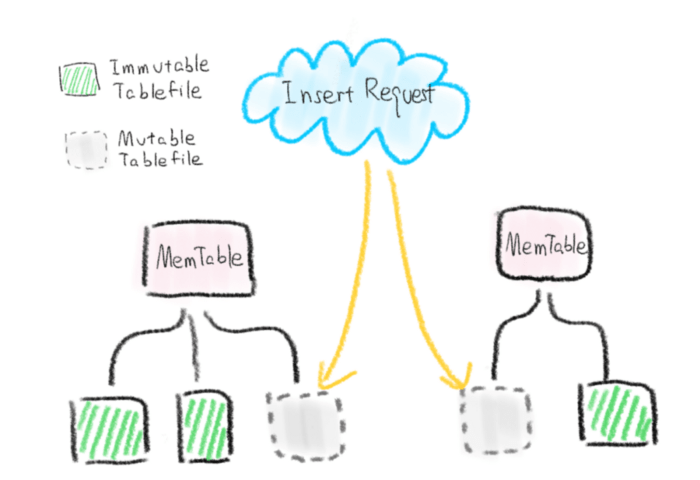 2-data-insertion-milvus.png
2-data-insertion-milvus.png
- In MemManager, find or create a new MemTable corresponding to the name of the Collection. Each MemTable corresponds to a Collection buffer in memory.
- A MemTable will contain one or more MemTableFile. Whenever we create a new MemTableFile, we will record this information in the Meta at the same time. We divide MemTableFile into two states: Mutable and Immutable. When the size of MemTableFile reaches the threshold, it will become Immutable. Each MemTable can only have one Mutable MemTableFile to be written at any time.
- The data of each MemTableFile will be finally recorded in the memory in the format of the set index type. MemTableFile is the most basic unit for managing data in memory.
- At any time, the memory usage of the inserted data will not exceed the preset value (insert_buffer_size). This is because every request to insert data comes in, MemManager can easily calculate the memory occupied by the MemTableFile contained in each MemTable, and then coordinate the insertion request according to the current memory.
Through MemManager, MemTable and MemTableFile multi-level architecture, data insertion can be better managed and maintained. Of course, they can do much more than that.
Near Real-time Query
In Milvus, you only need to wait for one second at the longest for the inserted data to move from memory to disk. This entire process can be roughly summarized by the following picture:
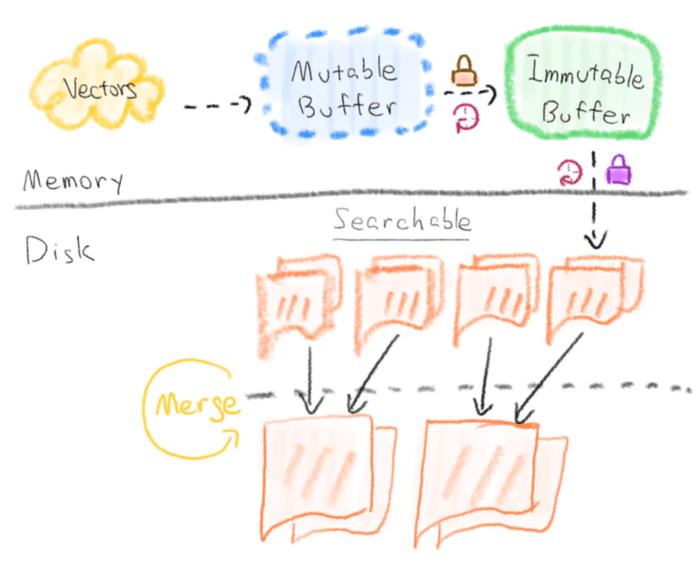 2-near-real-time-query-milvus.png
2-near-real-time-query-milvus.png
First, the inserted data will enter an insert buffer in memory. The buffer will periodically change from the initial Mutable state to the Immutable state in preparation for serialization. Then, these Immutable buffers will be serialized to disk periodically by the background serialization thread. After the data are placed, the order information will be recorded in the metadata. At this point, the data can be searched!
Now, we will describe the steps in the picture in detail.
We already know the process of inserting data into the mutable buffer. The next step is to switch from the mutable buffer to the immutable buffer:
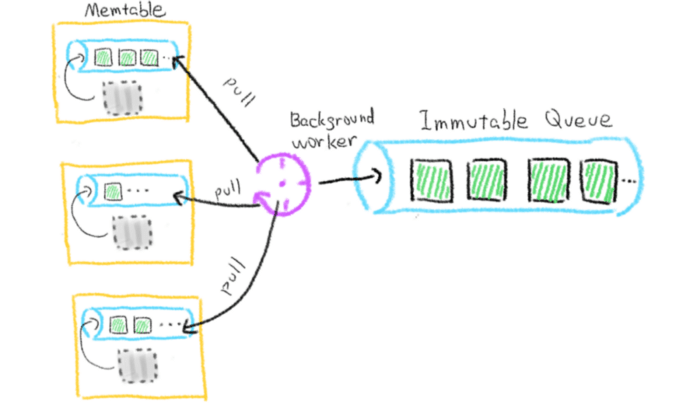 3-mutable-buffer-immutable-buffer-milvus.png
3-mutable-buffer-immutable-buffer-milvus.png
Immutable queue will provide the background serialization thread with the immutable state and the MemTableFile that is ready to be serialized. Each MemTable manages its own immutable queue, and when the size of the MemTable’s only mutable MemTableFile reaches the threshold, it will enter the immutable queue. A background thread responsible for ToImmutable will periodically pull all the MemTableFiles in the immutable queue managed by MemTable and send them to the total Immutable queue. It should be noted that the two operations of writing data into the memory and changing the data in the memory into a state that cannot be written cannot occur at the same time, and a common lock is required. However, the operation of ToImmutable is very simple and almost does not cause any delay, so the performance impact on inserted data is minimal.
The next step is to serialize the MemTableFile in the serialization queue to disk. This is mainly divided into three steps:
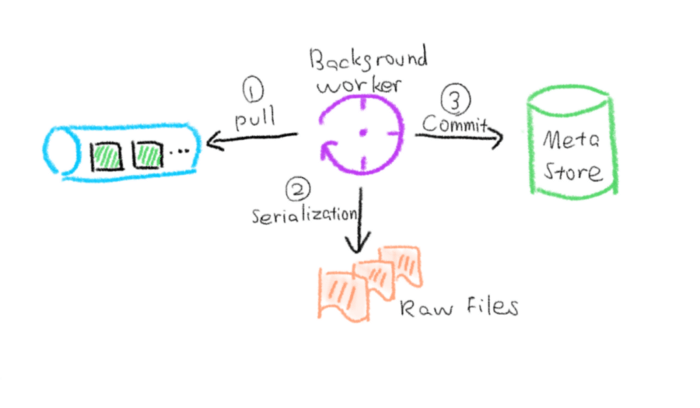 4-serialize-memtablefile-milvus.png
4-serialize-memtablefile-milvus.png
First, the background serialization thread will periodically pull MemTableFile from the immutable queue. Then, they are serialized into fixed-size raw files (Raw TableFiles). Finally, we will record this information in the metadata. When we conduct a vector search, we will query the corresponding TableFile in the metadata. From here, these data can be searched!
In addition, according to the set index_file_size, after the serialization thread completes a serialization cycle, it will merge some fixed-size TableFiles into a TableFile, and also record these information in the metadata. At this time, the TableFile can be indexed. Index building is also asynchronous. Another background thread responsible for index building will periodically read the TableFile in the ToIndex state of the metadata to perform the corresponding index building.
Vector search
In fact, you will find that with the help of TableFile and metadata, vector search becomes more intuitive and convenient. In general, we need to get the TableFiles corresponding to the queried Collection from the metadata, search in each TableFile, and finally merge. In this article, we do not delve into the specific implementation of search.
If you want to know more, welcome to read our source code, or read our other technical articles about Milvus!
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



