Background
n this article, we will discuss how Milvus schedules query tasks. We will also talk about problems, solutions, and future orientations for implementing Milvus scheduling.
Background
We know from Managing Data in Massive-Scale Vector Search Engine that vector similarity search is implemented by the distance between two vectors in high-dimensional space. The goal of vector search is to find K vectors that are closest to the target vector.
There are many ways to measure vector distance, such as Euclidean distance:
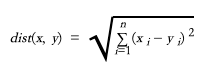 1-euclidean-distance.png
1-euclidean-distance.png
where x and y are two vectors. n is the dimension of the vectors.
In order to find K nearest vectors in a dataset, Euclidean distance needs to be computed between the target vector and all vectors in the dataset to be searched. Then, vectors are sorted by distance to acquire K nearest vectors. The computational work is in direct proportion to the size of the dataset. The larger the dataset, the more computational work a query requires. A GPU, specialized for graph processing, happens to have a lot of cores to provide the required computing power. Thus, multi-GPU support is also taken into consideration during Milvus implementation.
Basic concepts
Data block(TableFile)
To improve support for massive-scale data search, we optimized the data storage of Milvus. Milvus splits the data in a table by size into multiple data blocks. During vector search, Milvus searches vectors in each data block and merges the results. One vector search operation consists of N independent vector search operations (N is the number of data blocks) and N-1 result merge operations.
Task queue(TaskTable)
Each Resource has a task array, which records tasks belonging to the Resource. Each task has different states, including Start, Loading, Loaded, Executing, and Executed. The Loader and Executor in a computing device share the same task queue.
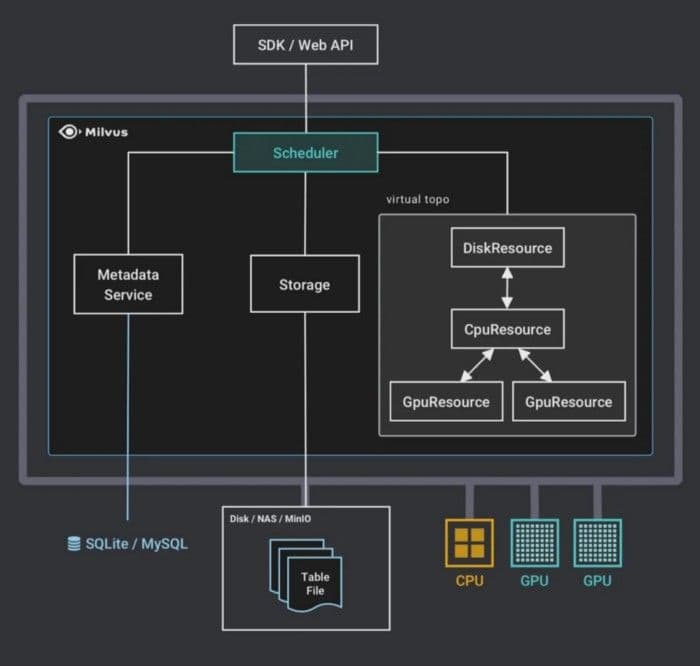
Query scheduling
 2-query-scheduling.png
2-query-scheduling.png
- When the Milvus server starts, Milvus launches the corresponding GpuResource via the
gpu_resource_configparameters in theserver_config.yamlconfiguration file. DiskResource and CpuResource still cannot be edited inserver_config.yaml. GpuResource is the combination ofsearch_resourcesandbuild_index_resourcesand referred to as{gpu0, gpu1}in the following example:
 3-sample-code.png
3-sample-code.png
 3-example.png
3-example.png
- Milvus receives a request. Table metadata is stored in an external database, which is SQLite or MySQl for single-host and MySQL for distributed. After receiving a search request, Milvus validates whether the table exists and the dimension is consistent. Then, Milvus reads the TableFile list of the table.
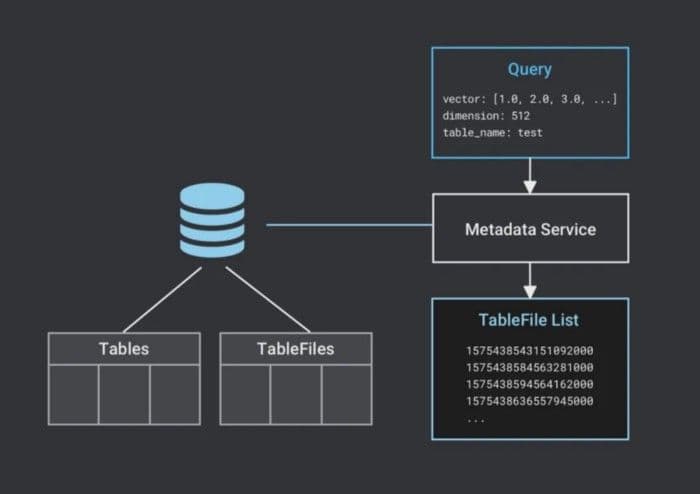 4-milvus-reads-tablefile-list.png
4-milvus-reads-tablefile-list.png
- Milvus creates a SearchTask. Because the computation of each TableFile is performed independently, Milvus creates a SearchTask for each TableFile. As the basic unit of task scheduling, a SearchTask contains the target vectors, search parameters, and the filenames of TableFile.
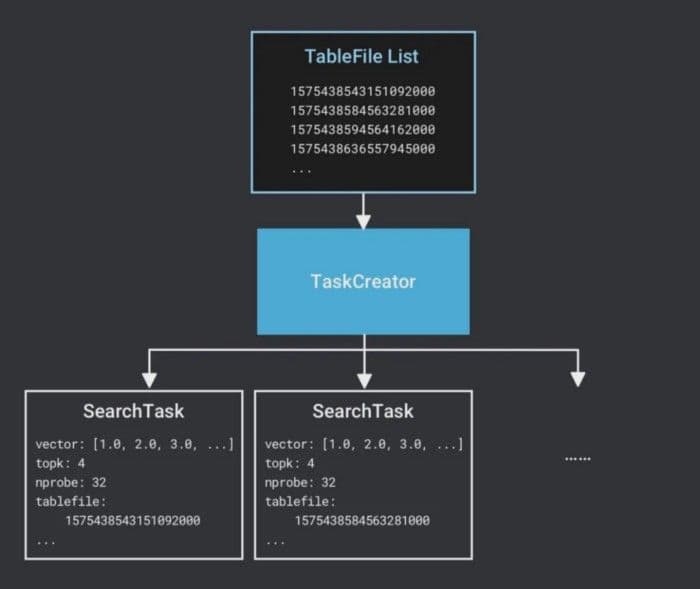 5-table-file-list-task-creator.png
5-table-file-list-task-creator.png
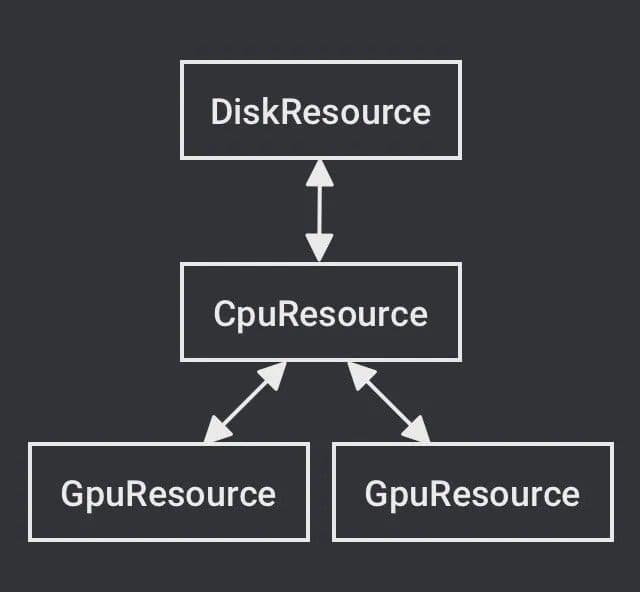
- Milvus chooses a computing device. The device that a SearchTask performs computation depends on the estimated completion time for each device. The estimated completion time specifies the estimated interval between the current time and the estimated time when the computation completes.
For example, when a data block of a SearchTask is loaded to CPU memory, the next SearchTask is waiting in the CPU computation task queue and the GPU computation task queue is idle. The estimated completion time for CPU is equal to the sum of the estimated time cost of the previous SearchTask and the current SearchTask. The estimated completion time for a GPU is equal to the sum of the time for data blocks to be loaded to the GPU and the estimated time cost of the current SearchTask. The estimated completion time for a SearchTask in a Resource is equal to the average execution time of all SearchTasks in the Resource. Milvus then chooses a device with the least estimated completion time and assign SearchTask to the device.
Here we assume that the estimated completion time for GPU1 is shorter.
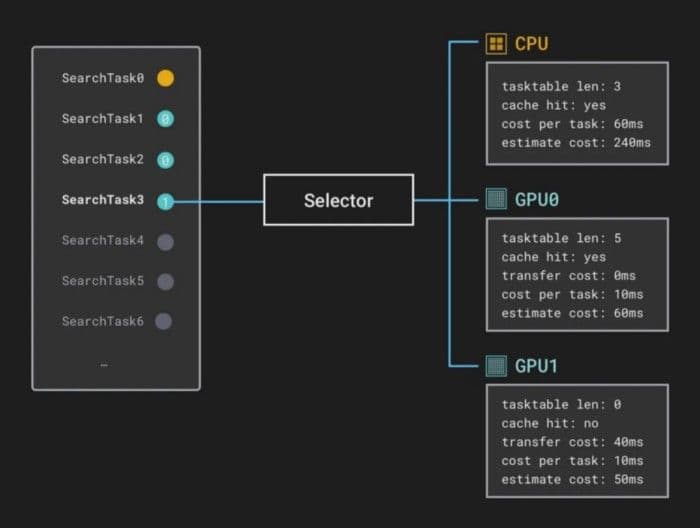 6-GPU1-shorter-estimated-completion-time.png
6-GPU1-shorter-estimated-completion-time.png
Milvus adds SearchTask to the task queue of DiskResource.
Milvus moves SearchTask to the task queue of CpuResource. The loading thread in CpuResource loads each task from the task queue sequentially. CpuResource reads the corresponding data blocks to CPU memory.
Milvus moves SearchTask to GpuResource. The loading thread in GpuResource copies data from CPU memory to GPU memory. GpuResource reads the corresponding data blocks to GPU memory.
Milvus executes SearchTask in GpuResource. Because the result of a SearchTask is relatively small, the result is directly returned to CPU memory.
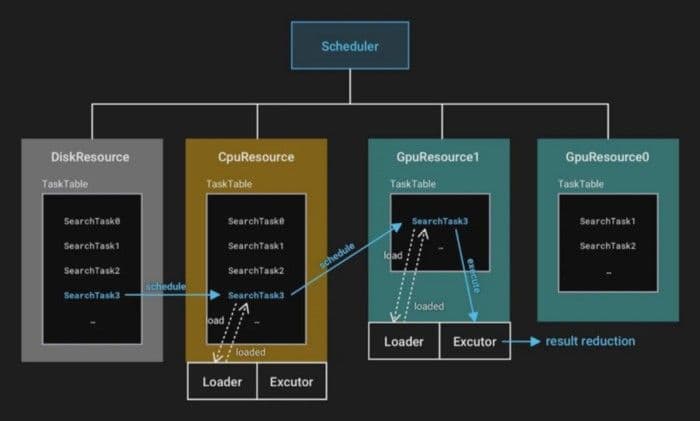 7-scheduler.png
7-scheduler.png
- Milvus merges the result of SearchTask to the whole search result.
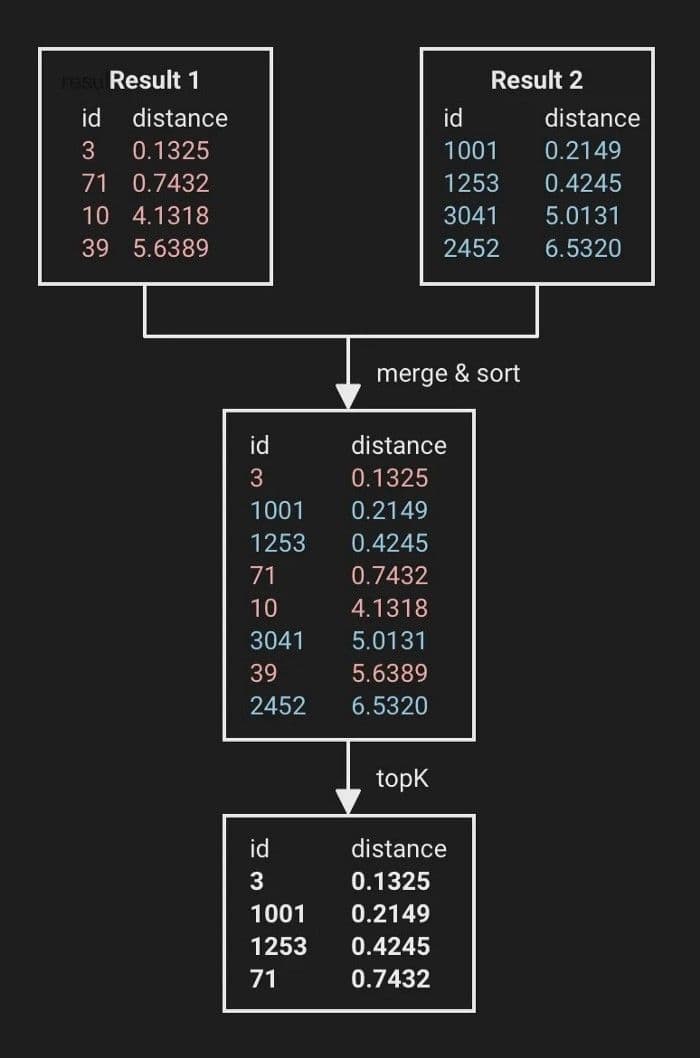 8-milvus-merges-searchtast-result.png
8-milvus-merges-searchtast-result.png
After all SearchTasks are complete, Milvus returns the whole search result to the client.
Index building
Index building is basically the same as the search process without the merging process. We will not talk about this in detail.
Performance optimization
Cache
As mentioned before, data blocks need to be loaded to corresponding storage devices such as CPU memory or GPU memory before computation. To avoid repetitive data loading, Milvus introduces LRU (Least Recently Used) cache. When the cache is full, new data blocks push away old data blocks. You can customize the cache size by the configuration file based on the current memory size. A large cache to store search data is recommended to effectively save data loading time and improve search performance.
Data loading and computation overlap
The cache cannot satisfy our needs for better search performance. Data needs to be reloaded when memory is insufficient or the size of the dataset is too large. We need to decrease the effect of data loading on search performance. Data loading, whether it be from disk to CPU memory or from CPU memory to GPU memory, belongs to IO operations and barely needs any computational work from processors. So, we consider performing data loading and computation in parallel for better resource usage.
We split the computation on a data block into 3 stages (loading from disk to CPU memory, CPU computation, result merging) or 4 stages (loading from disk to CPU memory, loading from CPU memory to GPU memory, GPU computation and result retrieval, and result merging). Take 3-stage computation as an example, we can launch 3 threads responsible for the 3 stages to function as instruction pipelining. Because the results sets are mostly small, result merging does not take much time. In some cases, the overlap of data loading and computation can reduce the search time by 1/2.
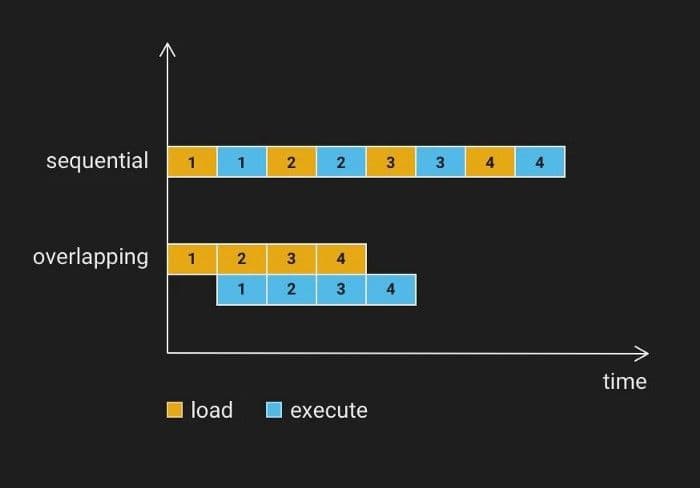 9-sequential-overlapping-load-milvus.png
9-sequential-overlapping-load-milvus.png
Problems and solutions
Different transmission speeds
Previously, Milvus uses the Round Robin strategy for multi-GPU task scheduling. This strategy worked perfectly in our 4-GPU server and the search performance was 4 times better. However, for our 2-GPU hosts, the performance was not 2 times better. We did some experiments and discovered that the data copy speed for a GPU was 11 GB/s. However, for another GPU, it was 3 GB/s. After referring to the mainboard documentation, we confirmed that the mainboard was connected to one GPU via PCIe x16 and another GPU via PCIe x4. That is to say, these GPUs have different copy speeds. Later, we added copy time to measure the optimal device for each SearchTask.
Future work
Hardware environment with increased complexity
In real conditions, the hardware environment may be more complicated. For hardware environments with multiple CPUs, memory with NUMA architecture, NVLink, and NVSwitch, communication across CPUs/GPUs brings a lot of opportunities for optimization.
Query optimization
During experimentation, we discovered some opportunities for performance improvement. For example, when the server receives multiple queries for the same table, the queries can be merged under some conditions. By using data locality, we can improve the performance. These optimizations will be implemented in our future development. Now we already know how queries are scheduled and performed for the single-host, multi-GPU scenario. We will continue to introduce more inner mechanisms for Milvus in the upcoming articles.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word